







目录
S8.2深度学习框架Deep Learning Frameworks
S8.1CPU vs GPU
CPU是中央处理器。GPU是图像处理单元或者图形卡,最初用于对计算机图形进行渲染,特别是游戏视频等等。CPU和GPU都是通用的计算机器,它们可以执行任何指令。CPU的核数少于GPU的核数,但两者的核不能进行简单地数字比较。CPU的核能够单独运行,而GPU的核是需要相互协作。CPU对于一般的处理是足够的,可以做各种各样的事情,而GPU更擅长处理高度并行处理的算法,例如矩阵乘法和卷积操作。这里给出两个英特尔CPU和两个先进的GPU的相关信息,如下图所示:
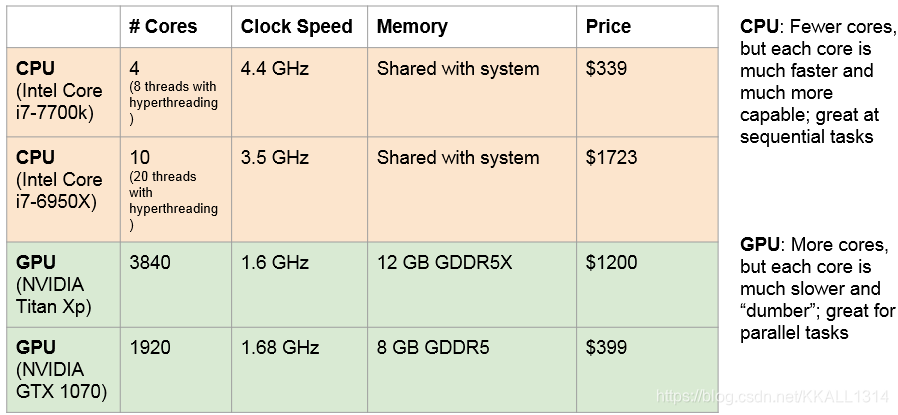
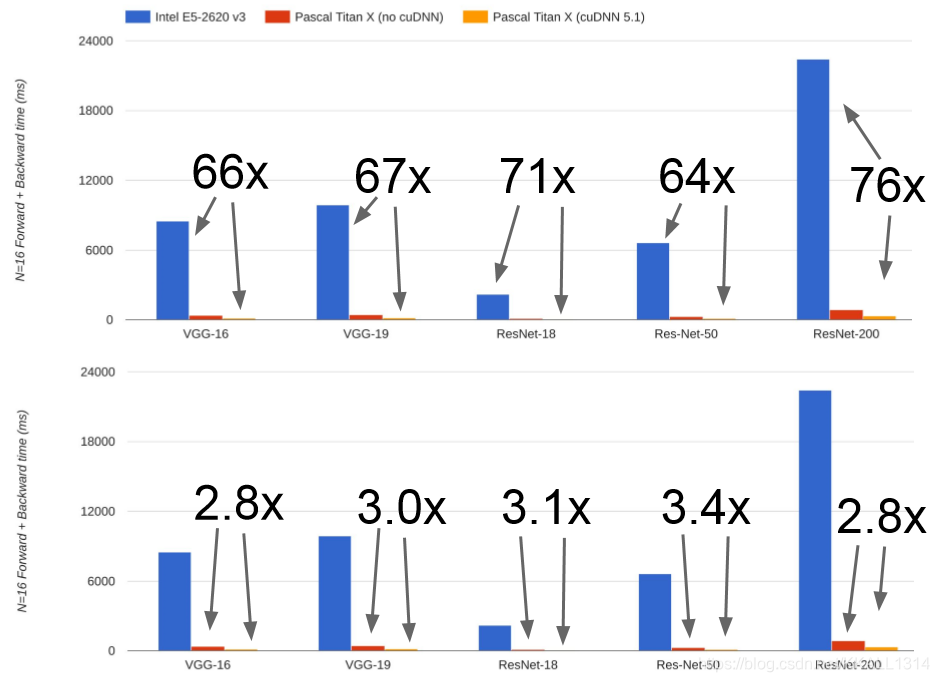
图形卡有NVIDIA和AMD。在深度学习中,NIVDIA占据主导地位。下图给出了CPU和GPU在实际中的性能比较。首先是CPU和优化后的GPU的比较,接着是优化前和优化后的GPU比较。我们可以看出:优化后的GPU速度是CPU速度的66-76倍。但这里没有对CPU的性能进行提升,可能对CPU有些不公平;优化后的GPU的性能大约是未优化的3倍,所以最好使用CUDA来充分利用GPU。CUDA仅仅对NVIDIA有用,提供了更高级的API,如 cuBLAS,cuFFT,cuDNN等等 。
S8.2深度学习框架Deep Learning Frameworks
使用深度学习框架有三个好处,首先易于构建大型的计算图,其次容易计算图的梯度,最后能够充分使用GPU来进行模型训练。Numpy使用CPU运行的,速度很慢。深度学习框架有很多,如TensorFlow,Pytorch,Theano,Keras等等。TensorFlow是Google开发的,是一个通用的深度学习框架。Pytorch和Caffe2是Facebook公司的,Pytorch面向科研,Caffe2面向产品。下表是一些深度框架的官网和预训练模型:
TensorFlow和PyTorch都提供了可视化工具:
| 模型 | 可视化工具 | 网站 |
|---|---|---|
| TensorFlow | Tensorboard | https://github.com/tensorflow/tensorboard/ |
| PyTorch | Visdom | https://github.com/facebookresearch/visdom |
下面是使用这些框架的一点建议:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









