




 本文详细介绍了MySQL主从复制的延时同步机制,包括延时同步原理、产生原因、配置方法以及实际操作中的故障恢复步骤,涉及环境准备、GTID复制、主从配置和恢复实例,助您理解并应对数据库同步延迟问题。
本文详细介绍了MySQL主从复制的延时同步机制,包括延时同步原理、产生原因、配置方法以及实际操作中的故障恢复步骤,涉及环境准备、GTID复制、主从配置和恢复实例,助您理解并应对数据库同步延迟问题。
MySQL主从复制【延时同步】(GTID复制基础上)
1、延时同步
单纯从名字就可以大致明白其中的原理,就是当主库进行某些更新操作时,从库不会立即进行同步操作,而是等待管理员设定的延时到时,才与主库进行同步。
2、延时同步产生原因
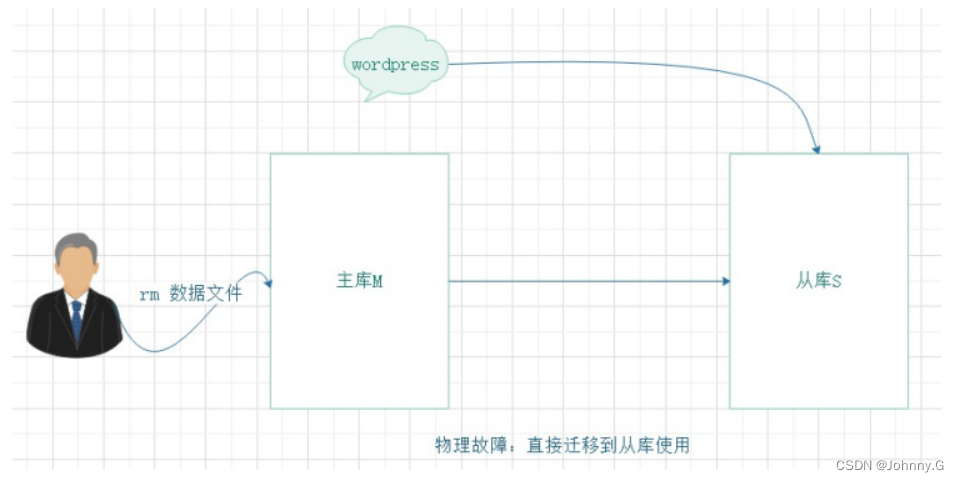
现实生产环境中,数据库发生故障是不可避免的,具体分为:
- 物理损坏:主库 rm 误删除数据库数据,直接将应用切换到从库;
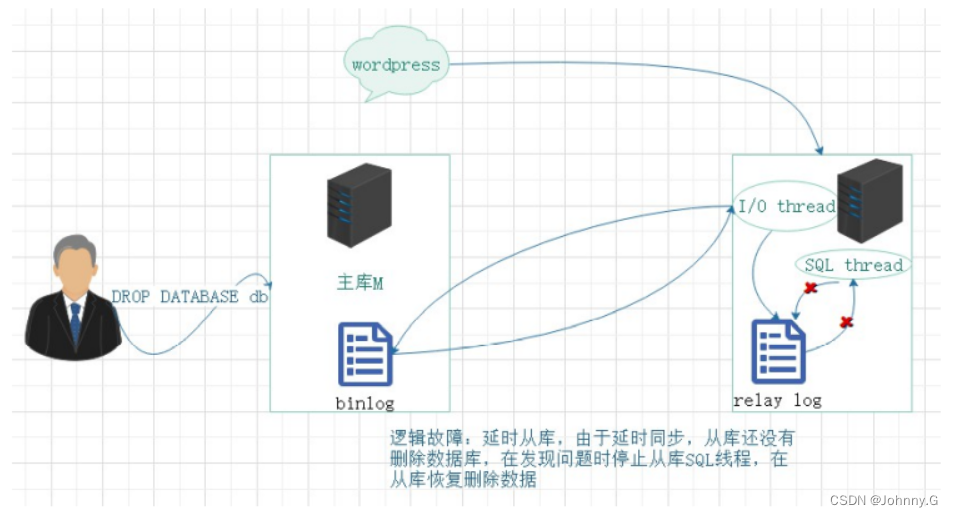
- 逻辑损坏:主库 drop database dbname、主库 delete from tablename,直接将语句同步到从库;
3、延时同步配置
mysql> stop slave; #关闭主从同步
mysql> CHANGE MASTER TO MASTER_DELAY = 300; #更改延时时间300秒(默认为0)
mysql> start slave; #开启主从同步
mysql> show slave status \G #对应参数
SQL_Delay: 300 #延时时间(此处为5分钟,默认为0)
SQL_Remaining_Delay: NULL #延时同步状态值(等待时为非负整数值,非等待时为NULL)
4、示例
1)环境准备
三台主机:一主、两从
主库(MySQL master)[ip为192.168.25.131]
从库(MySQL slave1)[ip为192.168.25.133]
从库(MySQL slave2)[ip为192.168.25.134]
2)故障恢复思路:
从库延时5分钟,主库误删除1个库
1> 5分钟之内 侦测到误删除操作
2> 停从库SQL线程
3> 截取relaylog
起点:停止SQL线程时,relay-log最后的应用位置
终点:误删除操作的前一个position(GTID)
4> 恢复截取的日志到从库
5> 从库身份解除,替代主库工作
3)主库配置
略【依据上篇博客(GTID复制)】
4)从库配置
略【依据上篇博客(GTID复制)】
补充配置
db03 [(none)] > stop slave;
Query OK, 0 rows affected (0.00 sec)
db03 [(none)] > CHANGE MASTER TO MASTER_DELAY = 300;
Query OK, 0 rows affected (0.00 sec)
db03 [(none)] > start slave;
Query OK, 0 rows affected (0.00 sec)
db03 [(none)] > show slave status\G #查看结果
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.25.131
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 194
Relay_Log_File: localhost-relay-bin.000002 #中继日志文件名(重要)【恢复时使用】
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 194
Relay_Log_Space: 578
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 131
Master_UUID: 4a4ec55f-d078-11ec-b9e8-000c29c1f77e
