



本项目利用爬虫技术来获取求职网站上的招聘信息,以便让求职更加高效。
一、项目要求
功能要求:
一、输入关键字,可列出区域、职务、工资。
二、列出对于此工作之额外要求,例如学历或是工作年限。
三、爬虫结果输出类型为JSON,或者储存在MongoDB
二、网站的选定与解析
在本次项目中,用户只需要在终端输入“职位关键字”,相对应的职位信息即可被爬取下来,并储存在本地MongoDB服务器内,供查看。
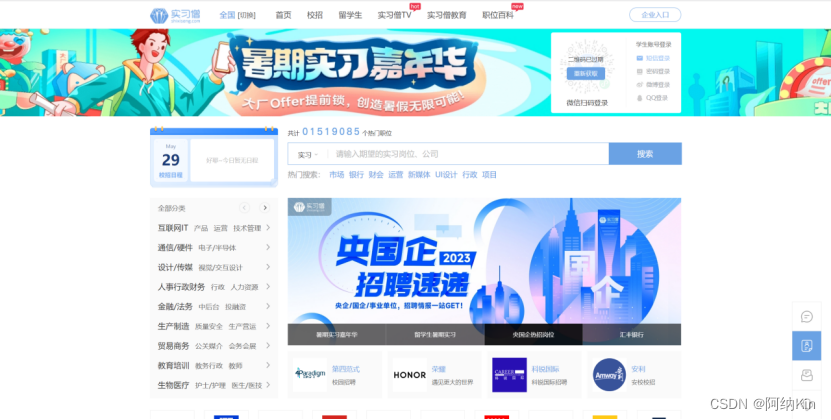
网站分析:
https://www.shixiseng.com/interns?page=2&type=intern&keyword=java&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%85%A8%E5%9B%BD&internExtend=
https://www.shixiseng.com/interns?page=3&type=intern&keyword=java&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%85%A8%E5%9B%BD&internExtend=
综合以上三个网址,可以得出以下规律:
page:1-不限
type:intern/school/company
keyword:不限
aera:None/根据城市来选择具体区(汉字)
months:None/1/2/3/4
days:None/1/2/3/4/5/6
degree:None/大专、本科、硕士、博士
offical:None/entry/noentry/notsure
enterprise:None/china500/IT300
salary:-0/0-100/100-150/150-200/200-300/300-
publishTime:None/day/wek/mon
sortType:None/zj
city:全国、南京、上海、北京、......
internExtend:None
因此,网址可以简化为(实习_实习生招聘信息 – 实习僧)
检查网页的结构和数据传输,发现传统的爬虫方法,也就是直接访问网址解析,不能直接爬取职位信息,因为实习僧网站有严格的反爬机制,爬虫爬下来的数据是一串未经解析的乱码,所以采用如下拼接的方法:
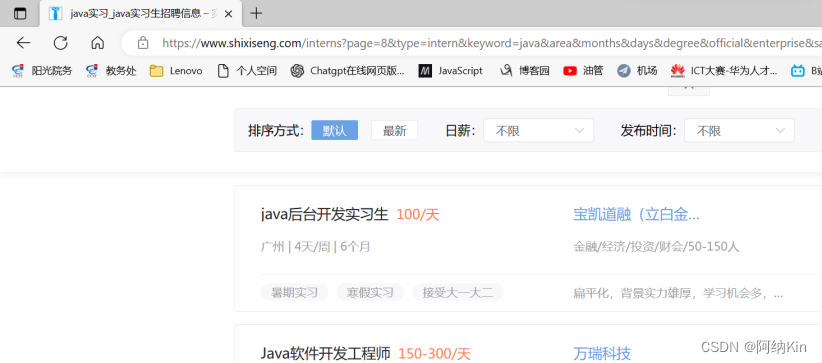
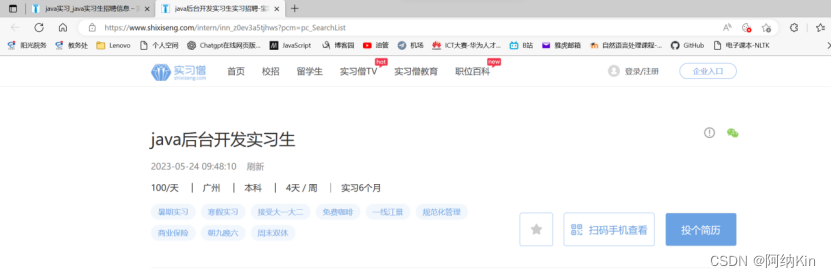
完成这样的操作,再去爬取页面的话,就不会出现乱码的情况,再去爬取数据就会出现正确的职位信息。
三、代码详解
- import requests
- from lxml import etree
- from urllib.parse import urlencode
- from pymongo import MongoClient
- # 连接MongoDB
- client = MongoClient('localhost', 27017)
- db = client['ShixiSeng']
- collection = db['ios']
- headers = {
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'}
- # 定义函数
- def send_requests(url):
- response = requests.get(url=url, headers=headers)
