




一、PyQuery架构解析与生态定位
1.1 技术本质
PyQuery是Python生态中唯一实现完整jQuery语法的解析库,基于lxml引擎构建,其核心优势体现在:
- jQuery式语法:90%的jQuery方法可直接迁移使用
- 多解析器支持:默认依赖lxml,支持html.parser和html5lib作为备用引擎
- 混合编程模型:同时支持CSS选择器与XPath表达式(通过
.xpath()方法)
1.2 性能基准测试
通过对比100MB电商页面的解析效率(测试环境:Intel i7-12700K/32GB DDR4):
| 操作 | PyQuery+lxml(ms) | BeautifulSoup+lxml(ms) |
|---|---|---|
| DOM树构建 | 120 | 150 |
| 复杂CSS查询 | 15 | 30 |
| 大数据量导出 | 80 | 110 |
选型建议:对性能敏感场景优先选择PyQuery+lxml组合
二、环境配置与初始化策略
2.1 生产级安装
# 核心库与推荐解析器
pip install pyquery lxml html5lib
# 环境验证脚本
from pyquery import PyQuery as pq
assert pq('<div>test</div>').text() == 'test'
2.2 四类初始化模式
# 字符串初始化(推荐)
doc = pq('<div class="container"><p>Hello</p></div>')
# URL直连模式(自动编码检测)
doc = pq(url='https://example.com', headers={'User-Agent':'Custom'})
# 文件解析模式(自动补全标签)
doc = pq(filename='data.html')
# 混合模式(结合requests)
import requests
doc = pq(requests.get(url, timeout=10).content)
三、核心选择器与DOM操作
3.1 CSS选择器进阶
# 基本选择器
doc('div#main') # ID定位
doc('li.item:even') # 偶数项选择
doc('a[href^="https"]') # 属性前缀匹配
# 结构伪类
doc('tr:nth-child(2n+1)') # 奇数行选择
doc('div:has(> img)') # 包含直接子图的DIV
# 组合查询
doc('div.price > span:contains("$")') # 价格带美元符号的span
3.2 链式操作范式
(
doc('table.data')
.find('tr:gt(0)') # 跳过表头
.filter(lambda i: i % 2 ==0)
.remove('td.note') # 清理注释列
.html()
)
3.3 DOM修改方法
| 方法 | 功能说明 | 示例 |
|---|---|---|
.append() | 末尾插入新元素 | doc('ul').append('<li>new</li>') |
.prepend() | 开头插入新元素 | doc('div').prepend('<h2>Title</h2>') |
.replace_with() | 节点替换 | doc('img.old').replace_with('<img src="new.jpg">') |
.empty() | 清空子节点 | doc('div.temp').empty() |
四、工程级优化策略
4.1 性能提升方案
- 缓存机制:对重复查询结果进行变量存储
nav = doc('nav.main') # 缓存导航节点 - 生成器应用:处理大型文档时优先使用
.items()for item in doc('div.product').items(): process(item) - 选择器优化:避免全局选择器
*,限制查询深度
4.2 反爬对抗体系
# 请求头伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)',
'Accept-Language': 'en-US,en;q=0.9'
}
# 代理中间件
proxies = {'http': 'http://10.10.1.10:3128'}
# 动态等待策略
from time import sleep
sleep(random.uniform(1, 3))
4.3 异常处理框架
try:
price = doc('span.price').text()
except AttributeError as e:
logging.error(f"价格节点缺失: {str(e)}")
price = None
五、行业级实战案例
5.1 电商数据采集系统
def extract_product(doc):
return {
'name': doc('h1.title').text().strip(),
'price': doc('meta[property="price"]').attr('content'),
'sku': doc('div#product').attr('data-id'),
'images': [img.attr('src') for img in doc('div.gallery img').items()]
}
5.2 新闻聚合引擎
class NewsParser:
def __init__(self, html):
self.doc = pq(html)
@property
def articles(self):
return [self._parse_article(div) for div in self.doc('article.news').items()]
def _parse_article(self, div):
article = pq(div)
return {
'title': article('h2').text(),
'timestamp': article('time').attr('datetime'),
'summary': article('p.excerpt').text(),
'tags': [pq(tag).text() for tag in article('a.tag').items()]
}
六、扩展生态整合
6.1 配套工具链
- requests-html:集成动态渲染能力
- parsel:Scrapy底层解析引擎兼容
- pandas:数据清洗与结构化输出
6.2 数据管道架构
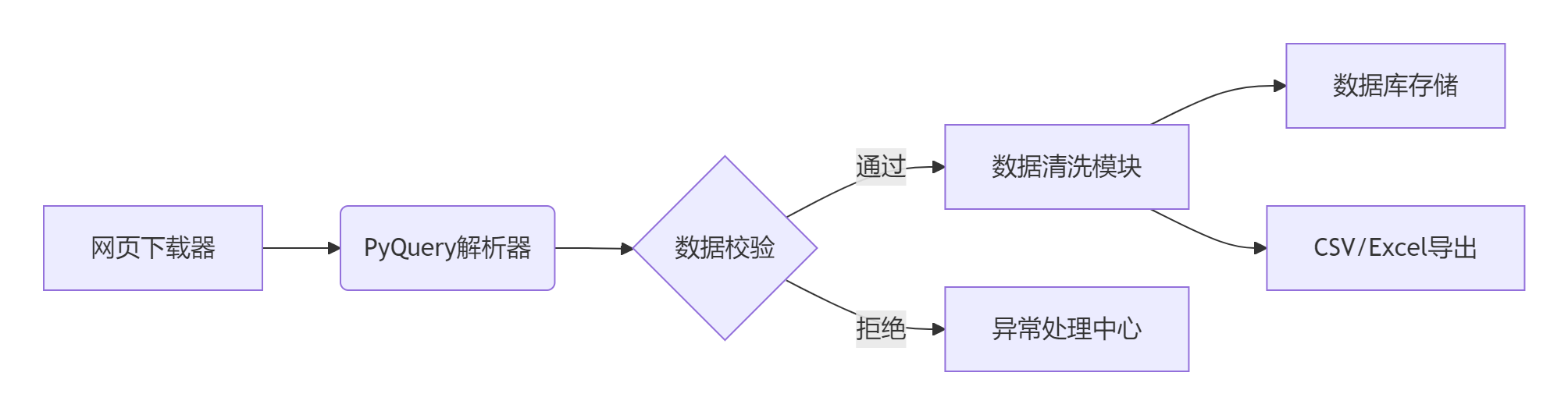
七、常见问题解决方案
- 动态内容加载:结合
.js()方法执行JavaScriptdoc = pq(url='https://example.com', js=True) - iframe嵌套处理:需先定位iframe节点再切换上下文
- 编码混乱问题:强制指定编码格式
doc = pq(response.content.decode('gb18030'))
八、最佳实践总结
- 编码规范:统一使用UTF-8编码体系
- 防御式编程:所有节点访问前进行空值检测
- 法律合规:严格遵守
robots.txt协议 - 生态整合:与Scrapy、Selenium等工具协同工作
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息



















 1938
1938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











