




 本文介绍了大数据技术的发展历程,重点讲述了理想汽车大数据平台的架构,包括传输层、存储层、计算层和数据库层的组件选择。文章强调了云原生在大数据领域的优势,如弹性伸缩、自动化部署和成本效益,并探讨了面临的挑战。理想汽车正在借助JuiceFS实现HDFS到对象存储的迁移,以解决扩展性和成本问题,同时探索Lustre作为读缓存以提升性能。文章还讨论了未来大数据云原生的规划,包括统一数据管理和治理、底层存储性能优化、智能查询引擎的发展。
本文介绍了大数据技术的发展历程,重点讲述了理想汽车大数据平台的架构,包括传输层、存储层、计算层和数据库层的组件选择。文章强调了云原生在大数据领域的优势,如弹性伸缩、自动化部署和成本效益,并探讨了面临的挑战。理想汽车正在借助JuiceFS实现HDFS到对象存储的迁移,以解决扩展性和成本问题,同时探索Lustre作为读缓存以提升性能。文章还讨论了未来大数据云原生的规划,包括统一数据管理和治理、底层存储性能优化、智能查询引擎的发展。
理想汽车在 Hadoop 时代的技术架构
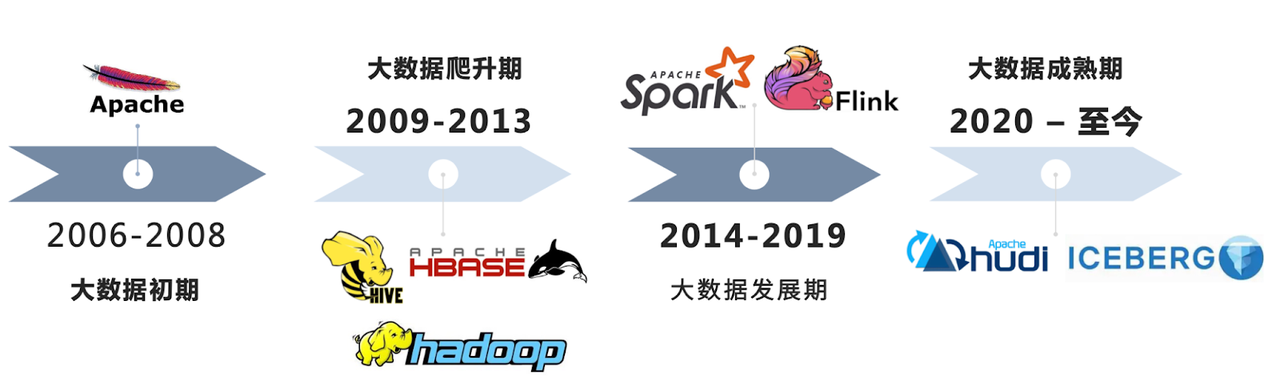
首先简单回顾下大数据技术的发展,基于我个人的理解,将大数据的发展分了4个时期:
第一个时期: 2006 年到 2008 年。2008 年左右,Hadoop 成为了 Apache 顶级项目,并正式发布了 1.0 版本,它的基础主要是基于谷歌的三驾马车,GFS、MapReduce、BigTable 去定义的。
第二个时期: 2009 年到 2013 年阶段。雅虎、阿里、Facebook 等企业对大数据的应用越来越多。2013 年底 Hadoop 正式发布 2.0 版本。我有幸在 2012 年的时候开始接触大数据,用 Hadoop 1.0 加 Hive 的模式体验了下,当时感觉很神奇的,大数据用几台机器就可以快速解决原来用 SQL Server 或者 MySQL 解决不了的问题。
第三阶段:2014 年到 2019 年,这段时间发展的非常快,期间 Spark、Flink 都成为了 Apache 顶级项目。在这个快速爬升期的过程中,我们还尝试用过 Storm,后来 Storm 就被 Flink 所替代了。
