




各位uu我们又见面啦!
今天在这里给大家分享一下一篇发在 informs 的 Transportaton Science 上的文章!利用 Branch-and-Price-and-Cut(BPC)解决具有时间窗和线性权重相关成本的分集车辆路径问题,文章质量非常高,建议各位看原文哦!
预计读完只需 13分钟 !
嘿嘿嘿,那我们就开始叭 ~~~
1. 前言
这篇文章介绍了一种新的车辆路径问题,涵盖了时间窗、分割配送和线性重量相关成本。这一问题是带时间窗的分割配送车辆路径问题 SDVRPTW 的扩展,考虑到车辆重量对运输成本的影响。作者们提出了精确的 Branch-and-Price-and-Cut 算法,并设计了一种新的标签设置算法来解决定价子问题。
1.1 传统车辆路径问题(VRP)
传统 VRP 是设计若干车辆行驶路线,以最小化总运输成本(通常为总行驶距离),并满足车辆容量限制、每个客户点仅访问一次以及所有路线从仓库出发并返回的约束。常见变种包括带时间窗的VRP(VRPTW)、带多仓库的VRP(MDVRP)和带分割配送的VRP(SDVRP)。解决方法包括精确算法和启发式算法。实际应用广泛,如物流配送、垃圾收集、公共交通和服务调度。这是在运筹领域和交通领域最 fundamental 的一个问题。基本很多问题都 based on VRP,就如上两篇推文的 单向汽车共享系统中的E-VReP 和 紧急停电时基站的发电机分配问题 GDP。
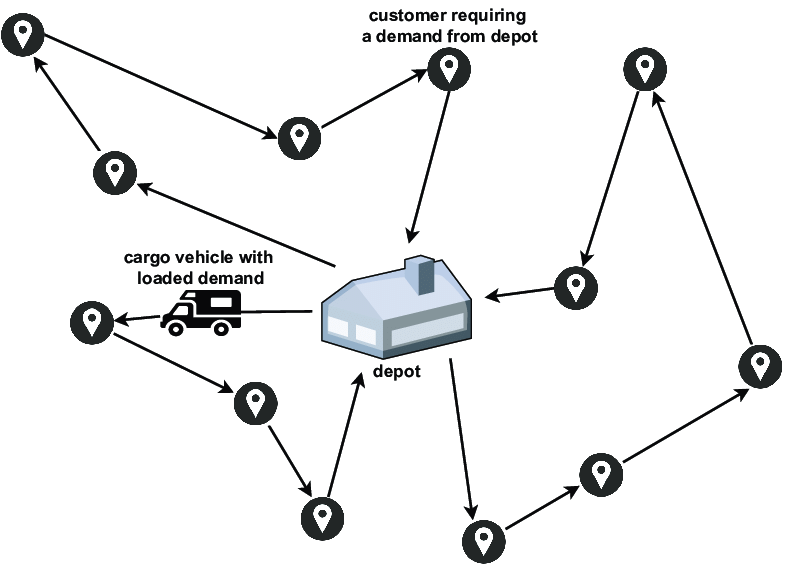
1.2 带时间窗和线性重量相关成本的分割配送车辆路径问题 SDVRPTWL
带时间窗和线性重量相关成本的分割配送车辆路径问题 the Split-Delivery Vehicle Routing Problem with Time Windows and Linear Weight-Related Cost, SDVRPTWL 是一个结合了分割配送、时间窗口和线性重量相关成本的复杂车辆路径问题模型。它允许在考虑车辆载重限制和行驶距离的基础上,灵活地规划车辆路径,以最小化总体运输成本和满足所有客户需求的约束条件。
先给大家科普一下:
分割配送车辆路径问题 Split-Delivery Vehicle Routing Problem, SDVRP
- 是车辆路径问题 VRP 的一种变体。在传统的 VRP 中,每辆车只能服务一个客户的全部需求,而在 SDVRP 中,一辆车可以在一次行程中分割配送给多个客户,从而更灵活地满足需求。
什么是分割配送??
是指在 VRP 中的一种策略,允许一辆车在单次行程中分割配送货物给多个客户。传统的 VRP 模型假设每辆车在一次行程中只能服务一个客户的全部需求,而分割配送则放宽了这一限制,使得车辆能够更加灵活地满足多个客户的需求。
- 部分服务:车辆可以将其负载在单次行程中分割为多个部分,每个部分可以服务不同的客户需求。
- 灵活分配:这意味着在同一次行程中,车辆可以首先服务某些客户,然后回到仓库或者重新计划路径,再去服务其他客户。
