




个人主页:https://bento.me/zhengyanghou
Github:https://github.com/Jenqyang

GPT-1发表于2018年6月,比BERT早几个月。GPT-1使用的是Transformer decoder(解码器),而BERT使用的是Transformer encoder(编码器)。
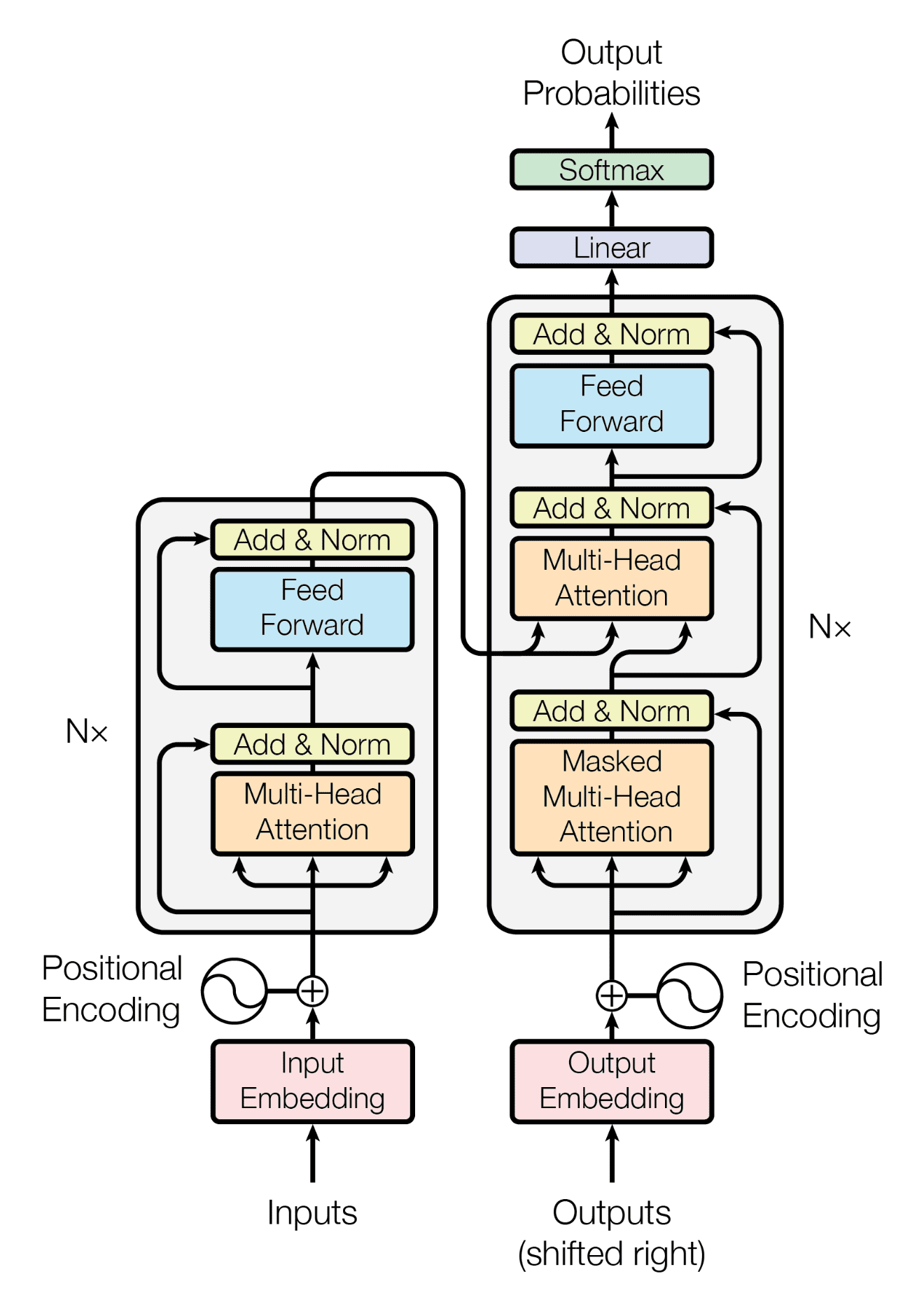
解码器和编码器最大的区别是解码器加入了掩码机制(Mask),这就导致在实际问题中,BERT是在做完型填空(没有Mask就意味着同时知道历史和未来的数据,要做的是根据历史和未来预测当前,这当然简单得多),而GPT-1是在续写作文(加入Mask就意味着只知道当前和历史数据,要做的是根据历史预测未来,这就比BERT要难)。
这也是为什么BERT前几年在NLP界的影响力也远高于GPT。
GPT-1的构造分为两个阶段:Unsupervised pre-training和Supervised fine-tuning。GPT-1在预训练阶段(pre-training)使用无标注的数据进行无监督训练,在微调(fine-tuning)阶段使用有标注的数据进行监督训练。
Unsupervised pre-training
预训练阶段器目标函数为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









