







 介绍以3D模型搜索3D模型的技术,利用深度学习优化3D物体表征,支持3D物体的分类、搜索和管理。
介绍以3D模型搜索3D模型的技术,利用深度学习优化3D物体表征,支持3D物体的分类、搜索和管理。

以型搜型指的是 以3D模型搜索3D模型,在对 3D 物体进行模型表征后,通过最近邻搜索得到与之类似的3D物体的结果。Executor-3d-encoder 项目集成了若干个 3D 物体表征模型,开发者可以很方便地对不同的模型进行统一配置、训练和微调。
12 月 6 日晚 7:00,我们邀请到了负责本项目的 刘畅,来分享《3D模型表征助力3D神经搜索》。
项目作者介绍
刘畅,Jina AI 开源社区贡献者。清华大学计算机系本科毕业,北京大学软件工程硕士一年级在读。
JinaAI
🔍 以型搜型挑战!
30分钟带你了解神经搜索在3D场景的应用!
分享项目简介
项目名称:3D 模型表征助力 3D 神经搜索
项目描述:3D 物体的表征形式多种多样,其中一个比较典型的方法是 3D 点云,即某个坐标系下的点的数据集。相比于文本、图像,其包含了物体更加丰富的信息,包括三维坐标 X,Y,Z、颜色、分类值、强度值、时间等等。
3D 物体的比较典型的应用场景就是元宇宙,其中存在着大量的数字 3D 模型。精确建模与理解这些虚拟物体可以帮助我们更好的实现对 3D 模型进行分类,搜索,以及管理。
目前我们已经对一些 3D 物体模型的预训练模型进行了封装,并且支持对模型的微调 (Finetune),使得用户可以更加便捷地将这些模型应用到实际生产环境中。为了更好的适应具体使用场景,针对预训练模型的微调通常会使用表征学习。
表征学习 (Representation Learning) 是深度学习的一个分支,其广泛应用于工业界,它通过训练深度学习模型优化输入数据的向量表示,以适应相似度计算、检索、推荐等不同应用。将深度表征学习与 3D 模型数据结合可以将 3D 物体的特征更好地展现出来,以此支持各个领域下对 3D 物体数据的搜索需求。
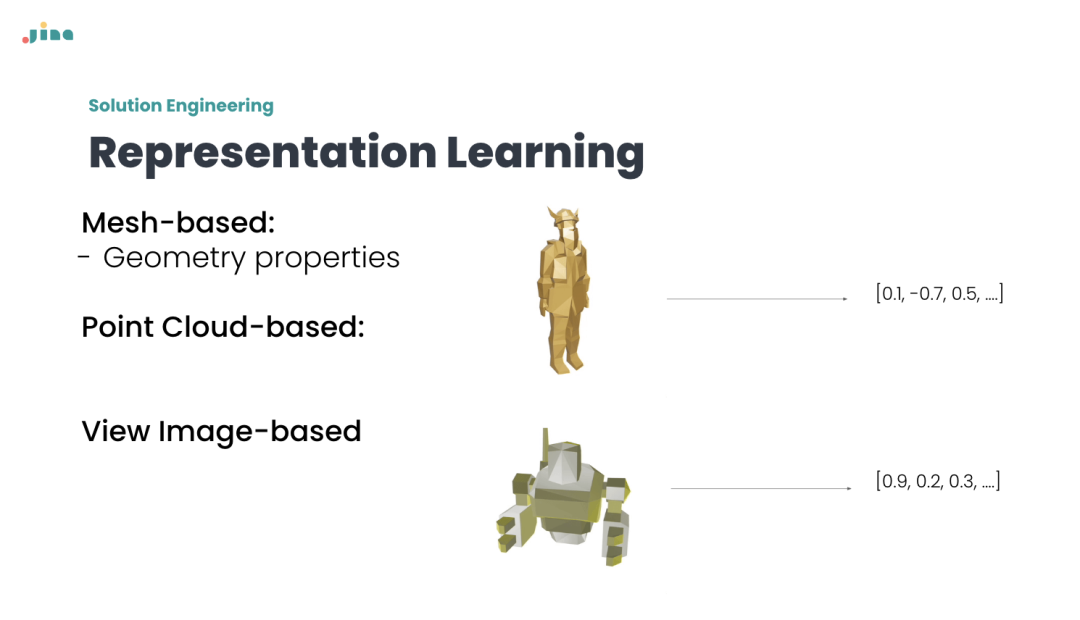
3D 物体表征模型通过深度学习方法得到 3D 物体对应的向量表征(也叫做 embedding),在该向量空间进行最近邻搜索(比如在 Lp 距离空间求 topk)可以得到与之类似的 3D 结果。Executor-3d-encoder 项目集成了若干个 3D 物体表征模型,方便开发者对不同的模型进行统一配置、训练和微调。
目前我们已经支持PointNet,PointConv,PointNet++,PointMLP,RepSurf 和Curvenet 模型,并在 ModelNet40 官方测试数据集上进行了基准测试,以下是我们的预训练模型在 3D 点云分类任务上的表现。
