




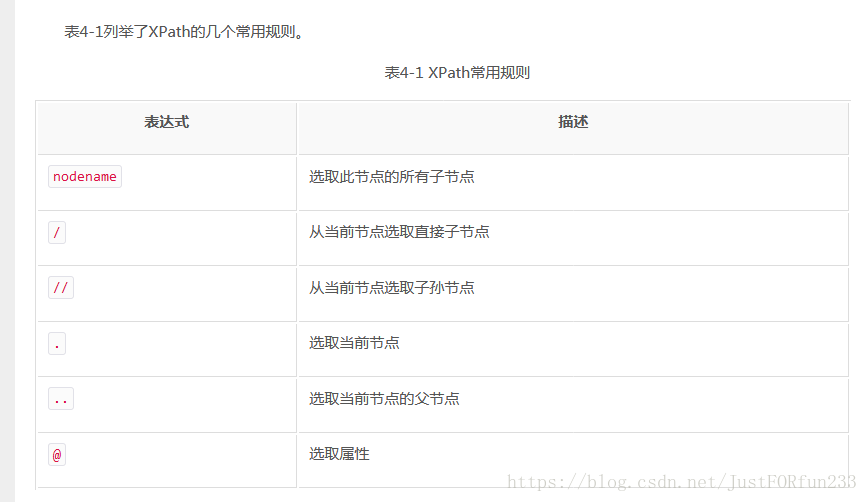
其实通俗来说 //是相对查找,/具体查找
我要爬取它的小说的网址,通过分析(其实爬虫最重要是分析),知道了网址全部藏在<div class='box'>
下面的<ul>的<li>中,并且这个<div class='box'>有11个。
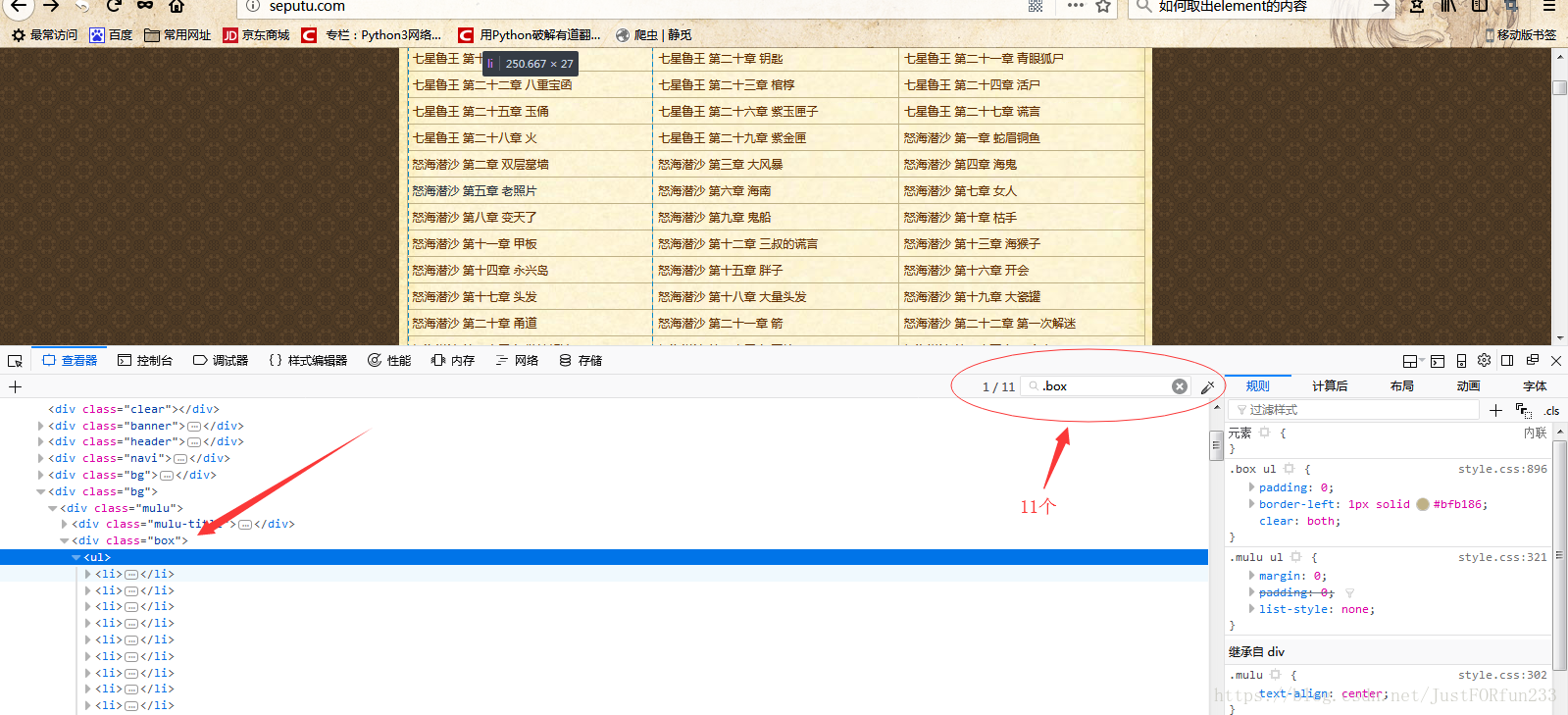
然后最开始的时候发现xpath中
import requests from lxml import etree header = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE', 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Encoding':'gzip, deflate', 'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2' } url = 'http://seputu.com/' r = requests.get(url,headers=header).content.decode('utf-8') html = etree.HTML(r) div = html.xpath('//div[@class="box"]') print(div)
结果为