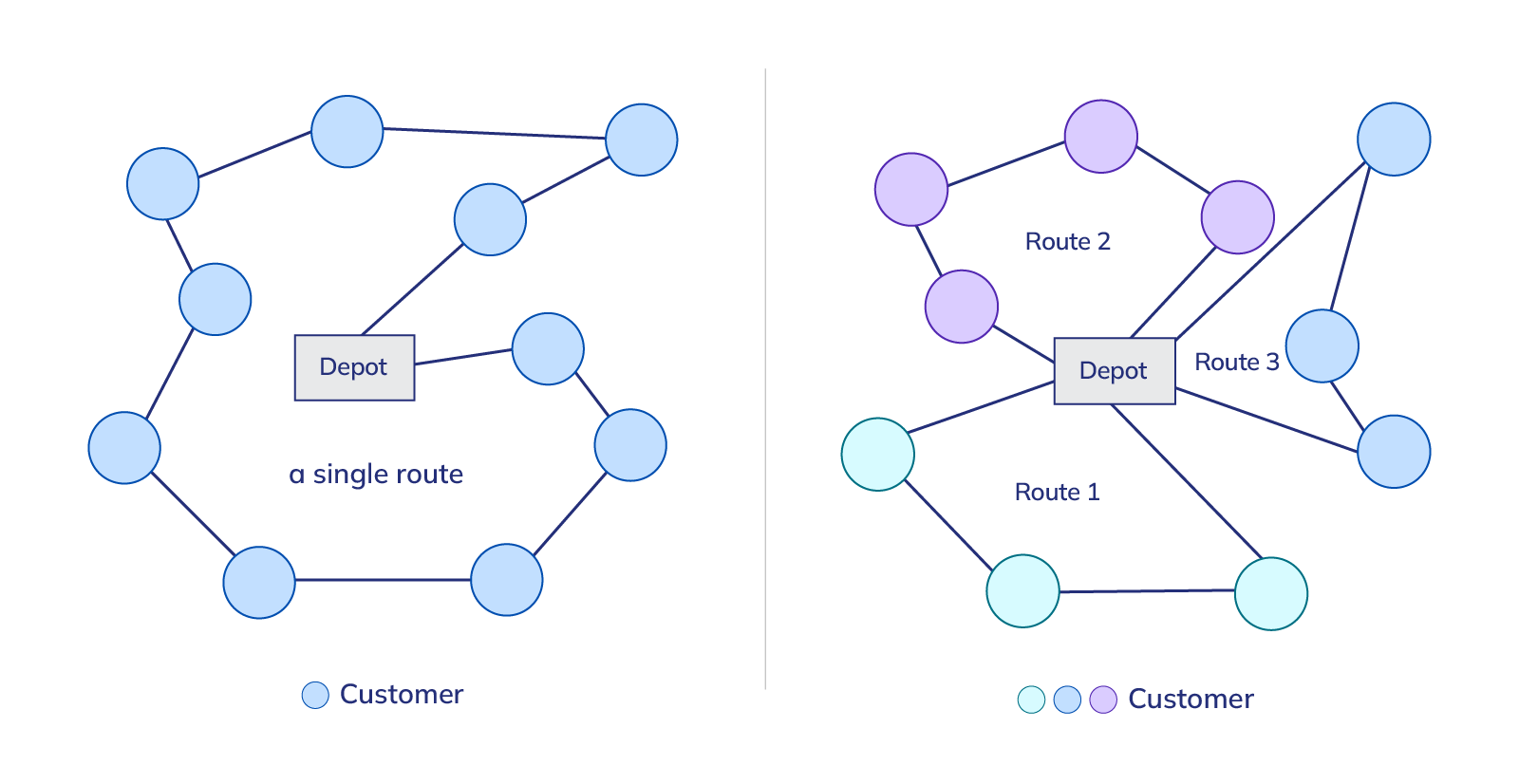
我们可以一起看看上图。如果有一辆车需要服务十个客户的需求(图左侧),传统VRP可能会规划一个完整的路线,依次经过这十个客户,并回到起点仓库。而在分割配送策略下,这辆车可以先去服务青色客户,然后回到仓库重新装载或重新规划路径,再去服务紫色和蓝色客户,甚至在这个过程中会再次回到仓库。
在这里相信uu们都已经非常清楚了❗
时间窗 Time Windows
指在车辆路径规划中,每个客户有一个指定的时间窗,在这个时间窗内必须到达客户才能被接受,以考虑客户的时间限制和服务时间。这些时间窗可以由以下两种方式定义:
-
硬时间窗 Hard Time Windows :客户必须在指定的时间窗口内被访问,否则将被视为违规,可能会导致路径方案的不可接受。
-
软时间窗 Soft Time Windows :客户有一个理想的时间窗口,在此期间内访问客户会有额外的成本或惩罚。虽然不是必须在此时间窗口内访问客户,但最好在此期间内访问。
给个送外卖的例子吧❗(小编最喜欢讲例子)
-
硬时间窗意味着你必须在规定的时间窗内到达客户那里。如果你迟到超过了这个时间窗,那么这次服务可能会被视为无效,客户不会接受你的服务,因为他们不再需要食物或无法等待。就是过了点我直接不要了!
-
软时间窗则表明你可以在指定的时间窗外到达客户那里,但是每迟到一定时间会有额外的成本。这种成本可以通过扣除你的小费或公司给你的奖金来体现,也可以是客户不再愿意使用你的服务。就是过了点没关系,可是你必须要被扣钱!
线性重量相关成本 Linear Weight-Related Cost
- 在 SDVRPTWL 中,考虑了车辆载重对运输成本的影响,采用了线性重量相关成本模型。
- 成本函数 f(w)f(w)f(w) :假设运输成本不仅与行驶距离相关,还与车辆的载重 www 相关。具体地,成本函数可以表示为 f(w)=a×w+bf(w) = a \times w + bf(w)=a×w+b,其中 aaa 和 bbb 是常数,www 是车辆的载重。aaa 表示了每增加单位重量所增加的额外成本;bbb 表示了空载(或基本成本)情况下的运输成本。
- 这意味着随着车辆的载重增加,单位距离的运输成本也会相应增加。例如,当车辆携带更多货物时,可能需要更多的燃料,而这种额外的燃料消耗会增加成本。
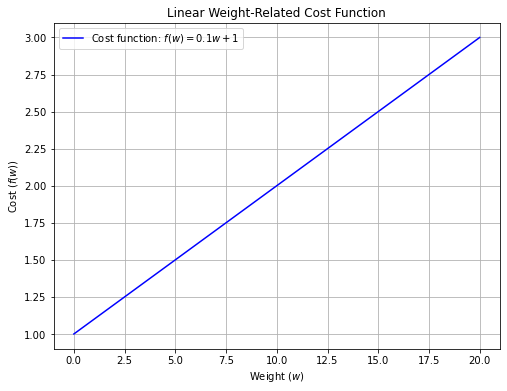
为了让大家更直观明白,我这里假设 a=0.1a=0.1a=0.1 和 b=1b=1b=1 ,然后画出成本函数的图形,展示成本随着车辆重量增加而线性增加的情况,可以看到 xxx 轴是车辆重量
www ,yyy 轴是对应的运输成本 f(w)f(w)f(w)。
关键核心问题
在这里就会有几个问题我们需要思考一下:
- 如何考虑成本模型的准确性和实用性,以及在实际运输中其他因素(如燃料价格变化、道路条件等)的影响呢?
- 如何有效地在时间窗口内规划路径,以最小化总运输成本呢?
- 如何合理分配车辆容量以满足所有客户的需求,并在此过程中优化运输成本呢?
