




今天用了 Python 来运行Spark,发现它使用的是默认的 Python 交互端,emmm,我已经用了 N 年的 Ipython 了,突然给我换默认的,没有代码提示根本受不了,所以去网站上看看有没有使用 Ipython 运行 Spark 的方法。
StackOverflow 上面说可以使用命令 set ipython=1 来设置默认使用 Ipython 运行 Spark,但是我试了一下没效果,仍然还是默认的 Python,然后去找其他文章大部分说的也都是 Linux 平台,我更想在 Windows 端做测试,所以就想试一下 Windows 端。但是找了一圈都没有具体的解法……
然后看到有文章说可以修改 Spark 目录里面的 pyspark.cmd 文件,然后尝试了一下这个方法,发现 pyspark.cmd 里面就只有一堆注释+调用 pyspark2.cmd~

接着去看 pyspark2.cmd:
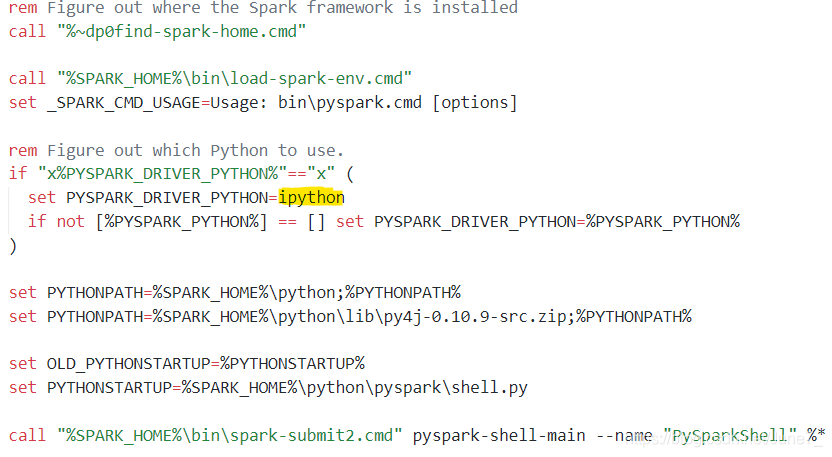
因为之前没学过 DOS 命令,所以没法完全看懂,但是能看的出一个大概,同时需要修改的部分已经在图片中标出(即黄色荧光笔部分),原来的地方是 python,我改成了 ipython,然后再次启动 pyspark 就是使用 ipython启动的~
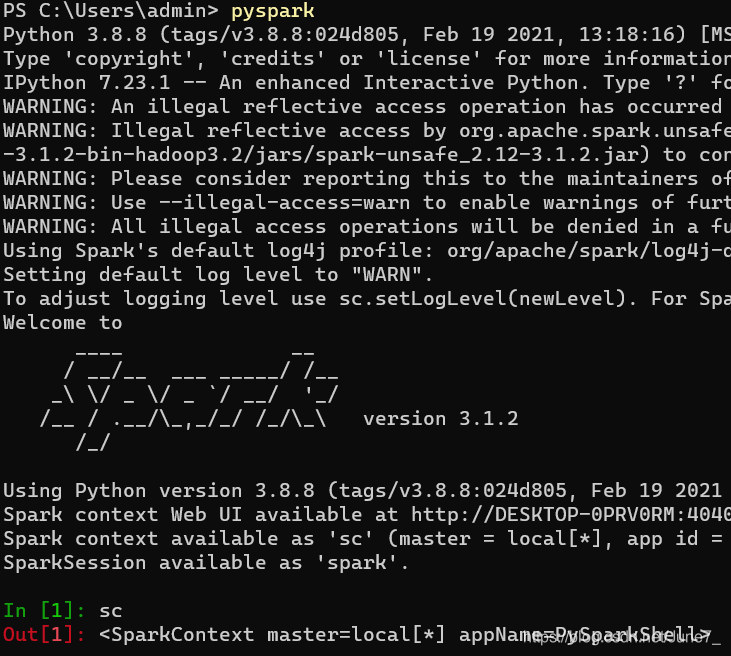
最下面的 In[1] 说明这就是 Ipython 环境,默认 Python 环境使用的交互符是 >>>
Windows上Spark使用Ipython 运行
最新推荐文章于 2025-10-31 16:08:02 发布
 本文介绍了如何在Windows环境下将PySpark的默认交互环境从Python更改为Ipython,并提供了具体的操作步骤,通过修改pyspark2.cmd文件实现这一目标。
本文介绍了如何在Windows环境下将PySpark的默认交互环境从Python更改为Ipython,并提供了具体的操作步骤,通过修改pyspark2.cmd文件实现这一目标。

















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









