







 超级会员免费看
超级会员免费看
 本文深入探讨了Apache Flink的核心概念,包括集群角色、TaskManager内存管理、资源管理中的Slot、Task和SubTask、窗口机制、时间语义与Watermark、并行度与Slot的区别、窄依赖与宽依赖、分区策略、数据交换效率、端到端状态一致性、重启策略、Flink + Kafka数据管道的Exactly-once语义、Flink的重要特点、ProcessFunction API及其使用,以及处理数据倾斜的策略。文章旨在帮助读者全面理解Flink的内在工作原理和优化技巧。
本文深入探讨了Apache Flink的核心概念,包括集群角色、TaskManager内存管理、资源管理中的Slot、Task和SubTask、窗口机制、时间语义与Watermark、并行度与Slot的区别、窄依赖与宽依赖、分区策略、数据交换效率、端到端状态一致性、重启策略、Flink + Kafka数据管道的Exactly-once语义、Flink的重要特点、ProcessFunction API及其使用,以及处理数据倾斜的策略。文章旨在帮助读者全面理解Flink的内在工作原理和优化技巧。
目录
3.Flink 资源管理中 Slot、Task 和SubTask的概念
11.Flink是如何保证端到端(end-to-end)状态一致性?
13.Flink + Kafka的数据管道系统(Kafka进、Kafka出)而言,各组件怎样保证Exactly-once语义呢?
15.2 TimerService 和 定时器(Timers)
19.Flink中的Window出现了数据倾斜,有什么解决办法
20. Flink中在使用聚合函数 GroupBy、Distinct、KeyBy 等函数时出现数据热点该如何解决
25.Flink中的Window出现了数据倾斜,有什么解决办法
1.Flink集群有哪些角色?各自有什么作用?
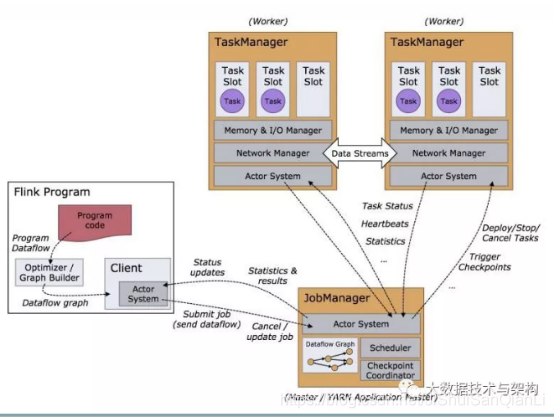
Flink 程序在运行时主要有 TaskManager,JobManager,Client三种角色。
JobManager

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











