




 本文深入探讨了JDBC的工作流程,包括初始化、连接、预处理语句及其优势。详细讲解了MySQL的InnoDB引擎特性,如缓冲池、日志系统、数据存储方式和索引机制,包括B+树和自适应哈希索引。此外,还介绍了事务隔离级别、锁机制、数据库备份恢复策略以及主从复制、读写分离和负载均衡技术。
本文深入探讨了JDBC的工作流程,包括初始化、连接、预处理语句及其优势。详细讲解了MySQL的InnoDB引擎特性,如缓冲池、日志系统、数据存储方式和索引机制,包括B+树和自适应哈希索引。此外,还介绍了事务隔离级别、锁机制、数据库备份恢复策略以及主从复制、读写分离和负载均衡技术。
JDBC
1、过程:java-mysql-connector.jar\初始化驱动class.forname()\建立连接sql.DriverManager.getconnection(IP、端口、名称、账号密码)\建立statement、prestatement\执行sql语句、s.execute(sql)、
2、prestatement有点:1、参数设置,不易出错,可以防止SQL注入。2、预编译,将SQL命令编译放在命令缓冲区,多次SQL只需要一次SQL语句传到数据库端,然后进行性解析。性能比statement高。
3、
MYSQL
1、innodb引擎
1.1缓冲池
1、innodb引擎可以实现表级和行级锁,innodb存储引擎是多线程的模型
2、缓冲池就是一块内存区域 ,在数据库中进行读取页的操作 首先将从磁盘读到页存放在缓冲池中,下一次在读相同的页时 首先判断页是否在缓冲池中 若在缓冲池中 该页在缓冲池中被命中 直接读取该页 否则读取 磁盘上的页
3、对于数据库中页的修改操作 则首先修改在缓冲池中的页 然后再以一定的频率刷新到磁盘上 这里需要注意的是 页从缓冲池刷新回磁盘的操作并不是在每次页发生更新时触发 而是通过一种称为checkpoint的机制刷新回磁盘 ,缓冲池的大小直接影响着数据库的整体性能
4、缓冲池缓存的数据页的类型有:索引页 数据页 undo页 插入缓冲(insert buffer) 自适应哈希索引(adaptive hash index) innodb存储锁信息(lock info) 数据字典信息(data dictionary)等 缓冲池不只是缓存索引页和数据页 他们只是占缓冲池很大的一部分而已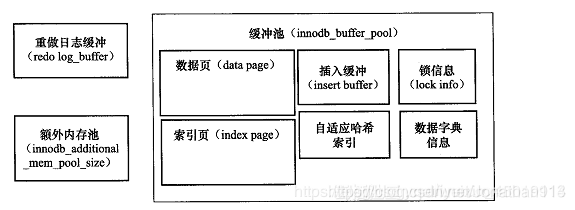
1.2日志系统总结
MySQL中的重做日志(redo log),回滚日志(undo log),以及二进制日志(binlog)
1.3 MySQL中数据存储
- 各个数据页可以组成一个双向链表
- 每个数据页中的记录又可以组成一个单向链表
- 每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
- 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
- 如果我们写select * from user where username = 'Java3y’这样没有进行任何优化的sql语句,默认会这样做:全表遍历
页与页之间是双向链表,页内是单链表。需要沿着双向链表,从第一页开始,依次遍历每一页,最终找到对应的数据
1.4 索引
索引分类:1、自适应hash索引,2、B+树索引
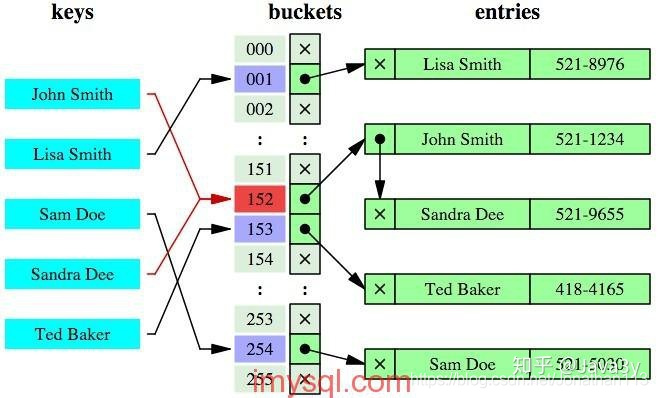
1.4.1自适应hash索引
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
缺点:
哈希索引也没办法利用索引完成排序
不支持最左匹配原则
在有大量重复键值情况下,哈希索引的效率也是极低的---->哈希碰撞问题。
不支持范围查询
1.4.2B+树索引
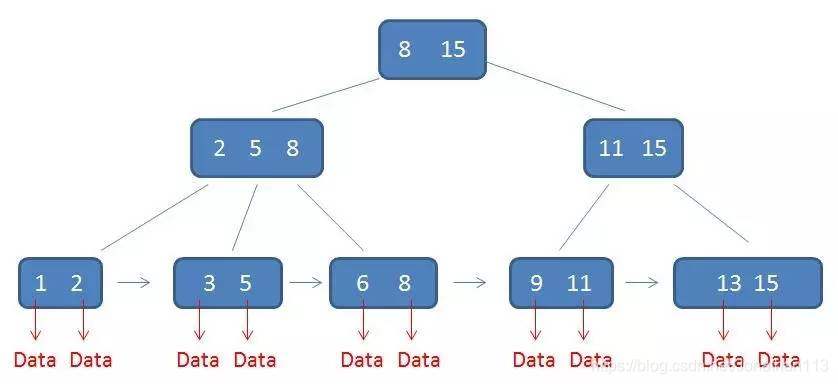
B+树索引底层用的是B+数
B+数简介:m阶B+数
1、有k个子树的中间节点包含有k个元素,每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。中间节点包含有k个元素,子树的元素为K+1
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。所以是有序的,树的遍历就是先找到最小的子节点,然后向右遍历(叶子之间由指针连接)就可以实现。
4、子树最多为m
综上:
- B+数做索引可以实现排序,
- 单一节点存储更多的元素,使得查询的IO次数更少
- 所有查询都要查找到叶子节点,查询性能稳定。
