



深入浅出消息队列 (RabbitMQ)
1. 前言
在分布式系统中,消息队列 (Message Queue, MQ) 经常被用来实现异步解耦、流量削峰等功能。它能够让系统在高并发环境下更具弹性,并且在各个模块之间实现“松耦合”的交互。
- 什么是消息队列?
消息队列是指在消息传输过程中保存消息的容器,可以帮助不同进程/应用之间异步通信。 - 你可以把消息队列想象成一个“菜鸟驿站”。就像你网购时,快递先送到驿站,你再去取货一样,消息队列里先存储消息,等消费者来“取走”处理。这样,生产消息的部分(就像快递员)和处理消息的部分(就像取快递的人)就不会因为时间不匹配而互相拖累。简单来说,菜鸟驿站帮助解决快递和取件的时差问题,消息队列则解决了系统中生产和消费的速度差异问题。
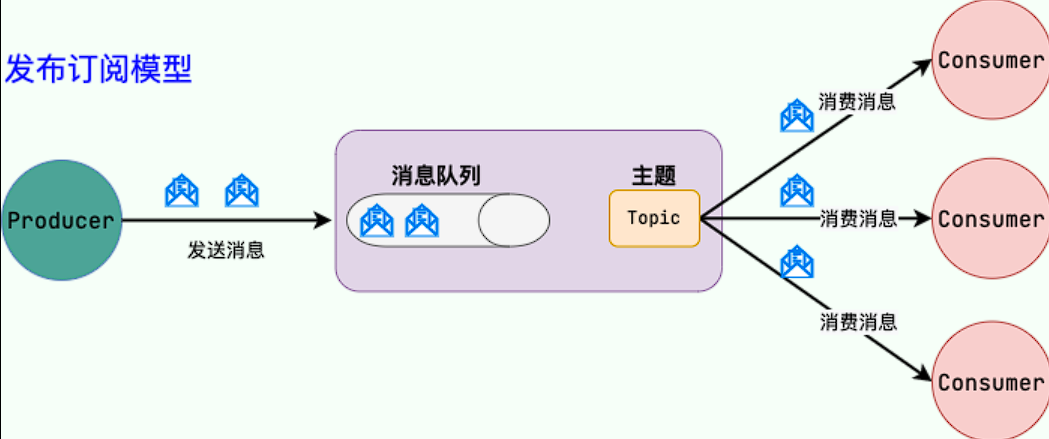
- 为什么要使用消息队列?
- 系统解耦:生产者和消费者不必直接调用。
- 异步处理:生产者把任务丢到队列即可,后续由消费者异步执行。
- 流量削峰:将突发的请求平滑化处理,防止服务被压垮。
- 数据分发:在分布式环境中,能快速地把数据分发给不同的消费者。
2. MQ 的基本概念
-
异步调用方式其实就是基于消息通知的方式,一般包含三个角色:
- 消息发送者:投递消息的人,就是原来的调用方
- 消息Broker:管理、暂存、转发消息,你可以把它理解成微信服务器
- 消息接收者:接收和处理消息的人,就是原来的服务提供方
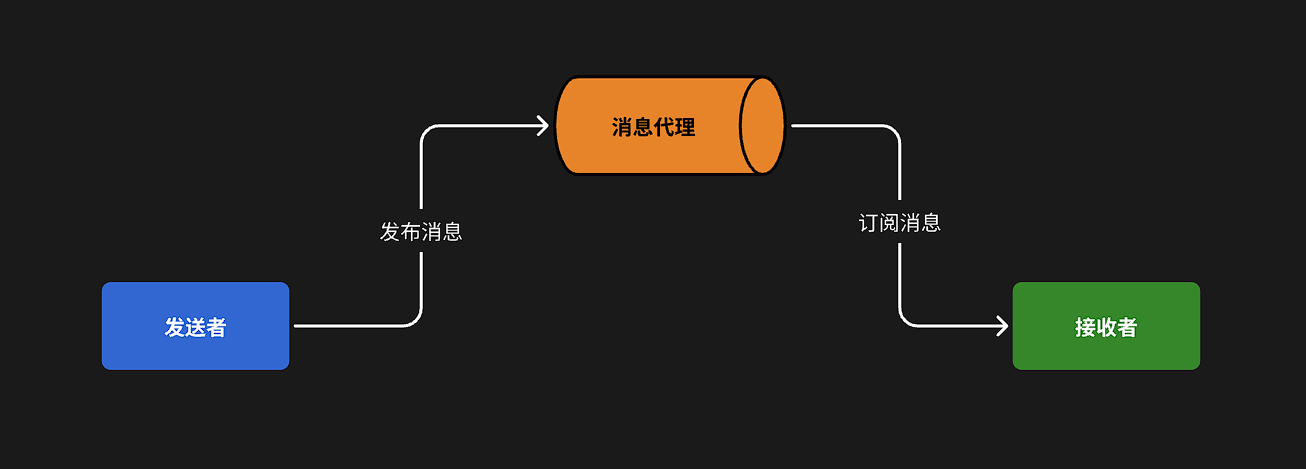
在异步调用中,发送者不再直接同步调用接收者的业务接口,而是发送一条消息投递给消息Broker。然后接收者根据自己的需求从消息Broker那里订阅消息。每当发送方发送消息后,接受者都能获取消息并处理。
这样,发送消息的人和接收消息的人就完全解耦了。
消息Broker,目前常见的实现方案就是消息队列(MessageQueue),简称为MQ.
3. 常见的消息队列实现
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
**追求可用性:**Kafka、 RocketMQ 、RabbitMQ
**追求可靠性:**RabbitMQ、RocketMQ
**追求吞吐能力:**RocketMQ、Kafka
**追求消息低延迟:**RabbitMQ、Kafka
4. 消息队列的使用场景
4.1异步处理
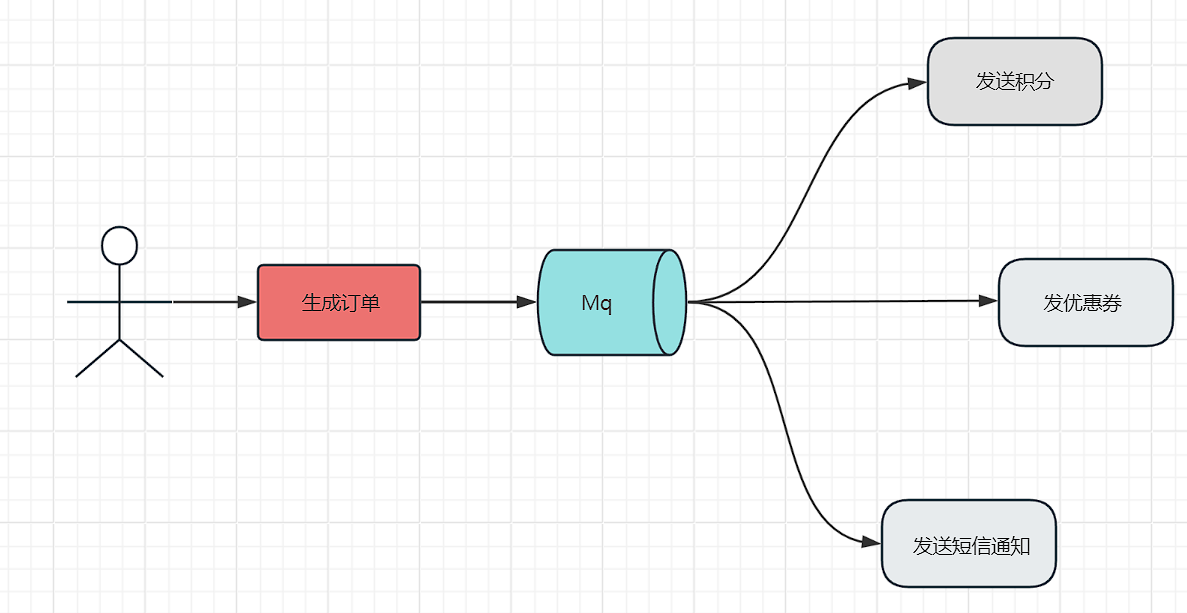
如果没有引入MQ进行架构改造,每次支付成功后的大量同步接口调用,耗时大,通过引入MQ,当更新完订单状态和扣减成功库存后,就发一条“支付成功”消息到MQ中,然后立即返回。而信息、积分、优惠券系统会订阅MQ中的该类消息,它们收到通知后就会去异步处理。整个系统的响应时间可以大大缩短,
4.2 削峰/限流。