以上的问题,大家一起想一想哈~~~
2. 问题描述
SDVRPTWL 定义在一个有向图 G=(V,E)G = (V, E)G=(V,E) 上,其中 V={0,1,…,n+1}V = \{0, 1, \ldots, n+1\}V={0,1,…,n+1} 是顶点集合,E={(i,j)∣i,j∈V,i≠j,i≠n+1,j≠0}E = \{(i, j)\mid i, j \in V, i \neq j, i \neq n+1, j \neq 0\}E={(i,j)∣i,j∈V,i=j,i=n+1,j=0} 是边集 。其中顶点 000 和 n+1n+1n+1 分别是出口和入口到仓库的点,其余顶点 VC={1,…,n}V_C = \{1, \ldots, n\}VC={1,…,n} 是顾客集合。
- 符号定义:
- d0=+∞d_0 = +\inftyd0=+∞ :表示仓库顶点 000 的需求为无穷大,即仓库不需要接受产品。
- dn+1=0d_{n+1} = 0dn+1=0 :表示入口顶点 n+1n+1n+1 的需求为零,即仓库不需要提供产品。
- s0=sn+1=0s_0 = s_{n+1} = 0s0=sn+1=0 :表示仓库顶点 000 和入口顶点 n+1n+1n+1 的服务时间为零。
- e0=en+1=0e_0 = e_{n+1} = 0e0=en+1=0 :表示仓库顶点 000 和入口顶点 n+1n+1n+1 的时间窗口起始时间为零。
- l0=ln+1=+∞l_0 = l_{n+1} = +\inftyl0=ln+1=+∞ :表示仓库顶点 000 和入口顶点 n+1n+1n+1 的时间窗口结束时间为无穷大,即没有限制。
- 边的属性:
- (i,j)∈E(i, j) \in E(i,j)∈E :表示图 GGG 中存在一条从顶点 iii 到顶点 jjj 的边。
- ci,j≥0c_{i,j} \geq 0ci,j≥0 :表示边 (i,j)(i, j)(i,j) 的距离非负。
- ti,j≥0t_{i,j} \geq 0ti,j≥0 :表示边 (i,j)(i, j)(i,j) 的遍历时间非负。
- 三角不等式保证了对于任意三个顶点 i,j,ki, j, ki,j,k ,有 ci,j≤ci,k+ck,jc_{i,j} \leq c_{i,k} + c_{k,j}ci,j≤ci,k+ck,j 和 ti,j≤ti,k+tk,jt_{i,j} \leq t_{i,k} + t_{k,j}ti,j≤ti,k+tk,j ,即从一个顶点到另一个顶点的最短路径满足三角形式。
- 顶点的后继和前驱:
- V+(i)={j∈V∣ei+si+ti,j≤lj,(i,j)∈E}V^+(i) = \{ j \in V \mid e_i + s_i + t_{i,j} \leq l_j, (i, j) \in E \}V+(i)={j∈V∣ei+si+ti,j≤lj,(i,j)∈E} :顶点 ( i ) 的后继顶点集合,满足时间窗口约束。
- V−(i)={j∈V∣ej+sj+tj,i≤li,(j,i)∈E}V^-(i) = \{ j \in V \mid e_j + s_j + t_{j,i} \leq l_i, (j, i) \in E \}V−(i)={j∈V∣ej+sj+tj,i≤li,(j,i)∈E} :顶点 iii 的前驱顶点集合,满足时间窗口约束。
- 每个顶点 iii 有正的需求 did_idi,服务时间 sis_isi ,和一个时间窗 [ei,li][e_i, l_i][ei,li] 表示服务可以开始的时间范围。
- 每条边 (i,j)∈E(i, j) \in E(i,j)∈E 有非负距离 ci,jc_{i,j}ci,j 和穿越时间 ti,jt_{i,j}ti,j,并满足三角不等式。
- 车辆和配送模式:
- 每辆车具有相同的重量容量 QQQ 。
- 每辆车从仓库顶点 000 出发,访问一些顾客,每个顾客处交付一定数量的产品,最后返回入口顶点 n+1n+1n+1 。
- 每个配送模式定义了一条路线,指定了每个顶点交付的产品数量。
- 如果车辆在顶点 iii 处早于时间窗 eie_iei 到达,它必须等到时间窗开始后才能开始服务。
- 配送模式的可行性:
- 一个配送模式是可行的,如果其路线尊重所有访问顾客的时间窗口,并且其总交付需求不超过 QQQ。
- 每个顾客的需求可以由多辆车满足,即顾客需求可能大于车辆容量,并且可以多次访问同一顾客。
- 边的遍历成本:
- 边 (i,j)(i, j)(i,j) 上的遍历成本由承载重量 wi,jw_{i,j}wi,j 的车辆支付,计算公式为 ci,j×f(wi,j)c_{i,j} \times f(w_{i,j})ci,j×f(wi,j) ,其中 f(wi,j)=a×wi,j+bf(w_{i,j}) = a \times w_{i,j} + bf(wi,j)=a×wi,j+b ,且 bbb 是车辆的基本成本。
- 优化目标:
- SDVRPTWL 的目标是找到一组可行的配送模式,以满足所有顾客的需求,并且使总遍历成本最小化。
问题的性质
- 性质 1:存在一个最优解,其中每条路线最多只访问每个顾客一次。
- 性质 2:最优解中,最多只有一辆车可以被分配到有两个或更多客户的路线
- 性质 3:每条边 (i,j)∈EC(i, j) \in E_C(i,j)∈EC 最多只出现一次,其中 EC={(i,j)∣(i,j)∈E,i,j∈VC}E_C = \{(i, j)\mid (i, j) \in E , i, j \in V_C\}EC={(i,j)∣(i,j)∈E,i,j∈VC}。
参数变量
- 参数:
- K={1,2,…,m}K = \{1, 2, \ldots, m\}K={1,2,…,m} :表示可用车辆的集合,总数为 mmm 辆。
- MMM :表示一个足够大的正数,通常用于表示无穷大或非常大的上界。
- 决策变量:
- xi,j,kx_{i,j,k}xi,j,k :二进制变量,如果车辆 kkk 能够穿越边 (i,j)(i, j)(i,j) ,则取值为 111 ,否则为 000 。
- wi,j,kw_{i,j,k}wi,j,k :车辆 kkk 在边 (i,j)(i, j)(i,j) 上的负载重量。
- ai,ka_{i,k}ai,k:车辆 kkk 在顾客 iii 处的服务开始时间。
目标函数
min∑k∈K∑i∈VC∪{0}∑j∈V+(i)ci,j(awi,j,k+bxi,j,k)\min \sum_{k \in K} \sum_{i \in V_C \cup \{0\}} \sum_{j \in V^+(i)} c_{i,j}(a w_{i,j,k} + b x_{i,j,k})mink∈K∑i∈VC∪{0}∑j∈V+(i)∑ci,j(awi,j,k+bxi,j,k)
- KKK 是可用车辆的集合。
- VCV_CVC 是顾客的集合。
- V+(i)V^+(i)V+(i) 是顶点 iii 的后继顶点集合。
- ci,jc_{i,j}ci,j 是从顶点 iii 到顶点 jjj 的距离或成本。
- wi,j,kw_{i,j,k}wi,j,k 是车辆 kkk 在边 (i,j)(i, j)(i,j) 上的负载重量。
- xi,j,kx_{i,j,k}xi,j,k 是二进制变量,如果车辆 kkk 穿越边 $(i, j) $,则为 111 ;否则为 000 。