第四阶段: 从 2020 年至今,2020 年 Hudi 从 Apache 毕业成为顶级项目之后,我个人理解数据湖进入到整个发展的成熟期,到了大数据的数据湖 2.0 阶段。数据湖主要三个特点,首先是统一、开放式的存储,其次是开放式的格式,以及丰富的计算引擎。
整体的发展过程中,大数据主要是有几个特点,就是大家常说的四个“V”:规模性(Volume)、高速性(Velocity)、多样性(Variety)、价值性(Value)。现在还有第五个“V”(Veracity),数据的准确性和可信赖度。数据的质量是一直被人诟病的,希望行业里能有一套标准把数据湖的质量去做提升,这个可能是数据湖 2.0 出现的标准,因为出现了 Hudi、Iceberg 这些项目,都是想把整个数据湖的管理做好。
个人觉得 Hadoop 是大数据的一个代名词,但是大数据并不只有 Hadoop。大数据是在发展过程中由多个组件整合之后形成的一套解决大量数据加工处理和使用的解决方案。这几年,大家基本上认为 Hadoop 是在走下坡路的,首先是 Hadoop 商业化公司 Cloudera 和 Hortonworks 的合并和退市,原来的商业模式无法延续;也面临着快速增长的云供应商在成本和易用性上的挑战,以及 Hadoop 本身生态系统的日益复杂。
理想汽车大数据平台当前架构
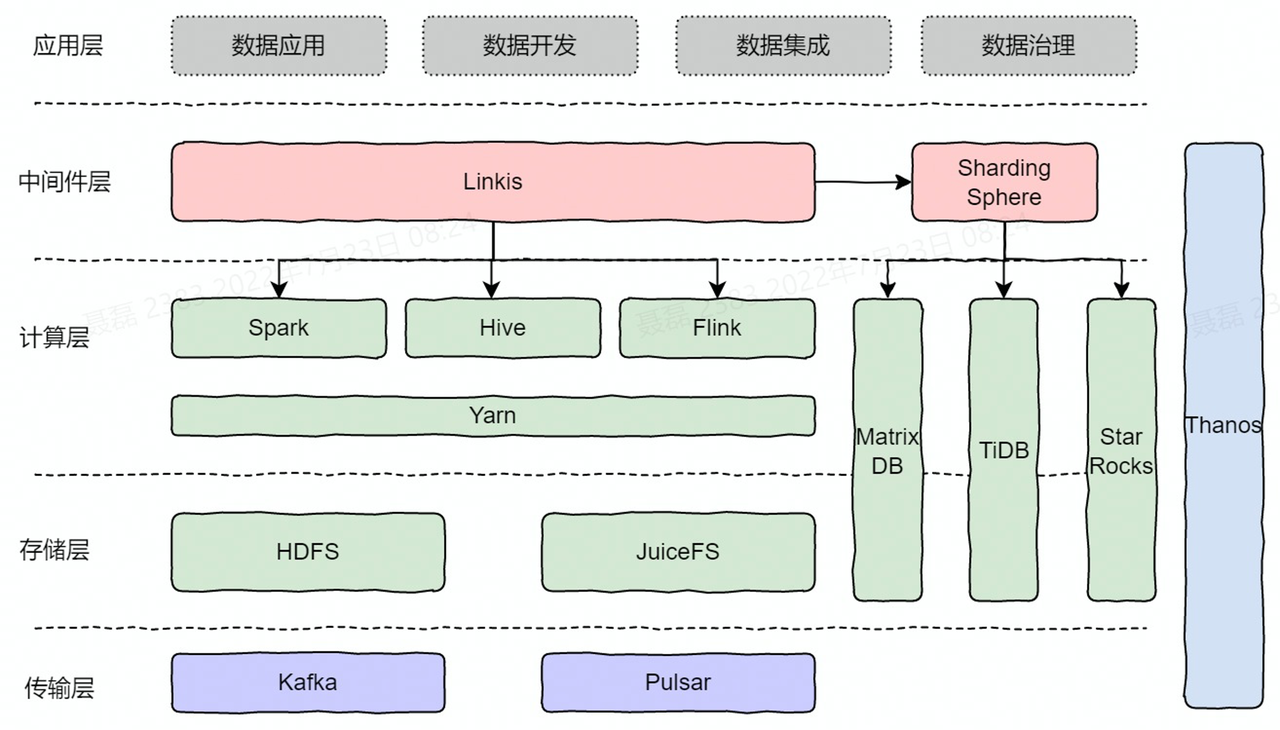
在这个阶段,理想汽车的大数据平台如上图所示。理想汽车用了很多开源的组件。
- 传输层: Kafka 和 Pulsar 。 平台构建初期整体都用的 Kafka,Kafka 的云原生能力比较差,Pulsar 在设计之初就是按照云原生架构设计的,并且有一些非常适合 IoT 场景的能力,和我们的业务场景也比较匹配,所以我们近期引进了 Pulsar。
- 存储层是 HDFS + JuiceFS。
- 计算层目前的主要的计算引擎是 Spark 和 Flink,这些计算引都是跑在现在的 Yarn 上。三个计算引擎是通过 Apache Linkis 去管理的,Linkis 是微众银行开源的,目前我们对 Linkis 用的也是比较重的。
- 右边是三个数据库,第一个 MatrixDB ,它是一个商业版的时序数据库,TiDB 主打做 OLTP 和 OLAP 的混合场景,目前我们主要用它来做 TP 的场景。StarRocks 负责 OLAP 的场景。