先将短时间高并发产生的事务消息存储在消息队列中,然后后端服务再慢慢根据自己的能力去消费这些消息,这样就避免直接把后端服务打垮掉。
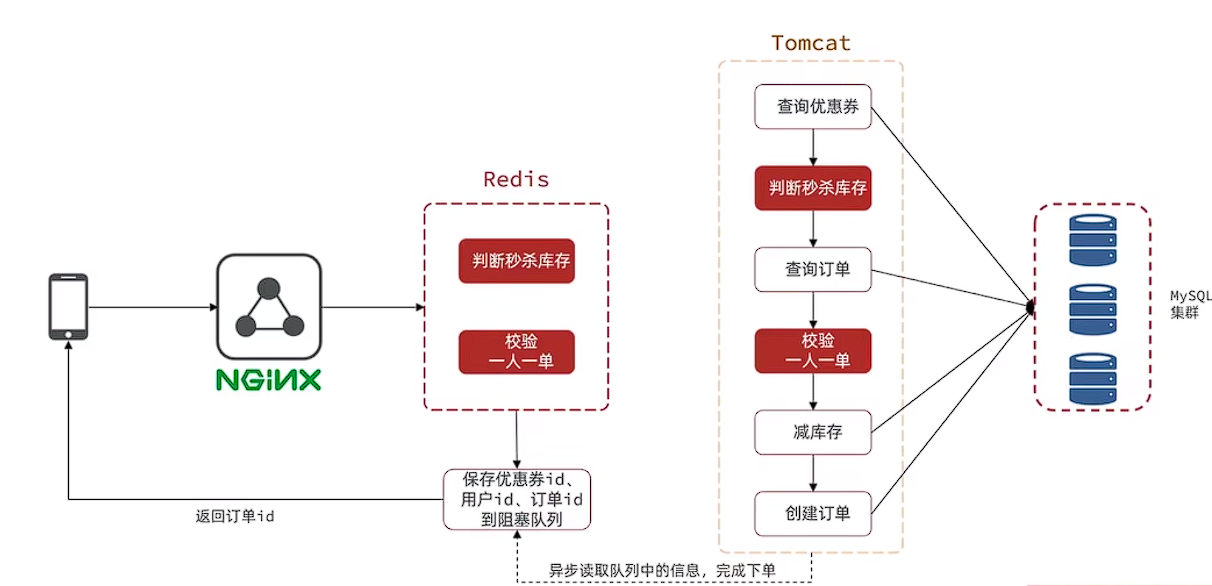
像之前黑马点评项目中的异步秒杀下单,判断库存,检验一人一单,只要满足这两个条件就一定可以下单成功,不用等数据真的写进数据库中,可以直接告诉用户下单成功,只需要将订单id等信息引入异步队列记录,后台再开一个线程慢慢去执行队列中的消息就行,有效提高效率。
4.3 解耦
解耦和异步是同生同源的,我们经过上述的异步化改造后,自然而然的就已经将各个系统解耦出去了,可以在多个系统之间进行解耦,将原本通过网络之间的调用的方式改为使用MQ进行消息的异步通讯,只要该操作不是需要同步的,就可以改为使用MQ进行不同系统之间的联系,这样项目之间不会存在耦合,系统之间不会产生太大的影响,就算一个系统挂了,也只是消息挤压在MQ里面没人进行消费而已,不会对其他的系统产生影响 -site:*.youkuaiyun.com
5. 示例:如何简单使用 RabbitMQ
安装与配置
- RabbitMQ 官方下载
- 安装后可通过管理控制台查看队列状态。
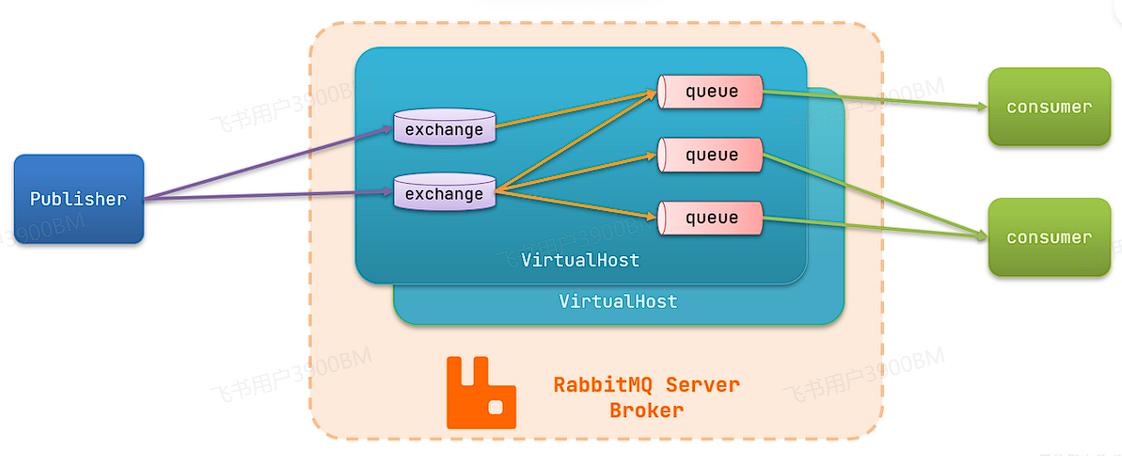
publisher:生产者,也就是发送消息的一方consumer:消费者,也就是消费消息的一方queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
WorkQueues模型
Work queues,任务模型。简单来说就是让多个消费者 绑定到一个队列,共同消费队列中的消息。
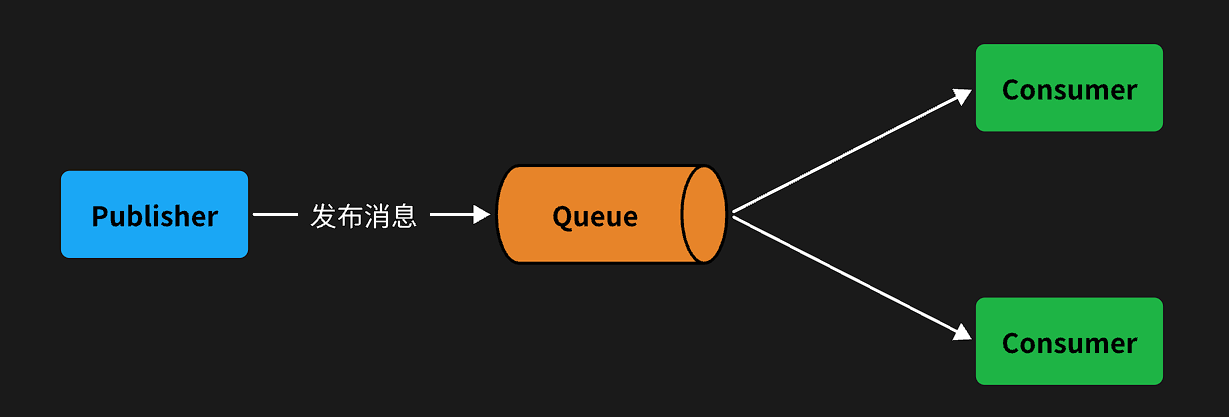
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
交换机类型
没有交换机,生产者直接发送消息到队列。而一旦引入交换机,消息发送的模式会有很大变化:
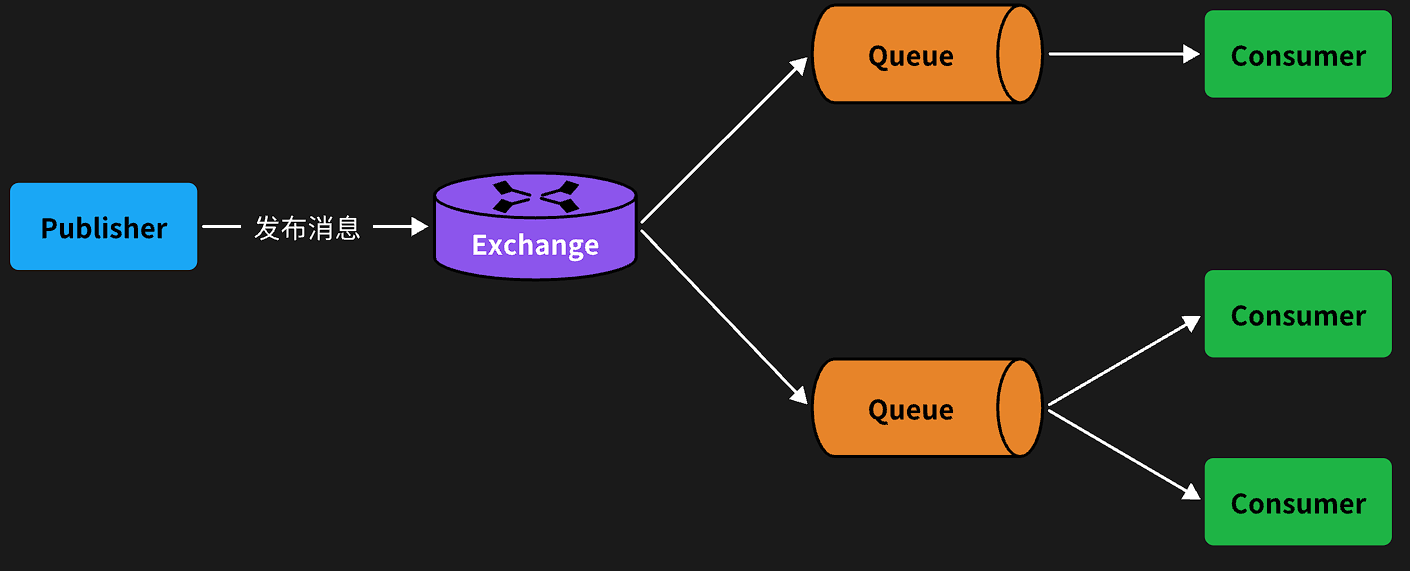
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
- Publisher:生产者,不再发送消息到队列中,而是发给交换机
- Exchange:交换机,一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
- Queue:消息队列也与以前一样,接收消息、缓存消息。不过队列一定要与交换机绑定。
- Consumer:消费者,与以前一样,订阅队列,没有变化
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
交换机的类型有四种:
- Fanout:广播,将消息交给所有绑定到交换机的队列。我们最早在控制台使用的正是Fanout交换机
- Direct:订阅,基于RoutingKey(路由key)发送给订阅了消息的队列