- return response.text
- def parse_html(data):
- tree = etree.HTML(data)
- div_list = tree.xpath('//div[@class="result-list clearfix"]//div[@class="f-l intern-detail__job"]')
- url_lst = []
- for di in div_list:
- new_url = di.xpath('.//a/@href') # 得到了每一个实习页面的url
- new_url = ''.join(new_url) # 进行格式的转换,将列表转换为字符串格式
- url_lst.append(new_url)
- print(url_lst)
- job_list = []
- for i in range(len(url_lst)): # 对新的url进行解析,爬取我们需要的薪水,公司的信息
- resp = requests.get(url=url_lst[i], headers=headers)
- tree = etree.HTML(resp.text)
- job_name = tree.xpath('//div[@class="new_job_name"]/span/text()')
- job_name = ''.join(job_name)
- # 职位名称
- job_address = tree.xpath('//div[@class="job_msg"]/span[@class="job_position"]/text()')
- job_address = ''.join(job_address)
- # 工作地点
- job_money = tree.xpath('//div[@class="job_msg"]/span[@class="job_money cutom_font"]/text()')
- job_money = ''.join(job_money)
- # 实习薪水
- company_name = tree.xpath('//a[@class="com-name"]/text()')
- company_name = ''.join(company_name)
- # 公司名称
- job_require = tree.xpath('//div[@class="job_msg"]//span[@class="job_academic"]/text()')
- job_require = ''.join(job_require)
- # 职位描述
- shixi_week = tree.xpath('//div[@class="job_msg"]/span[@class="job_week cutom_font"]/text()')
- shixi_week = ''.join(shixi_week)
- # 实习天数
- job_month = tree.xpath('//div[@class="job_msg"]/span[@class="job_time cutom_font"]/text()')
- job_month = ''.join(job_month)
- # 实习月数
- job_items = {
- "职位名称": job_name,
- "工作地点": job_address,
- "实习薪水": job_money,
- "公司名称": company_name.strip(), # 去除空格