- aaa 和 bbb 是常数,其中 bbb 表示车辆的固定成本。
它目的是寻找一组可行的配送模式,使得所有顾客的需求得到满足,并且考虑到负载重量和固定成本 bbb,使总的遍历成本最小化。
详细约束请阅读原文。
经过了问题描述,不知道大家都理解透了吗 ~~~
3. 算法流程
3.1 Dantzig–Wolfe 分解
Dantzig–Wolfe 分解是将问题分解为主问题和定价子问题来处理的数学分解技术,其中主问题包含与每条路径兼容的所有交付模式的决策变量。为了求解主问题,使用了 Column Generation 算法,并通过 Branch-and-Price-and-Cut 算法来处理整个问题。定价子问题则通过定制的标签设置算法来解决。
- **原问题(SDVRPTWL)**的变量被分组,其中每组变量代表一种特定的交付模式或路径。
- 分解后得到的主问题负责决定哪些路径和交付模式应该被使用,以及它们应该被使用多少次。
- 定价子问题用于生成新的列(即新的路径或交付模式),这些列被逐步加入到主问题中,以改进当前的解。
主问题MP的构建
-
目标函数:最小化总运输成本,这由不同路径和交付模式的成本之和表示。
zMP=min∑r∈R∑p∈Prcr,pθr,p z^{MP} = \min \sum_{r \in R} \sum_{p \in P_r} c_{r,p} \theta_{r,p} zMP=minr∈R∑p∈Pr∑cr,pθr,p
其中,cr,pc_{r,p}cr,p 表示路径 rrr 下的模式 ppp 的成本,θr,p\theta_{r,p}θr,p 表示模式 ppp 被分配的车辆数量。 -
约束条件:
-
客户需求:确保每个客户的需求都能被满足。
∑r∈R∑p∈Prδi,pθr,p≥di∀i∈VC \sum_{r \in R} \sum_{p \in P_r} \delta_{i,p} \theta_{r,p} \geq d_i \quad \forall i \in VC r∈R∑p∈Pr∑δi,pθr,p≥di∀i∈VC
其中,δi,p\delta_{i,p}δi,p 表示在模式 ppp 下在客户 iii 处交付的数量,did_idi 表示客户 iii 的需求量。 -
车辆容量:确保任何路径上的货物总量不超过车辆的容量。
∑r∈R∑p∈Prαr,pθr,p≥⌈diQ⌉∀i∈VC \sum_{r \in R} \sum_{p \in P_r} \alpha_{r,p}\theta_{r,p} \geq \left\lceil \frac{d_i}{Q} \right\rceil \quad \forall i \in VC r∈R∑p∈Pr∑αr,pθr,p≥⌈Qdi⌉∀i∈VC
其中,QQQ 为车辆的容量。
-
为什么不直接把这一块扔给 CPLEX 处理啊?因为由于路径和交付模式的数量庞大,即使是简单的实例,主问题的变量数量也非常大,所以无法直接使用 CPLEX 处理。
定价子问题
-
定价子问题用于在当前主问题线性松弛问题求解得到的对偶变量的基础上,寻找具有最小 reduced cost 的路径和交付模式。
-
它实际上是一个带资源限制的最短路径问题 ESPPRC(NP-complete),即在资源约束条件下,寻找通过图的最短路径。
-
目标函数:
cˉr,p=cr,p−∑i∈r(δi,pπi+μi) \bar{c}_{r,p} = c_{r,p} - \sum_{i \in r} \left(\delta_{i,p}\pi_i + \mu_i\right) cˉr,p=cr,p−i∈r∑(δi,pπi+μi)
其中,πi\pi_iπi 和 σi\sigma_iσi 是与客户需求和车辆容量约束相关的对偶变量。
以上只是一个小科普,让大家可以理解一下基本概念,那阅读文章的时候就可以更加通透了。
3.2 列生成 CG 及其定价子问题
列生成方法用于解决具有大量变量的大规模线性规划问题。这种方法通过逐步引入对优化目标函数和约束有关键影响的列(变量),来避免直接求解主问题 MP,从而提高求解效率。
-
受限主问题(RLMP):
- RLMP的定义:RLMP 是主问题 MP 的一个简化版本,包含的变量是定价子问题生成的少数列,而不是所有可能的列。由于 RLMP 的变量数量相对较少,因此可以通过标准的单纯形算法高效地求解。
- RLMP的解及对偶变量:求解 RLMP 可以得到一组当前的最优解和相应的对偶变量值。这些对偶变量值将在接下来的定价子问题中起关键作用。
-
定价子问题:
- 定价子问题的目标:定价子问题的核心是找到新的列,这些列对当前 RLMP 的解具有改进作用,即具有负的 reduced cost。
- 定价子问题的解法:定价子问题的求解过程涉及枚举所有可能的配送模式,也就是 CG 中的列,计算它们的reduced cost。如果发现负的 reduced cost 的列,则引入 RLMP,并开始新的列生成迭代;否则,列生成过程终止,当前 RLMP 的解即为主问题 MP 的最优解。
极端配送模式 Extreme Delivery Pattern
极端配送模式的定义:
- 极端配送模式是一种特殊的配送模式,其中每个客户节点的配送量要么为0(即不配送),要么为满载配送(即达到需求量),要么仅对一个节点进行部分配送。这种模式是所有可能配送模式的极端情况。
- 这种模式的引入是基于一种理论,即定价子问题的最优解中至少存在一个极端配送模式。所以文中只考虑极端配送模式来简化定价子问题的求解过程。
极值配送模式的证明(文中定理3):
- 文中定理3证明了,定价子问题的最优解中至少存在一个是极端配送模式。这意味着在求解定价子问题时,只需在所有可能的极端配送模式中寻找最优解,从而大幅减少了搜索空间。
文中有个函数非常重要,这个函数 G(r,q)G(r, q)G(r,q) 用来表示在特定的路径 rrr 上,配送量 qqq 对应的最小化 reduced cost。
-
凸性:显然函数 G(r,q)G(r, q)G(r,q) 是凸的,意味着随着配送量 qqq 的增加,函数的值变化呈现出一个非递减的模式。具体来说,初始时 reduced cost 的降低幅度较大,但随着配送量的增加,reduced cost 的边际效益逐渐减小。
-
连续分段线性:函数 G(r,q)G(r, q)G(r,q) 是由多个线性段组成的,且这些线性段在某些点(即每个节点的需求量)发生转折。每个线性段的斜率由节点的边际效益 gvk′g_{v'_k}gvk′ 决定,较高的边际效益对应较陡的斜率。
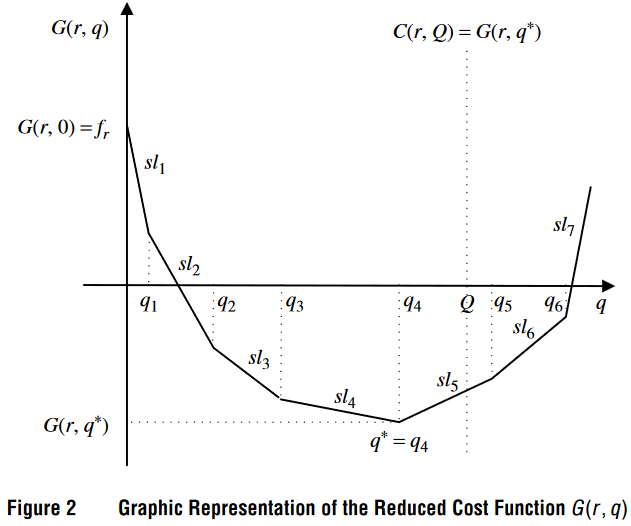
-
函数 G(r,0)=frG(r, 0) = f_rG(r,0)=fr: 在 q=0q=0q=0 时,函数值等于固定成本 frf_rfr,这表示在没有任何配送量的情况下,路径 rrr 的固定成本。
-
斜率 slk=−gvk′sl_k = -g_{v'_k}slk=−gvk′: 每一段的斜率等于负的节点边际效益 −gvk′-g_{v'_k}−gvk′,这是因为在增加配送量时,reduced cost 的速率由边际效益决定。
-
节点需求量 qkq_kqk: 每个节点的需求量 qkq_kqk 是函数 G(r,q)G(r, q)G(r,q) 转折点的横坐标,对应的是前 kkk 个节点的累积需求量。
那这里的 C(r,Q)C(r, Q)C(r,Q) 应该怎么计算?
