



缓存穿透解决方案之「布隆过滤器」
应用场景 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)
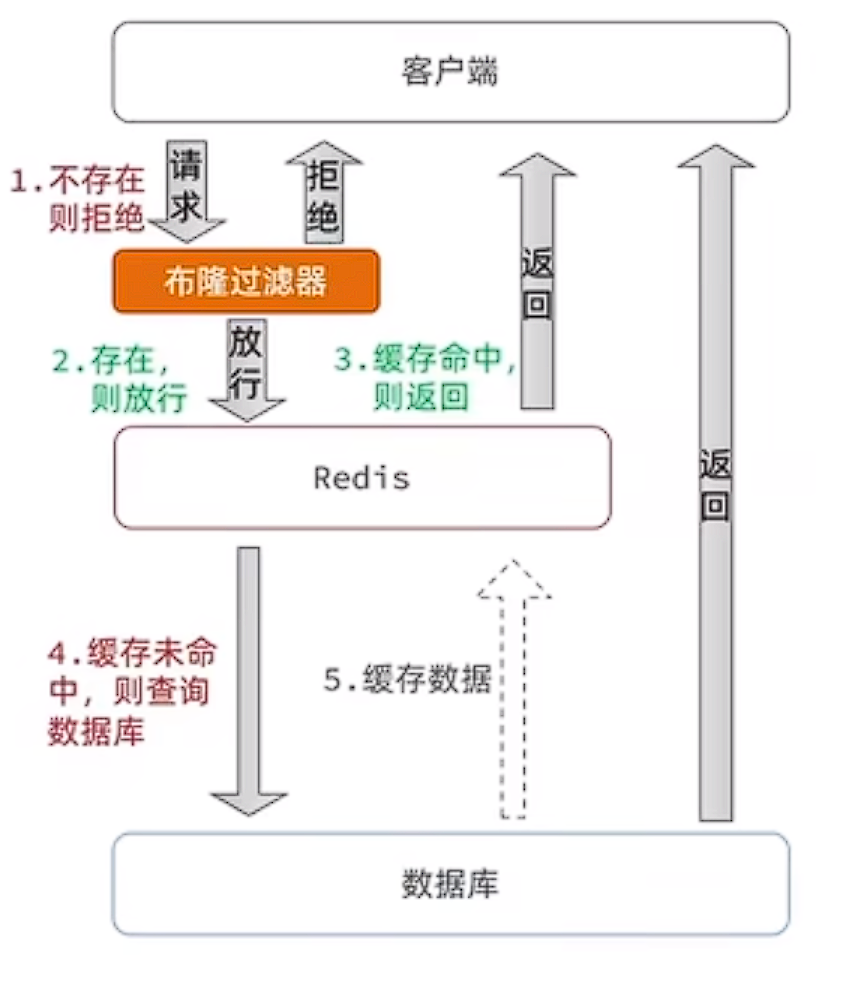
为了避免缓存穿透我们需要缓存预热将要查询数据的id提前存入布隆过滤器,添加数据时将信息的id也存入过滤器,当去查询一个数据时先在布隆过滤器中找一下如果没有到到就说明不存在,此时直接返回。
在我们的电商系统中,使用布隆过滤器后,数据库查询量减少了75%,因为我们在查询数据库前先用布隆过滤器过滤掉90%的不存在ID
具体数据结构
主要由两部分组成:位数组+n个哈希函数
- 位数组
- 一个长度为m的二进制向量(所有位初始为0)
- 每个位只占用1 bit空间,因此非常节省内存
- 例如:一个长度为1000的位数组,只需要125字节(1000/8)的内存
- n个哈希函数
- 一组彼此独立且均匀分布的哈希函数
- 通常使用3-7个哈希函数(具体数量根据需求调整)
- 这些哈希函数将输入元素映射到位数组的多个位置
布隆过滤器的"高效"就来自于这种简单结构:
- 位数组:节省空间(比哈希表节省90%+的空间)