- ShardingSphere,是想要用它的 Database Plus 的概念去把底下的数据库统一的去做一个网关层的管理。目前还在探索阶段,有很多新增特性我们都很感兴趣。
- 再往右,Thanos 是一个云原生的监控方案,我们已经将组件、引擎和机器的监控都整合到 Thanos 方案里。
- 应用层是我们目前的四个主要的中台产品,包括数据应用、数据开发、数据集成和数据治理。
特点
大家通过大数据平台的现状可以发现一些特点:
- 第一,整个方案的组件是比较多的,用户对这些组件的依赖性强,且组件之间互相的依赖性也比较强。建议大家在未来组件选型的时候尽量选择云原生化比较成熟的组件。
- 第二,我们的数据是有明确的波峰波谷。出行场景一般都是早高峰晚高峰,周六周日人数会比较多。
- 第三个特点,我们数据的热度基本上都是最热的,一般只访问最近几天或者最近一周的数据。但是产生了大量的数据,有的时候可能需要大量回溯,因而数据也需要长久的保存,这样对数据的利用率就差了很多。
最后,整个数据体系目前从文件层面看缺少一些有效的管理手段。 从建设至今,基本上还是以 HDFS 为主,有大量的无用数据存在,造成了资源的浪费,这是我们亟待解决的问题。
大数据平台的痛点
- 第一,组件多,部署难度高、效率低。围绕 Hadoop 的大数据组件有 30 多个,常用的也有 10 几个之多。有些组件之间有强依赖和弱依赖,统一的配置和管理变得非常复杂。
- 第二,机器成本和维护成本比较高。为了业务的稳定运行,离线和实时集群进行了分开部署。但上面提到的业务特点,我们业务波峰波谷现象明显,整体利用率不高。集群组件繁多需要专门人员管理和维护。
- 第三,跨平台数据共享能力。目前跨集群共享数据只能通过 DistCp 方式同步到其他 Hadoop 集群。无法方便快捷的同步到其他平台和服务器上。
- 第四,数据的安全和隐私合规。基于不同的数据安全需求,普通用户通过 Ranger 进行管理,特殊安全需求只能通过构建不同集群并设置单独 VPC 策略的方式来满足,造成很多数据孤岛和维护成本。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