-
从 G(r,q)G(r, q)G(r,q) 中获取 C(r,Q)C(r, Q)C(r,Q): 通过函数 G(r,q)G(r, q)G(r,q) 的最小值,计算出路径 rrr 对应的最小化减少成本 C(r,Q)C(r, Q)C(r,Q),即 C(r,Q)=G(r,q∗)C(r, Q) = G(r, q^*)C(r,Q)=G(r,q∗),其中 q∗q^*q∗ 是在 [0,Q][0, Q][0,Q] 范围内使 G(r,q)G(r, q)G(r,q) 最小的配送量。
-
零配送量的条件: 如果节点的边际效益 $g_{v_i} $ 小于等于零,那么对应的配送量 δvi\delta_{v_i}δvi 会被设为零。也就是说,如果给定路径 rrr 上的某个节点在当前解中没有产生任何收益(即其 gvi≤0g_{v_i} \leq 0gvi≤0),就不需要将任何配送量分配到该节点。
3.3 标签设置算法
标签设置算法是一种广泛使用的技术,用于解决各种车辆路径规划模型的定价子问题。解决定价子问题的目标是确定具有负的 reduced cost 的完整路径,即 C(r,Q)C(r, Q)C(r,Q)。在我们的标签设置算法中,定义了一个多维标签 Ei=(τi,Ni,Vi,G(r,q),Fi,SLi,Ii)E_i = (\tau_i, N_i, V_i, G(r, q), F_i, SL_i, I_i)Ei=(τi,Ni,Vi,G(r,q),Fi,SLi,Ii),它表示与从顶点 0 到顶点 i 的可行(部分)路径 r 相关的状态,其中:
- τi\tau_iτi 是在顶点 i 的最早服务开始时间,必须在 [ei,li][e_i, l_i][ei,li] 内;
- Ni⊆VN_i \subseteq VNi⊆V 是所有已访问顶点的集合;
- Vi⊆VV_i \subseteq VVi⊆V 是从路径 r 可以到达的所有顶点的集合;
标签的扩展
在顶点 0 处,定义初始标签 E0=(τ0,N0,V0,G(r,q),F0,SL0,I0)E_0 = (\tau_0, N_0, V_0, G(r, q), F_0, SL_0, I_0)E0=(τ0,N0,V0,G(r,q),F0,SL0,I0) 为:
- τ0=0\tau_0 = 0τ0=0
- N0={0}N_0 = \{0\}N0={0}
- V0=VV_0 = VV0=V
- G(r,q)G(r, q)G(r,q) 是与路径 rrr 和配送容量 qqq 相关的最小减缩成本
- F0F_0F0, SL0SL_0SL0, I0I_0I0 为初始值
每个顶点可以有多个标签,通过扩展标签到顶点 j∈Vj \in Vj∈V 生成新的标签 EjE_jEj。扩展函数包括:
- τj=max(ej,τi+si+ti,j)\tau_j = \max(e_j,\tau_i + s_i + t_{i,j})τj=max(ej,τi+si+ti,j)
- Nj=Ni∪{j}N_j = N_i \cup \{j\}Nj=Ni∪{j}
- Vj=Vi−{k∈V+(j):τj+sj+tj,k>lk}−{j}V_j = V_i - \{k \in V^+ (j) : \tau_j + s_j + t_{j,k} > l_k\} - \{j\}Vj=Vi−{k∈V+(j):τj+sj+tj,k>lk}−{j}
- Fj=Fi+bci,j−μjF_j = F_i + bc_{i,j} - \mu_{j}Fj=Fi+bci,j−μj
- SLj=SLi∪{gj}SL_j = SL_i \cup \{g_j\}SLj=SLi∪{gj}
- Ij=Ii∪{dj}I_j = I_i \cup \{d_j\}Ij=Ii∪{dj}
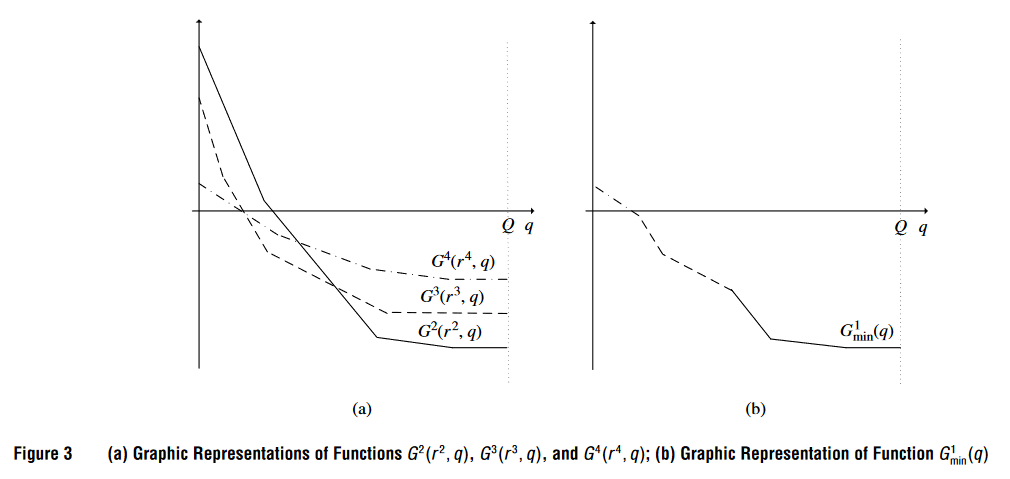