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 300 #延时时间为5分钟
SQL_Remaining_Delay: NULL #延时同步状态值(等待时为非负整数值,非等待时为NULL)
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 4a4ec55f-d078-11ec-b9e8-000c29c1f77e:1-6,
5fe99a5e-d078-11ec-956b-000c294d6b8d:1
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
5)主库数据操作 & 从库观察
db01 [(none)] > create database relay charset utf8; #创建relay库
Query OK, 1 row affected (0.00 sec)
db01 [relay] > show databases; #主库查看数据库
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| relay |
| sys |
+--------------------+
5 rows in set (0.00 sec)
db02 [(none)] > show databases; #从库(slave1)查看数据库
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| relay |
| sys |
+--------------------+
5 rows in set (0.05 sec)
db03 [(none)] > show databases; #从库(slave2)查看数据库
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.01 sec)
#可以发现配置延时同步后,数据没有及时与主库同步(没有relay库)
db01 [(none)] > use relay #切换至relay库
Database changed
db01 [relay] > create table t1(id int); #创建t1表
Query OK, 0 rows affected (0.01 sec)
db01 [relay] > show tables; #此步骤可以省略,因为slave2无法同步(100%没有这些数据)
+-----------------+
| Tables_in_relay |
+-----------------+
| t1 |
+-----------------+
1 row in set (0.00 sec)
db02 [relay] > show tables; #此步骤可以省略,因为slave2无法同步(100%没有这些数据)
+-----------------+
| Tables_in_relay |
+-----------------+
| t1 |
+-----------------+
1 row in set (0.00 sec)
db01 [relay] > insert into t1 value(1),(2); #为t1表插入数据
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
db01 [relay] > select * from t1; #此步骤可以省略,因为slave2无法同步(100%没有这些数据)
+------+
| id |
+------+
| 1 |
| 2 |
+------+
2 rows in set (0.00 sec)
db02 [relay] > select * from t1; #此步骤可以省略,因为slave2无法同步(100%没有这些数据)
+------+
| id |
+------+
| 1 |
| 2 |
+-- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