这里可以看到提取结果是一个列表形式,其中每个元素都是一个element对象。如果要取出其中一个对象,可以直接用中括号加索引,如【0】。当然了你想取它的内容。

比方说是网址,就可以这样
url = 'http://seputu.com/' r = requests.get(url,headers=header).content.decode('utf-8') html = etree.HTML(r) div = html.xpath('//div[@class="box"]') for line in div: href = line.xpath('./ul/li') #找所有的li print(href)
for one in href: html = one.xpath('./a/@href') #因为他的里面有a标签 print(html)
在找li时要注意,ul前面有.选取当前节点,当前节点是<div class='box'>,然后对于每一个li标签,由于他含有a因此进入a标签
然后用@href选取a标签的属性,就可以找到网址。当然了,你要找到这个名字,就可以这样在/a后面text()

for line in div: href = line.xpath('./ul/li') #找所有的li print(href) for one in href: html = one.xpath('./a/text()') #因为他的里面有a标签 print(html)
这就可以选取他的文本。
说道属性,最开始的
div = html.xpath('//div[@class="box"]')
这句话是说找到标签为div 它的属性class的名字为box,当然啦,你有没有想,刚才的a标签里的网址可不可以这样写,当然可以,但是返回的是elements对象,因为找到的其实就是这个a标签

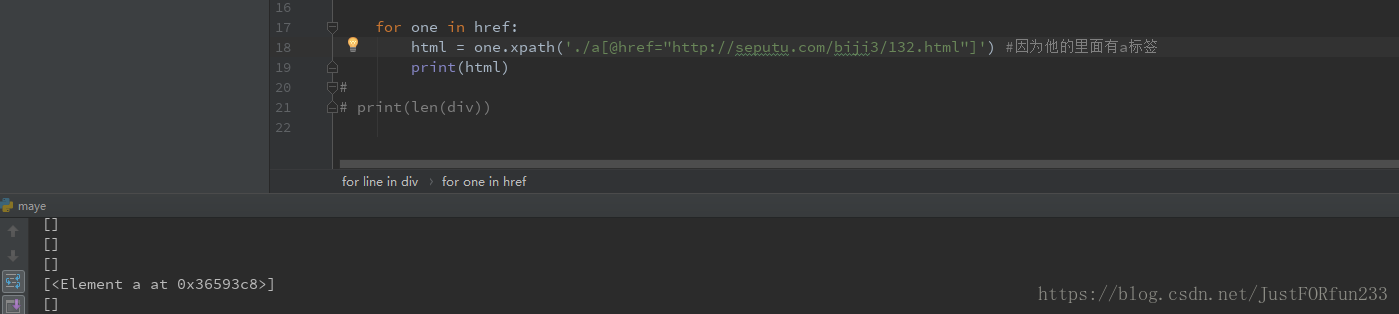
因此你想找到某个标签的内容的话就可以 ./xx/@xx,注意"."不要忘记打,因为前提是进入当前节点。
然后如果还想知道,属性多值匹配,和多属性匹配可以看这个网址https://cuiqingcai.com/5545.html


















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