- Topic:通配符订阅,与Direct类似,只不过RoutingKey可以使用通配符
- Headers:头匹配,基于MQ的消息头匹配,用的较少。
第一步,配置pom包。
创建Spring Boot项目并在pom.xml文件中添加spring-bootstarter-amqp等相关组件依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
在上面的示例中,引入Spring Boot自带的amqp组件spring-bootstarter-amqp。
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消
第二步,修改配置文件。
修改application.yml配置文件,配置rabbitmq的host地址、端口以及账户信息。
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
声明队列和交换机
基于API由程序启动时检查队列和交换机是否存在,如果不存在自动创建
创建一个类,声明队列和交换机
fanout示例
package com.itheima.consumer.config;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.FanoutExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FanoutConfig {
/**
* 声明交换机
* @return Fanout类型交换机
*/
@Bean
public FanoutExchange fanoutExchange(){
return new FanoutExchange("hmall.fanout");
}
/**
* 第1个队列
*/
@Bean
public Queue fanoutQueue1(){
return new Queue("fanout.queue1");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
/**
* 第2个队列
*/
@Bean
public Queue fanoutQueue2(){
return new Queue("fanout.queue2");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}
direct示例
direct模式由于要绑定多个KEY,会非常麻烦,每一个Key都要编写一个binding:
package com.itheima.consumer.config;
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class DirectConfig {
/**
* 声明交换机