- 所有叶子节点形成有序链表,便于范围查询。
1.4.3 聚集索引和二级索引
聚集索引就是以主键创建的索引
非聚集索引就是以非主键创建的索引
聚集索引在叶子节点存储的是表中的数据
非聚集索引在叶子节点存储的是主键和索引列
使用非聚集索引查询出数据时,拿到叶子上的主键再去查到想要查找的数据。(拿到主键再查找这个过程叫做回表)
在创建多列索引中也涉及到了一种特殊的索引–>覆盖索引
比如说:现在我创建了索引(username,age),在查询数据的时候:select username , age from user where username = ‘Java3y’ and age = 20。很明显地知道,我们上边的查询是走索引的,并且,要查询出的列在叶子节点都存在!所以,就不用回表了~
1.4.4组合索引
组合索引即多个关键字联合建立索引,他们的建就是字段值,所以不需要回表,如果只有一个索引,查询三个字段,那么会先用索引查询满足第一个字段的数据,然后回表查询第2和3个字段,最后排序等操作,而建立组合索引(覆盖索引),一次索引查询,且排序好了。排序根据如下的最左原则。
组合索引和最左原则
1.4事务隔离级别
//设置mysql的隔离级别:
set session transaction isolation level 设置事务隔离级别
//设置read uncommitted级别:
set session transaction isolation level read uncommitted;
//设置read committed级别:
set session transaction isolation level read committed;
//设置repeatable read级别:
set session transaction isolation level repeatable read;
//设置serializable级别:
set session transaction isolation level serializable;
1.6锁
1.7数据库备份和恢复
数据备份和恢复是用mysqldump+二进制日志binlog实现的。sql文件备份数据,binlog记录备份后数据库的操作。
数据库备份:全量备份,增量备份 就可以实现完整数据库恢复
MySQLdump增量备份配置
执行增量备份的前提条件是MySQL打开binlog日志功能,在my.cnf\ini中[mysqld]加入:
og-bin=mysql-bin
server-id=1
Innodb 的mysqldump全量备份 + mysqlbinlog二进制日志增量备份mysqldump命令必须带上–flush-logs选项以生成新的二进制日志文件:
mysqldump --single-transaction --flush-logs --master-data=2 -u root -p test > backup_sunday_1_PM.sql对于MyISAM将–single-transaction替换为–lock-all-tables
–flush-logs为结束当前日志,生成新日志文件;
–master-data=2 选项将会在输出SQL中记录下完全备份后新日志文件的名称;
–master-data=[0|1|2]
0 : 不记录
1 : 记录为CHANGE MASTER语句
2 : 记录为注释的CHANGE MASTER语句
添加链接描述
添加链接描述
1.8 主从复制
1.9 读写分离和负载均衡、高可用(keepalive)
读写分离就是根据不同的method来选择不同的数据源,其实现有两种:
负载均衡和读写分离技术
1、手动实现读写分离和轮询salve负载均衡,这样实现简单,但是如果增加或改变数据源需要修改spring配置和代码:AOP拦截,实现before方法,根据service和方法设定该线程用的数据源代号(枚举),然后通过工具类存在threadlocal中,并将数据源放入事务管理器,然后根据路由数据源来进行获得该线程的数据源,再把数据源@resource注入mybatis配置中,就可以实现数据源的动态获取
手动代码读写分离的实现
2、代理服务器实现mycat:,加上keepalive更可以实现主备高可用(在两台服务其上分别都安装keepalive(设置主备)、加上haproxy还可以集群mycat实现高可用和负载均衡)
mycat读写分离实现

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









