







神经搜索的最大竞争者可能来自于一种甚至不需要向量嵌入作为中间表示的技术 —— 一种直接返回你想要的结果的端到端技术。
"那么,谁将是神经搜索最大的竞争对手?"
本文作者:肖涵,Jina AI 创始人兼 CEO
谁将是神经搜索最大的竞争对手?
就在 2019 年的圣诞节前几天,我坐在一个狭小的会议室里,周围是我们种子风投公司的投资委员会。我们已经在办公室待了几个小时,来回地讨论。这是最后一轮令人紧张的路演,以确保我的神经搜索倡议获得所需的 200 万美元的孵化资金:Jina AI 的诞生就悬在一线,这是一个成败攸关的时刻。
其中一位从 2005 年就在纽约谷歌工作的合伙人问了我一个我永远不会忘记的问题:
"谁将是您最大的竞争者?"
“谷歌,Elastic,Algolia,……” 我自信地回答道,这是我早前准备过的问题。然后我咬紧牙关,只是等着他们问我那些无聊的陈词滥调的问题,比如“你怎么与谷歌竞争?”在他们回答之前,我补充说:“但更严峻的竞争可能来自一项不需要嵌入作为中间表示的技术 —— 一项端到端技术,它能直接返回您想要的结果。”
但他们没有听懂我的意思,他们坚持着那些老套问题。一直在追问我如何与谷歌竞争。
3 年过去,时间和“常识”都已经发生改变,他们理解了我所说的技术。
这项技术就是 生成式人工智能,而 神经搜索是判别式人工智能。
在那时,也就是在谷歌发布 BERT 的 15 个月后,生成式人工智能还不是可扩展且高质量搜索的答案。而神经搜索是一个灵活的框架,它可以轻松地使用密集的嵌入表示,并结合多个子任务,是当时搜索多模态数据的唯一现实的方法。
多模态人工智能异军突起
自 2021 年以来,我们在行业中看到了从单模态人工智能到多模态人工智能的巨大范式变革:
Jina AI愿景中的未来AI应用
多模态人工智能的兴起归功于近几年机器学习技术的进步:表征学习和迁移学习。
-
• 表征学习使模型为所有模态创建共同的表征。
-
• 迁移学习使模型首先学习基本知识,然后在特定领域进行微调来改进学习。
2021 年,我们看到了 CLIP,一种捕获图像和文本之间对齐关系的模型;2022 年,DALL·E 2 和 Imgen 通过文本提示生成了高质量的图像。由 Stable Diffusion 领导的 AI 生成艺术从一个社区嘉年华开始,现在已经演变成一场工业革命。这是一座刚刚探出头的巨大冰山。在未来,我们将看到更多 AI 应用超越单一数据模态,利用不同模态之间的关系。临时方法正在像恐龙一样消失,因为数据模态之间的界限变得模糊无意义。
但是,在开始想象花哨的高级人工智能应用之前,有两个基本问题我们必须先解决:搜索和生成。
或者我应该说,搜索,还是生成?
搜索和生成的二元性
搜索和生成是一枚硬币的两面,是一种二元性。
为了理解这一点,让我们以 text-to-image 和 image-to-image 为例,看看以下两个函数:
def foo(query: str) -> List[Image]:
...
def bar(query: Image) -> List[Image]:
...那么,foo 和 bar 是什么?
-
• 当它们是搜索时,
foo表示以文搜图(CBIR),bar表示以图搜图。 -
• 当它们是生成时,
foo表示从文本提示 Prompt 到 AI 生成图像,bar指的是从初始图片到 AI 生成图像。
那么,你能分辨下面的区别吗?搜索结果是哪个,AI 生成的结果是哪个?以及这真的重要吗?搜索是找到你需要的东西;AI 生成是制作你需要的东西。如果一个系统返回了你需要的结果,它是来自搜索还是 AI 生成,这真的重要呢?
