






脚本
#!/bin/bash
# 检查是否提供了两个文件名
if [ $# -ne 2 ]; then
echo "用法: $0 file1 file2"
exit 1
fi
file1="$1"
file2="$2"
# 比较文件内容
line_number1=0
while IFS= read -r line1; do
line_number1=$((line_number1 + 1))
line_number2=0
while IFS= read -r line2; do
line_number2=$((line_number2 + 1))
for (( i = 0; i < ${#line1} - 1; i++ )); do
for (( j = 0; j < ${#line2} - 1; j++ )); do
if [[ "${line1:$i:2}" == "${line2:$j:2}" ]]; then # ${line1:$i:2}分段可以按需设置,如果想看连续3个字符相同2换成3
echo "在文件 $file1 的第 $line_number1 行和文件 $file2 的第 $line_number2 行中找到重复的连续字符: ${line1:$i:2}"
fi
done
done
done < "$file2"
done < "$file1"
- 添加行号变量:
line_number1和line_number2用来分别跟踪file1和file2的当前行号。 - 行号递增:每次读取新的一行时,相应的行号变量加1 (
line_number1=$((line_number1 + 1))和line_number2=$((line_number2 + 1)))。 - 在输出中显示行号:在输出结果中添加了行号信息,使得每次找到重复的连续字符时,能够打印出在两个文件中具体的行号。
效果
测试文件入下
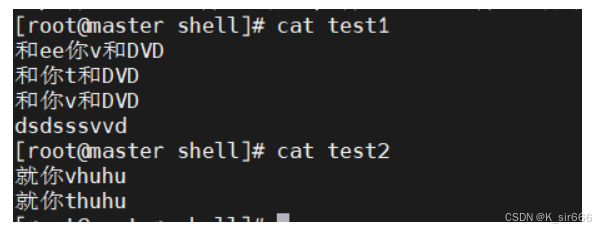
-
不加参数

-
加测试文件

运行这个脚本时,它会递归比对并输出在两个文件中发现的重复连续字符及其所在的行号。


















 3794
3794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