* @return Direct类型交换机
*/
@Bean
public DirectExchange directExchange(){
return ExchangeBuilder.directExchange("hmall.direct").build();
}
/**
* 第1个队列
*/
@Bean
public Queue directQueue1(){
return new Queue("direct.queue1");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue1WithRed(Queue directQueue1, DirectExchange directExchange){
return BindingBuilder.bind(directQueue1).to(directExchange).with("red");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue1WithBlue(Queue directQueue1, DirectExchange directExchange){
return BindingBuilder.bind(directQueue1).to(directExchange).with("blue");
}
/**
* 第2个队列
*/
@Bean
public Queue directQueue2(){
return new Queue("direct.queue2");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue2WithRed(Queue directQueue2, DirectExchange directExchange){
return BindingBuilder.bind(directQueue2).to(directExchange).with("red");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue2WithYellow(Queue directQueue2, DirectExchange directExchange){
return BindingBuilder.bind(directQueue2).to(directExchange).with("yellow");
}
}
基于注解声明
基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。
例如,我们同样声明Direct模式的交换机和队列:
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue1(String msg){
System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT),
key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg){
System.out.println("消费者2接收到direct.queue2的消息:【" + msg + "】");
}
Topic模式:
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue1"),
exchange = @Exchange(name = "hmall.topic", type = ExchangeTypes.TOPIC),
key = "china.#"
))
public void listenTopicQueue1(String msg){
System.out.println("消费者1接收到topic.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue2"),
exchange = @Exchange(name = "hmall.topic", type = ExchangeTypes.TOPIC),
key = "#.news"
))
public void listenTopicQueue2(String msg){
System.out.println("消费者2接收到topic.queue2的消息:【" + msg + "】");
}
消息转换器
默认转换器

Spring的消息发送代码接收的消息体是一个Object:而在数据传输时,它会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。只不过,默认情况下Spring采用的序列化方式是JDK序列化。
JDK序列化存在下列问题:
- 数据体积过大
- 有安全漏洞
- 可读性差
配置JSON转换器
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化
启动类中添加一个Bean即可
@Bean
public MessageConverter messageConverter(){
// 1.定义消息转换器
Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter();
// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息
jackson2JsonMessageConverter.setCreateMessageIds(true);
return jackson2JsonMessageConverter;
}
消费者接收Object
我们定义一个新的消费者,publisher是用Map发送,那么消费者也一定要用Map接收,格式如下:
@RabbitListener(queues = "object.queue")