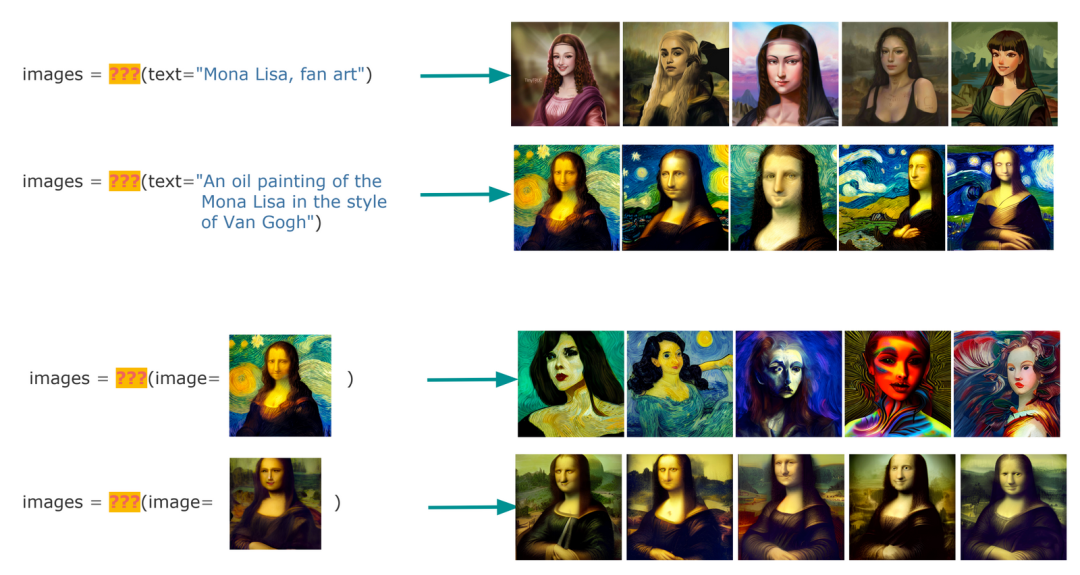
"嗯,但是数据库的完整性确实很重要," 你可能会反驳。"因为我不想在我的商品搜索结果中看到虚构的商品图像。" 有时人们确实关心数据库的准确性,但解决它很容易,我们只需要过拟合一个生成式人工智能模型。我们可以让模型记住它在训练数据中看到的所有内容,失去所有普遍性和泛化能力。它只会返回训练数据中的内容。你看,这样你就拥有了一个可靠的搜索系统。
生成式人工智能会使这种压抑性限制得到缓解。让模型即兴创作,让我们拥抱随机性,让感觉胜过保真性。生成式 AI 只是一个欠拟合的搜索系统。
硬币不断旋转着,它最终会落在哪边?它还重要吗?
总结
随着越来越多的大型语言模型(LLM)和生成人工智能的兴起,使用 LLM,特别是预训练的语言模型(PTLM),已经成为一种流行的机制,可以根据需要从自由形式文本中提取知识。尽管语料库中存在报告偏差问题,并且对查询缺乏鲁棒性,但 LLM 在一些相当成功的下游任务,比如基于人格的对话、叙事故事生成和隐喻生成。COLING 2022 最近也有一项工作,探索了像 CLIP 这样的跨模态模型作为常识知识库。你可以在这里找到我关于这篇论文的笔记。https://jina.ai/news/coling2022/

Are Visual-Linguistic Models Commonsense Knowledge Bases?