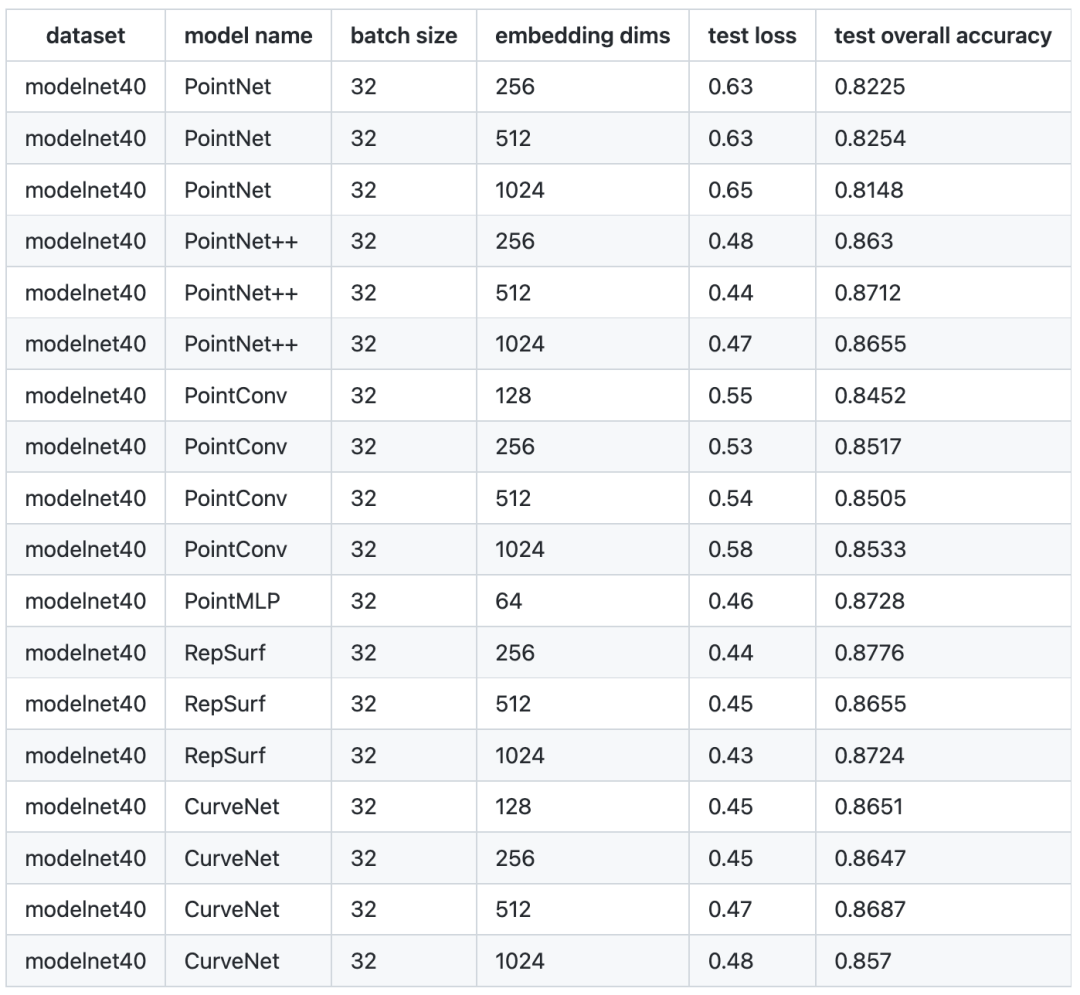
Benchmark
更多信息请访问本项目地址:
Github 地址:https://github.com/jina-ai/executor-3d-encoder
Jina Executor Hub:https://cloud.jina.ai/
开发者随访
Q(开源之夏小助手):嗨嗨,刘畅!这是你第几次参与开源之夏呀?
A(刘畅): 这是我第一次参加开源之夏。大概一两年前,我从一位留学的同学那里听说了 Google Summer of Code,在搜索相关信息的时候发现国内也有类似的活动。但之前的暑假都有小学期,不太有空,所以在大四毕业的暑假试着报了名。
Q(开源之夏小助手):开发过程中导师和社区给予了你怎样的帮助呢?
A(刘畅):前期调研阶段,我在阅读论文时因为前置知识不足导致有些地方理解不够到位,导师专门开了会议与我进行讨论。调研完成后,社区还给我提供了一次面向社区的英文 talk 机会, 让我有机会大胆展示自己的发现与结论。在后期的开发阶段,导师和社区里的其他成员也及时跟进我遇到的困难并加以讨论,让我能够顺利地完成本次项目开发。
Q(开源之夏小助手):你是从什么时候开始接触开源的?有什么特别的经历吗?
A(刘畅): 我是在大三的时候开始接触开源的,因为那时候才刚刚开始使用 GitHub,发现上面有很多好玩的项目。目前主要关注的还是和研究领域有关的仓库,平时遇到一些 bug 也会提一提 PR,如果自己的 PR 被 merge 了很有成就感。另外,在GitHub上遇到高质量的开源项目和积极回应的开源开发者是一件很幸福的事情,比如非常有活力的 Jina AI 团队。
Q(开源之夏小助手):开源对于你的专业提升有什么帮助?或者说你的专业和参与开源是否是相辅相成的?
A(刘畅): 目前我个人在开源方面的贡献还不算多,大部分实习做的都是不能对外公开的工作。但在工作中确实也要参考很多开源框架的实现,并对不同的解决方案做相应的调研。另外前人开源出来的工作为我的专业学习提供了很多便利,因此我认为我的专业和开源是相辅相成的。
Q(开源之夏小助手):你认为在校生有哪些参与开源的方式?
A(刘畅):我觉得在校生完全可以自行探索GitHub上的项目,通过贡献代码加入某个团队;或者开源出自己的有意思的项目。参与开源的方式很多,参加开源之夏也是不错的选择。
直播分享
活动时间
2022 年 12 月 6 日,下周二,晚 19:00 - 19:45
报名方式
扫描下方二维码,即可加入活动交流群


















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