上图展示了从多个简化成本函数中选取的最小简化成本函数 Gmin1(q)G_{min}^1(q)Gmin1(q)。该函数由所有相关标号的简化成本函数的最小部分组成,并且不一定是凸的。上图也在说明一种新的支配规则,即集合支配规则(Set Dominance Rule)。我们可以看到虽然一个标号不能被其他单个标号支配,但可能会被一组标号的联合支配。这个图帮助解释如何利用所有相关标号的信息来构建一个新的最小简化成本函数,并通过这种方法安全地丢弃被支配的标号,从而优化算法的性能。
文中给出了集合支配规则的例子
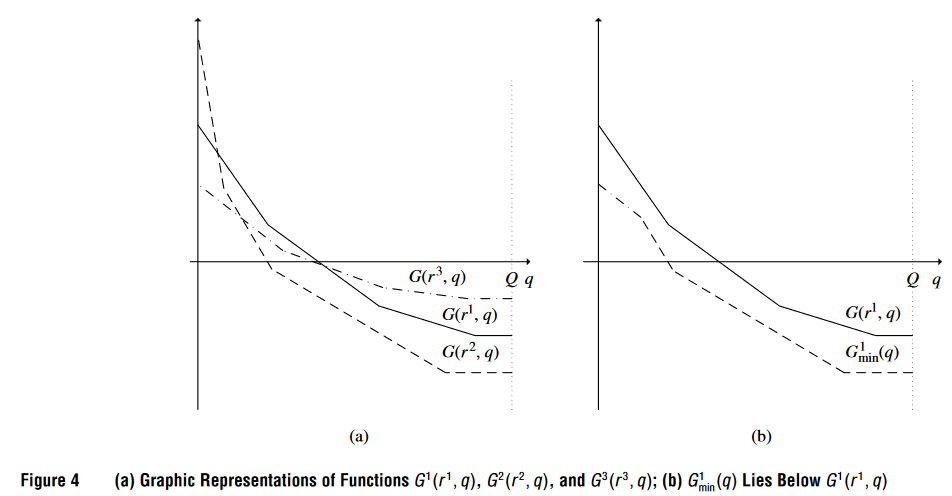
上图说明如何通过集合支配规则来支配标号。图中展示了两个标号 E2iE_2^iE2i 和 E3iE_3^iE3i,尽管它们单独都不能支配标号 E1iE_1^iE1i,但它们的联合却可以支配 E1iE_1^iE1i。这个图也展示了集合支配规则比传统的配对支配规则更为强大,能够更有效地减少待处理的标号数量,进而提升算法的效率。
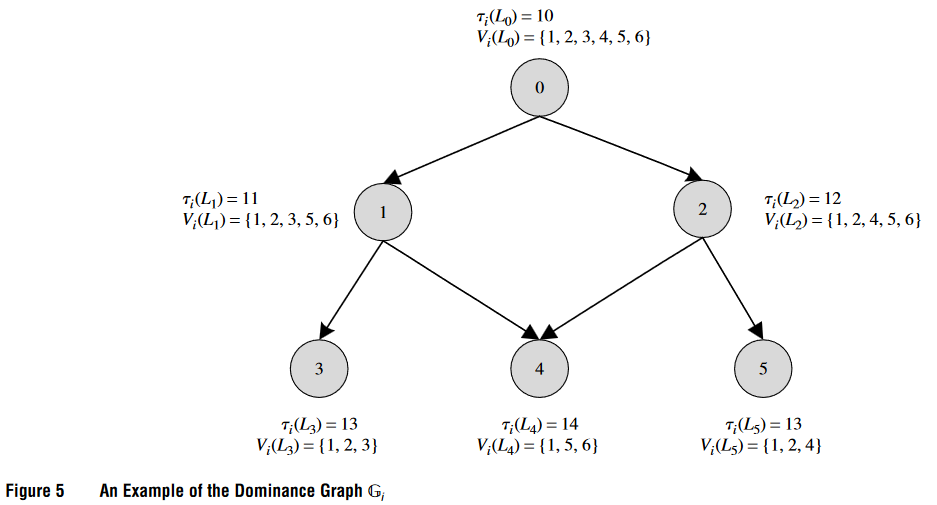
上图就展示了支配图的一个例子。在这个图中,节点表示终止于同一顶点的非支配标号集合。图中还显示了这些节点之间的有向边,边的创建是基于特定的条件,如最早服务开始时间和可达顶点集合等。这个图也详细展示了如何从根节点开始更新支配图,从而消除支配标号。
在算法运行过程中,支配图用于跟踪和维护非支配标号,并且通过添加新标号或调整最小简化成本函数来不断更新,从而优化标号设定算法的整体性能。
详细的算法加速策略建议大家阅读原文哈!
❗ ❗不要因为看到复杂的数学符号就怕了不敢读下去,其实他只是个符号,跟我们平时用的 xxx 和 yyy 是一样的❗ 读到这里已经很棒了,还有一半,加油❗❗
这段文字介绍了在带时间窗的集成配送问题(SDVRPTWL)中使用的有效不等式,以及如何将这些不等式应用到标签设定算法中。以下是对这部分内容的详细整理和分析:
3.4 有效不等式
kkk-路径不等式
定义:
-
kkk-路径不等式 是用来限制每条路径上必须覆盖一定数量的客户。形式为:
∑r∈R∑p∈Pr∑(i,j)∈E−(S)βi,j,rθr,p≥⌈∑i∈SdiQ⌉∀S∈Γ \sum_{r \in R} \sum_{p \in P_r} \sum_{(i,j) \in E^-(S)} \beta_{i,j,r} \theta_{r,p} \geq \left\lceil \frac{\sum_{i \in S} d_i}{Q} \right\rceil \quad \forall S \in \Gamma r∈R∑p∈Pr∑(i,j)∈E−(S)∑βi,j,rθr,p≥⌈Q∑i∈Sdi⌉∀S∈Γ -
左边:
- ∑r∈R\sum_{r \in R}∑r∈R:对所有的路径 rrr 求和。
- ∑p∈Pr\sum_{p \in P_r}∑p∈Pr:对每条路径 rrr 中的每个模式 ppp 求和。
- ∑(i,j)∈E−(S)\sum_{(i,j) \in E^-(S)}∑(i,j)∈E−(S):对离开客户子集 SSS 的所有边 (i,j)(i, j)(i,j) 求和。
- βi,j,r\beta_{i,j,r}βi,j,r:表示边 (i,j)(i, j)(i,j) 是否在路径 rrr 中使用的二进制参数。
- θr,p\theta_{r,p}θr,p:表示模式 ppp 是否在路径 rrr 中使用的二进制参数。
-
右边:
- ⌈∑i∈SdiQ⌉\left\lceil \frac{\sum_{i \in S} d_i}{Q} \right\rceil⌈Q∑i∈Sdi⌉:表示客户子集 SSS 的需求总和与车辆容量 QQQ 之比的上取整值。这表示需要的车辆数量。
这个不等式的作用是确保对于每个客户子集 SSS,至少有足够的路径覆盖从 SSS 中离开的边,从而满足总需求所需的车辆数量。这是为了保证在解中满足路径规划的合理性,确保不会因为边覆盖不足而违反容量约束。
强最小车辆数不等式 Strong Minimum Number of Vehicles (SMV) Inequalities.