在写这篇文章的前一天,我读到 Yann LeCun 的推文,讲述了 Galactica —— 一个具有搜索界面的生成式人工智能:
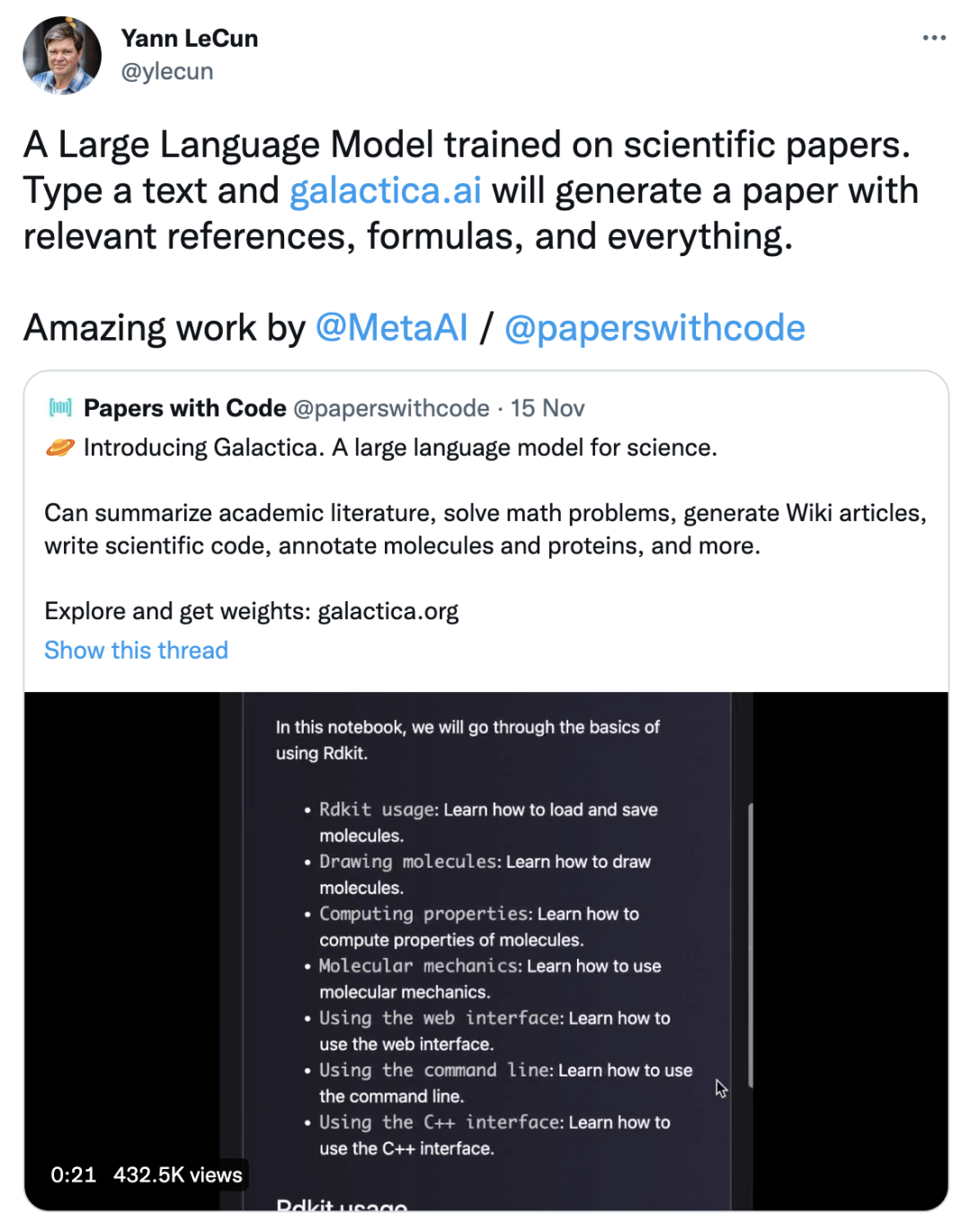
从快速测试的效果来看,它在模仿学术语气方面做得不错,但很快就偏离了主题,并且领域知识有限。尽管如此,这对于生成人工智能来说仍是一个里程碑。
我们抛出硬币,看着它在空中翻滚,一端接着一端翻转。我们的目光从未从它的轨迹上移开。当它到达弧线的顶点时,我们都知道结果不再重要。
拓展资料
💻 GitHub: get.jina.ai
📖 文档:docs.jina.ai
🔗 原文链接:https://jina.ai/news/search-is-overfitted-create-create-is-underfitted-search/

















 3564
3564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