public void listenSimpleQueueMessage(Map<String, Object> msg) throws InterruptedException {
System.out.println("消费者接收到object.queue消息:【" + msg + "】");
}
6.如何在 RabbitMQ 中保证消息不丢失
需要从生产端、MQ 服务端、消费端三个环节分别做好保障,具体如下:
- 生产端保障
- 开启消息确认机制(publisher confirm):生产者发送消息后,RabbitMQ 会在消息成功投递到交换机并路由到队列后,返回一个确认信号(ack);若投递失败(如交换机不存在、路由键错误),则返回否定确认(nack)。生产者可通过监听确认信号,对失败的消息进行重试,避免消息在发送环节丢失。
- 避免消息在内存中积压:可通过设置合理的重试机制(如有限次数重试 + 死信队列),防止因网络波动等临时问题导致消息发送失败后无法恢复。
- MQ 服务端保障
- 交换机持久化:创建交换机时指定
durable=true,确保 MQ 重启后交换机不会丢失,否则消息可能因交换机不存在而投递失败。 - 队列持久化:创建队列时同样指定
durable=true,保证队列在 MQ 重启后依然存在,避免队列丢失导致消息无处存储。 - 消息持久化:发送消息时设置
deliveryMode=2,使消息被持久化到磁盘(默认是内存存储),即使 MQ 宕机,重启后可从磁盘恢复消息。 - 合理配置刷盘策略:RabbitMQ 默认采用 “异步刷盘”(消息先存内存,定时批量刷盘),若需极致可靠性,可配置为 “同步刷盘”(消息写入即刷盘),但会牺牲部分性能。
- 交换机持久化:创建交换机时指定
- 消费端保障
- 关闭自动 ACK,采用手动 ACK:消费端通过
channel.basicConsume指定autoAck=false,在消息完全处理完成后(如业务逻辑执行成功、数据入库等),手动调用channel.basicAck发送确认信号。 - 避免提前 ACK:若消费端拿到消息后未处理完就崩溃,手动 ACK 机制会让消息保留在队列中,等待其他消费者重新消费;若使用自动 ACK,消息会被立即标记为 “已消费” 并删除,导致未处理的消息丢失。
- 处理消费异常:若消费过程中出现异常(如业务失败),可通过
basicNack或basicReject拒绝消息,并根据需求决定是否将消息重新入队或转发到死信队列,避免消息被误删。
- 关闭自动 ACK,采用手动 ACK:消费端通过
通过以上三个环节的配合,可最大程度确保消息在 RabbitMQ 中不丢失,核心是 “确认机制 + 持久化 + 手动控制消费确认”。
7.遇到 “消息积压” 的问题。比如,当消费者处理速度远低于生产者发送消息的速度时,队列中的消息会越积越多。
需要从 “紧急处理积压” 和 “长期避免积压” 两个层面入手,具体方案如下:
一、紧急处理:快速消化积压消息