定义:
-
SMV 不等式 旨在控制车辆数量,通过以下不等式实现:
∑r∈R∑p∈Pr(2αi,r,pF+αi,r,pSZ)θr,p≥2∀i∈VS \sum_{r \in R} \sum_{p \in P_r} \left(2 \alpha^F_{i,r,p} + \alpha^{SZ}_{i,r,p}\right)\theta_{r,p} \geq 2 \quad \forall i \in V_S r∈R∑p∈Pr∑(2αi,r,pF+αi,r,pSZ)θr,p≥2∀i∈VS -
左边:
- ∑r∈R\sum_{r \in R}∑r∈R:对所有的路径 rrr 求和。
- ∑p∈Pr\sum_{p \in P_r}∑p∈Pr:对每条路径 rrr 中的每个模式 ppp 求和。
- 2αi,r,pF+αi,r,pSZ2 \alpha^F_{i,r,p} + \alpha^{SZ}_{i,r,p}2αi,r,pF+αi,r,pSZ:其中:
- αi,r,pF\alpha^F_{i,r,p}αi,r,pF 是二进制参数,表示如果客户 iii 在路径 rrr 的模式 ppp 中进行了完整交付(Full Delivery),则 αi,r,pF=1\alpha^F_{i,r,p} = 1αi,r,pF=1,否则为 0。
- αi,r,pSZ\alpha^{SZ}_{i,r,p}αi,r,pSZ 是二进制参数,表示如果客户 iii 在路径 rrr 的模式 ppp 中进行了拆分交付(Split Delivery)或零交付(Zero Delivery),则 αi,r,pSZ=1\alpha^{SZ}_{i,r,p} = 1αi,r,pSZ=1,否则为 0。
- θr,p\theta_{r,p}θr,p:表示模式 ppp 是否在路径 rrr 中使用的二进制参数。
-
右边:
- 222:表示每个客户 iii 在客户集合 VSV_SVS 中至少需要的车辆数。
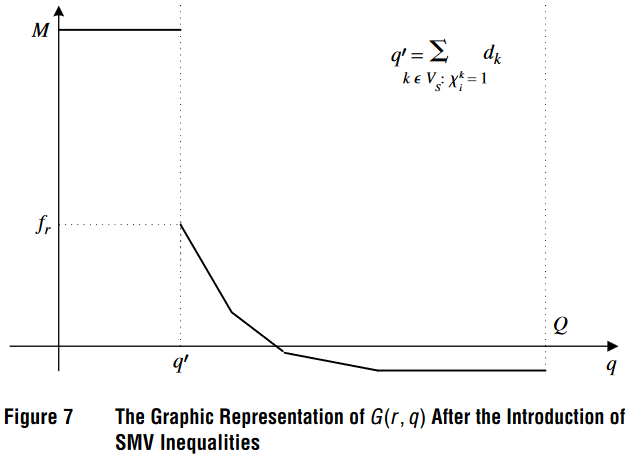
在考虑SMV 不等式时,上图展示在引入这些不等式后的图形结构和处理方式,这样的表示有助于理解如何在实际图中应用这些不等式以及如何调整路径搜索算法。
搜索策略
- 使用 最优优先策略(best-first policy)来探索分支定界树。
- 深度优先策略 在初步实验中结果不如最优优先策略。
分支策略
- 在每个分支定界节点上,通过列生成程序和分离启发式方法求解 LMP 的最优解,并将其作为下界。
- 分支策略:
- 总车辆数
- 每个客户的车辆数
- 每条边的总流量
- 包括或不包括两个连续的边
我们来个简单整理:
-
kkk-路径不等式 和 SMV 不等式 用于改进带时间窗的集成配送问题的解决方案,通过调整标签设定算法和简化成本函数。
-
搜索策略 和 分支策略 确保在求解过程中尽可能高效地找到最优解。
由于路径集合 RRR 过于庞大,直接求解 SF 是不切实际的。为了解决这一问题,文中采用了 CG 算法,它是一种迭代过程,交替求解 SF 公式的线性规划 LP 松弛问题和定价子问题。 -
通过松弛约束,允许 0≤θr≤10 \leq \theta_r \leq 10≤θr≤1(对于每个 θr∈R\theta_r ∈ Rθr∈R),从而得到线性主问题 LMP 。然后,通过选择初始列的集合 Ω⊆R\Omega \subseteq RΩ⊆R,得到受限线性主问题 RLMP ,并在每次迭代中更新该集合。CG 方法的目的是在每次迭代中找到负的reduced cost,并将它们纳入 RLMP。当找不到这样的列时,过程终止。如果 CG 结束时的线性解是可行的,那么它对于 LMP 和 RLMP 都是最优的。
-
每个 RLMP 的解都有对应的对偶解,这些对偶值在 reduced cost 函数中起到关键作用,用于更新路径集合 Ω\OmegaΩ。通常,BPC 过程从一组初始列开始,为标签设置算法后续迭代提供上限。在这个情况下,即使 Ω=∅\Omega = ∅Ω=∅ ,SF 仍然是可行的,这意味着在解决定价子问题之前不需要生成初始列。
这里比较复杂,涉及的技术比较多,可能需要大家多看几次才会理解清楚哦(我也看了不止一次。。。)