- "工作要求": job_require,
- "实习天数": shixi_week,
- "实习月数": job_month
- }
- job_list.append(job_items)
- save_file(job_list)
- def save_file(job_list):
- collection.insert_many(job_list)
- if __name__ == '__main__':
- page_num = int(input('请输入需要爬取的页数:'))
- keyword = input('请输入搜索关键词:')
- job_list = []
- for page in range(1, page_num + 1):
- params = {
- 'keyword': keyword,
- 'page': page
- }
- url = 'https://www.shixiseng.com/interns?' + urlencode(params)
- data = send_requests(url)
- parse_html(data)
- if job_list:
- save_file(job_list)
项目所需的库:
Request: 发送HTTP请求,获取网络上的数据。
From lxml import etree: lxml库基于xml来解析HTML或XML格式的文本数据,提取我们需要的信息
From urllib import urlencode:使用urlencode()方法构造url中的查询字符串。
From pymongo import MongoClient: 用来连接MongoDB并对其进行增删改查等操作。
具体代码解释:
这段代码实现了对实习僧网站职位信息的爬取和存储。主要流程如下:
1. 输入需要爬取的页数和搜索关键词
2. 构造url,包含搜索关键词和页数参数
3. 发送请求,获取响应数据
4. 解析响应数据,提取职位链接url
5. 遍历职位链接,解析详情页,获取职位信息
6. 构造字典,存储解析得到的职位信息
7. 将所有职位信息存储在job_list列表中并保存到MonggoDB中。
8. 重复第2-8步,实现多页爬取
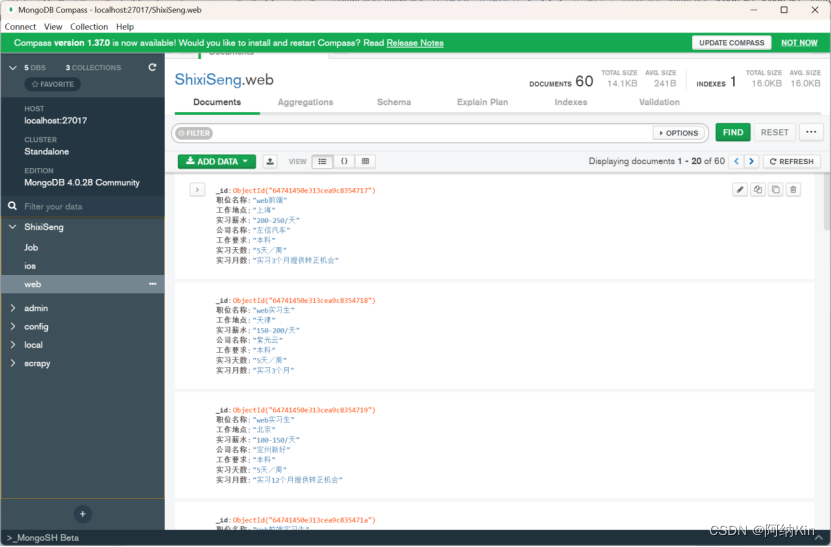
程序运行:
首先安装好MongoDB和MongoDB Compass,在cmd中输入’net start mongodb’
打开PyCharm,运行程序。
四、结果总结
本次项目是初级网络爬虫应用,在面对网站严格的反爬机制下,需要不断学习和摸索新技术,就需要学习反爬虫技术以及应对反反爬虫的反爬虫技术,代码具有时效性,网站结构的变化以及新反爬虫技术的应用,都需要重新编写代码爬取。
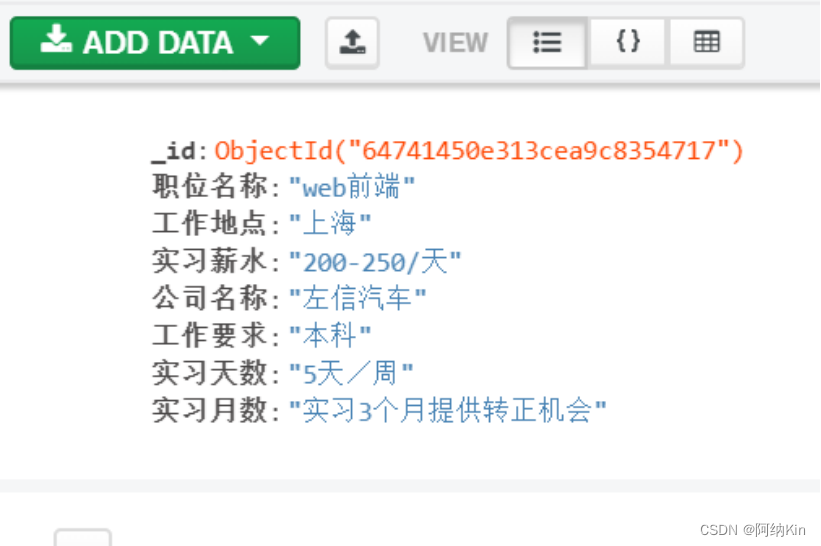
本次项目成功做到了用户在终端输入要爬取的页数和职位关键字,就可实现批量爬取数据的操作,最后的结果存储到本地MongoDB数据库中,代码运行顺畅。
项目功能实现:
- 输入关键字,可列出工作地点、职位名称、薪水
- 额外添加:公司名称、工作要求、实习天数、实习月数
- 额外添加:批量爬取,可以爬取多页的数据。
- 数据输出类型为json,并保存在MongoDB
本次项目仍然有许多需要改进的地方,在反爬虫操作上仍有很大进步空间,在数据清洗方面,仍有进步空间。

















 1945
1945




 到【灌水乐园】发言
到【灌水乐园】发言