- 多个哈希函数:如果只用一个哈希函数,那么当某个位被置为1时,就可能被误判为元素存在,误判率会非常高,因为位数组中的每个位可能被多个元素共享。使用多个哈希函数可以显著降低误判率,因为需要多个位置同时被置为1才能误判。
🎯 这里引用的是 JavaGuide 的文章。
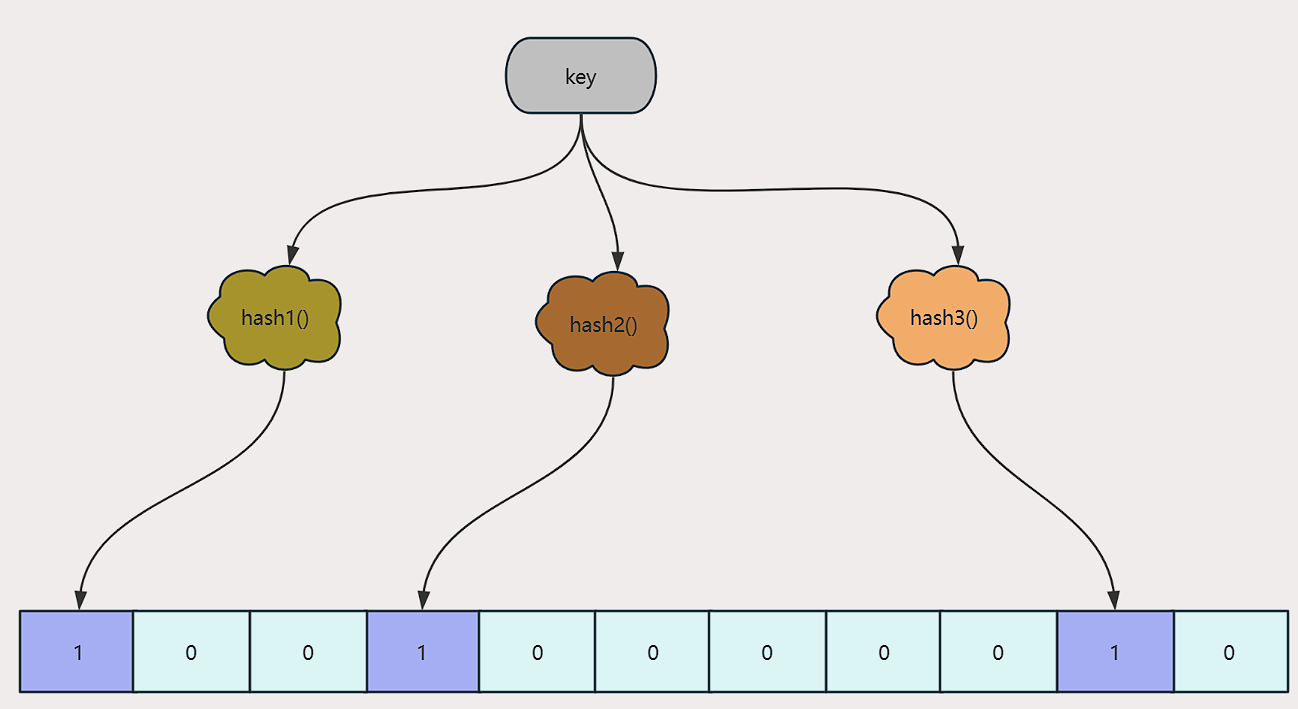
当一个元素加入布隆过滤器中的时候,会进行如下操作:
1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
1. 对给定元素再次进行相同的哈希计算;
2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1, 说明该元素不在布隆过滤器中。
不同的数据可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
如何优化
- 增加位数组大小:减少误判率,但会增加内存。
- 选择合适的哈希函数的数量:平衡误判率。


















 3086
3086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