4. 算法优势
实例
作者们使用了Solomon(1987)提出的56个基准VRPTW实例,这些实例分为六个组:R1、C1、RC1、R2、C2和RC2。每个Solomon实例包含一个仓库和100个客户,总共101个顶点。我们从这些100客户的实例中派生出了25客户和50客户的实例,总共形成504个实例,分为54组。每个实例组的标识符由Solomon实例组的名称、客户数量 n 和车辆容量 Q 组成。例如,实例组R1-100-30包含n = 100和Q = 30的R1组实例。距离被四舍五入到小数点后一位。权重相关成本函数为 f(w)=a×w+bf(w) = a \times w + bf(w)=a×w+b,其中 a=1a = 1a=1 和 b=Q/4b = Q/4b=Q/4。
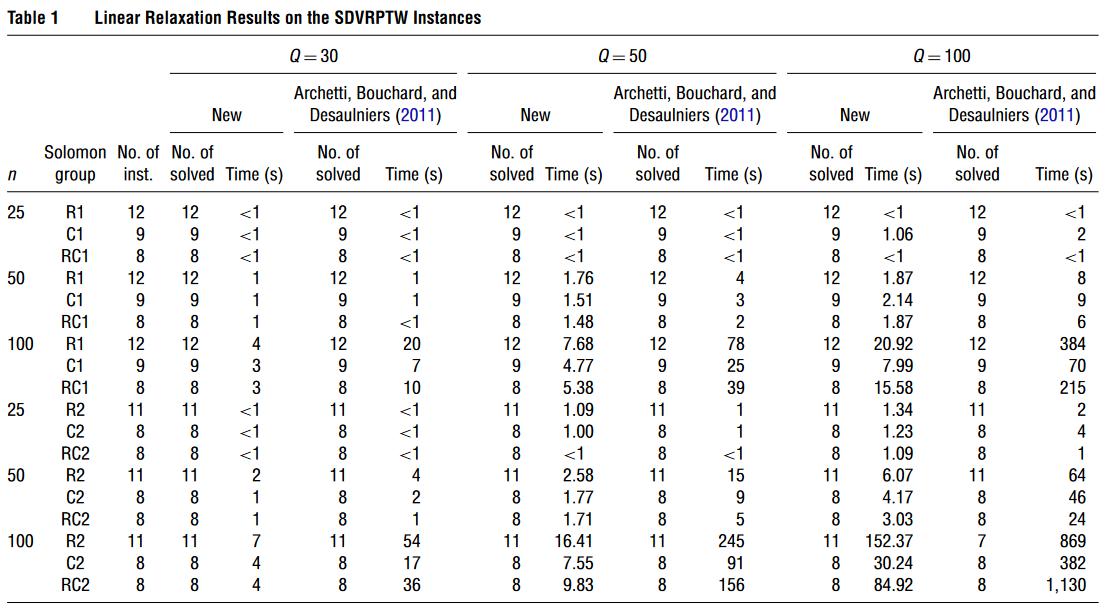
SDVRPTWL 实例的结果
作者们将 BPC 算法应用于所有 SDVRPTWL 实例,这些实例的距离矩阵经过了满足三角不等式的更新。
在算法开始时,他们解决了包含所有 n 个 SMV 不等式但不考虑 kkk-path不等式的 MP 的线性松弛。
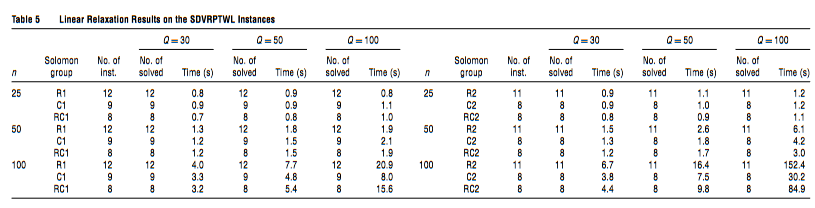
Table5Table 5Table5 中报告了线性松弛的结果,表明为每个实例达到了下界。
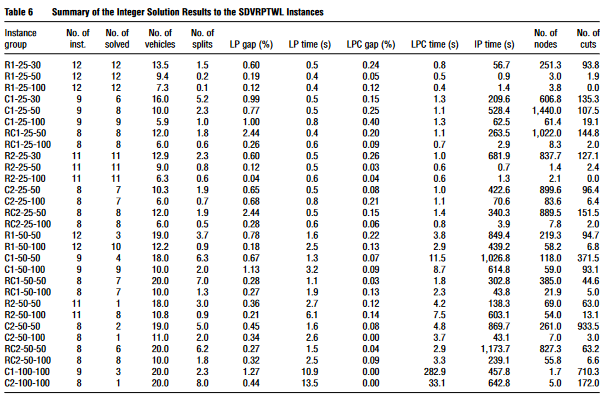
Table6Table 6Table6 总结了SDVRPTWL实例的整数解结果。得出作者们设计的算法成功解决了504个SDVRPTWL实例中的208个,其中138个、66个和4个实例包含25、50和100个客户。
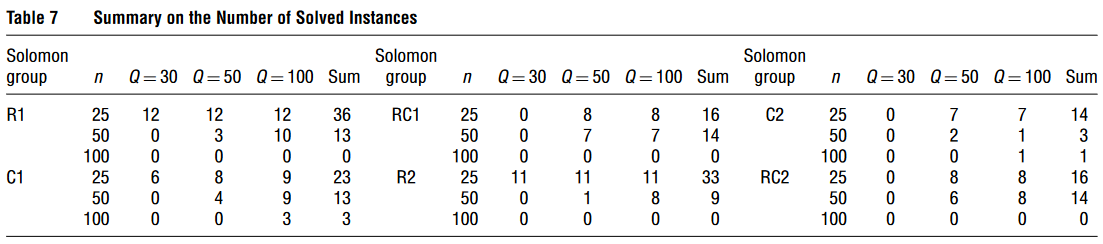
Table7Table 7Table7 展示了各实例组中最优解实例的数量。
按照上述结果,非常显然,这个 BPC 算法表现非常好。
-
计算效率:
- SDVRPTW 实例:算法在SDVRPTW实例中表现出较短的计算时间,尤其是在分支定价剪枝算法的根节点解决LMP时,比之前的方法(如Archetti、Bouchard及Desaulniers(2011))平均计算时间显著更短。
- SDVRPTWL 实例:算法同样成功解决了208个SDVRPTWL实例,其中许多实例在更短的时间内得到了最优解。
-
准确性:
- SDVRPTW 实例:算法在所有测试实例的根节点成功找到了 LMP 的最优解。相较于Archetti、Bouchard及Desaulniers(2011)的方法,算法解决了更多的实例,并且能够找到在一些情况下没有被报告的最优解。
- SDVRPTWL 实例:该算法还成功解决了208个 SDVRPTWL 实例,显示了较强的准确性和可靠性。
-
方法对比:
- 在列生成程序的比较中,使用 AGH 列生成器的CG1程序比Archetti的标签扩展算法表现更好。
- 双向搜索的有效性也得到了验证,进一步提升了算法的性能。
-
实例分类:
- 算法在解决不同类别的实例中表现优异,包括那些之前未能找到最优解的实例。
怎么样?是不是很神奇呢?哈哈哈哈哈是的,这也许就是我们喜欢研究这个领域的原因~~~这一篇 TS 的文章真的真的真的十分强大!!!喜欢算法设计的人必看!!!
今天的分享到这里结束咯。不知道你看明白了吗 ~~~
(看得懂或看不懂的小伙伴记得点赞收藏慢慢看多几次哦)
参考文献:
原论文:
Luo, Z., Qin, H., Zhu, W., & Lim, A. (2017). Branch and price and cut for the split-delivery vehicle routing problem with time windows and linear weight-related cost. Transportation Science, 51(2), 668-687.

















 1709
1709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