- 临时扩容消费能力
- 增加消费者实例:通过水平扩容(部署更多消费端服务),利用 RabbitMQ 的轮询分发机制,让多个消费者并行处理同一队列的消息,直接提升消费速率。
- 调整消费者预取数:默认情况下,RabbitMQ 会将消息平均分配给消费者,若消息大小 / 处理耗时不均,可通过
channel.basicQos(prefetchCount)设置预取数(如prefetchCount=1),确保一个消费者处理完当前消息后再获取下一个,避免 “忙的太忙、闲的太闲”。 - 简化消费逻辑:临时去掉非核心业务(如日志、统计),只保留必要处理步骤,减少单条消息的处理耗时。
- 分流消息,优先处理新消息
- 若积压严重且新消息持续涌入,可临时创建 “备用队列” 和对应的交换机,通过修改生产者路由策略,将新消息路由到备用队列,由正常消费者处理;原队列的积压消息由专门的 “清理消费者”(逻辑简化,甚至仅做数据归档)慢慢处理,避免新消息被积压阻塞。
- 处理完积压后,再切换路由策略,让新消息回到原队列,恢复正常流程。
- 避免积压期间消息丢失
- 确保队列和消息已开启持久化(
durable=true、deliveryMode=2),即使 MQ 重启,积压消息也能从磁盘恢复。 - 关闭消费端自动 ACK,采用手动 ACK,避免消费者崩溃导致消息被误删(确保消息处理完成后再发送 ACK)。
- 确保队列和消息已开启持久化(
二、长期优化:避免再次积压
- 生产端限流
- 若生产者发送速率远超消费能力,可在生产端添加限流机制(如基于令牌桶算法),控制消息发送频率,避免 “生产爆炸式增长”。
- 结合 MQ 的
channel.flow(false)机制,当 MQ 队列长度达到阈值时,通知生产者暂停发送,待队列消息减少后再恢复。
- 消费端性能优化
- 优化业务逻辑:通过异步处理、批量操作(如批量写入数据库)减少单条消息的处理耗时。
- 引入线程池:在消费端内部使用线程池并行处理消息(需注意线程安全),提升单实例的处理能力。
- 监控与告警
- 实时监控队列长度、消息堆积速率,设置阈值告警(如队列消息数超过 10 万条时触发告警),及时发现并处理积压风险。
- 定期压测,评估生产 / 消费的峰值能力,提前扩容资源(如在流量高峰期前增加消费者实例)。
- 死信队列兜底
- 为原队列配置死信队列(DLX),若消息处理多次失败(如消费端持续异常),自动路由到死信队列,避免失败消息长期占用队列资源,后续可人工处理死信消息。
核心逻辑:短期通过 “扩容消费 + 分流消息” 快速减负,长期通过 “速率匹配 + 监控优化” 避免积压,同时全程依赖 MQ 自身的持久化和确认机制保障消息不丢失,减少对外部存储的依赖(除非特殊场景)。


















 9747
9747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











