



 文章介绍了编程中的基本数据类型,包括整型家族(如char、int及其signed/unsigned类别)、浮点数(float、double)、构造类型(结构体、枚举、联合)和指针类型。详细阐述了整型的原、反、补码表示以及大小端字节序概念。同时,讨论了浮点数在内存中的IEEE754标准存储方式,包括指数和有效数字的处理。
文章介绍了编程中的基本数据类型,包括整型家族(如char、int及其signed/unsigned类别)、浮点数(float、double)、构造类型(结构体、枚举、联合)和指针类型。详细阐述了整型的原、反、补码表示以及大小端字节序概念。同时,讨论了浮点数在内存中的IEEE754标准存储方式,包括指数和有效数字的处理。
一、数据类型介绍
1.整型家族
char:unsigned char、signed char
short:unsigned short、signed short
int:unsigned int、signed int
long:unsigned long、signed long
值得注意的是,char类型也属于整型家族原因是:字符本质为ASCII值,是整型,所以划分到整型家族。另外char究竟是singed char还是unsigned char取决于编译器的底层实现。
2.浮点数家族
float、double、long double
3.构造类型
数组类型
结构体类型 struct
枚举类型 enum
联合类型 union
4.指针类型
int * 、char *、float*、void* ……
5.空类型
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型等
二、整型家族
1.原、反、补码
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”。
2.大小端字节序而数值位正数的原、反、补码都相同。负整数的三种表示方法各不相同。
原码:直接将整型数字按照正负数形式翻译成二进制,即可得到原码
反码:将原码的符号位不变,其他位依次按位取反即可得到反码
补码:将反码加一即可得到补码
所以,我们可以把原码补码的转换,符号位不变,其他按位取反再+1
2.大小端字节序
什么是大端小端:
大端(存储)模式:是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(存储)模式:是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
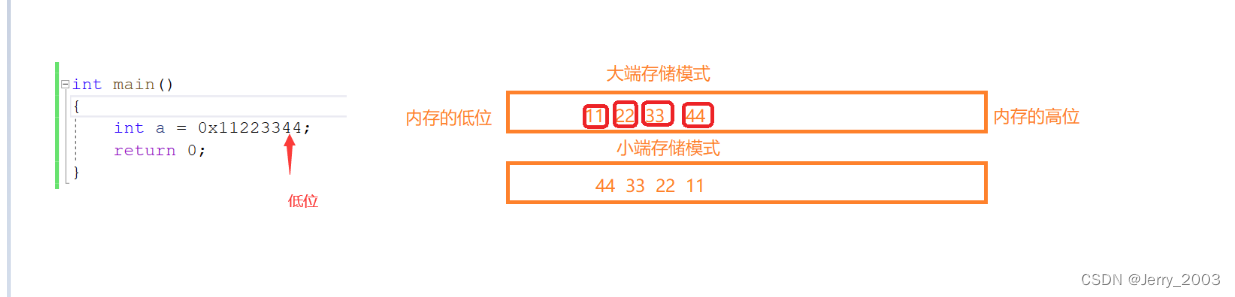
为什么说上面的是大端存储模式,下面是小端存储模式呢?
可以看见0x11223344 最后面的44是低位,然后在大端存储模式下44是放在内存的高地址位,根据上面的概念可以得出,大端模式,低位在内存的高地址存储就是大端模式。
为什么下面是小端存储模式:
0x11223344 44是放在内存的低地址处,根据上面的概念可以得出,小端模式,低位在内存的低地址存储就是小端模式。
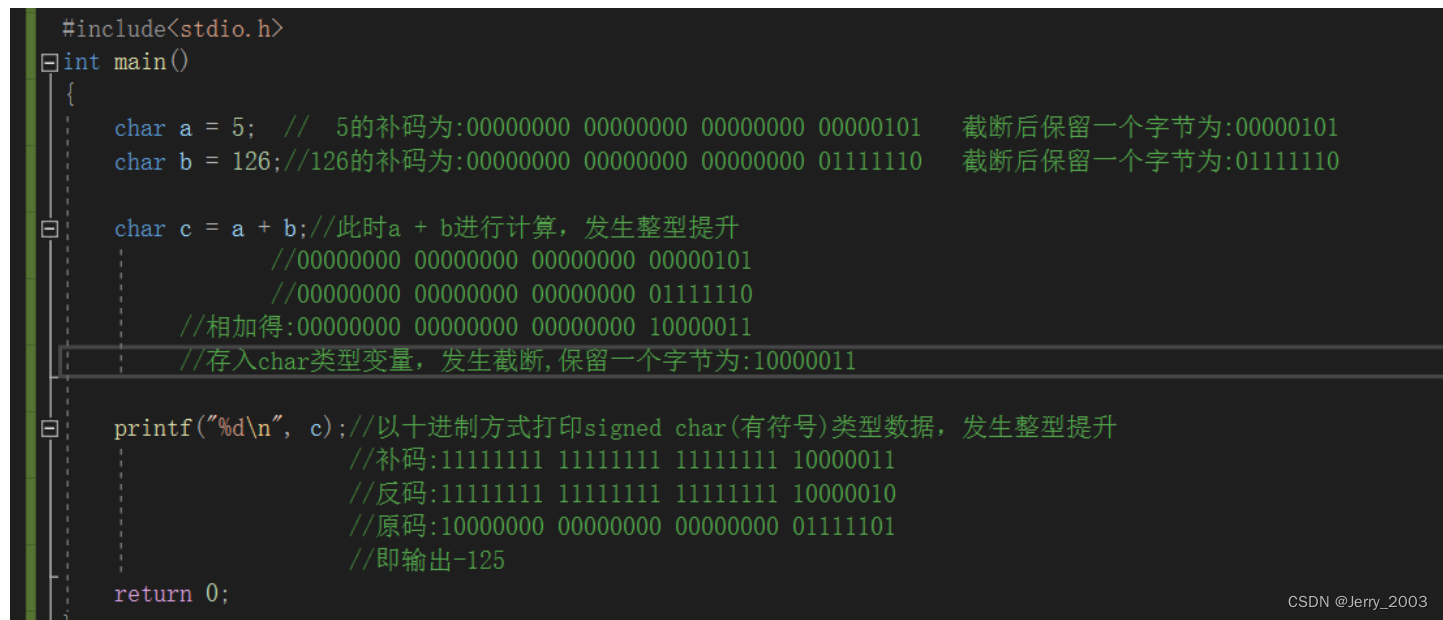
3.整型提升
C的整型算术运算总是至少以缺省整型(即默认整型)类型的精度来进行的。
为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型提升。
整型提升的意义:
表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器(ALU)的操作数的字节长度
一般就是int的字节长度,同时也是CPU的通用寄存器的长度。
因此,即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长
度。
通用CPU (general-purpose CPU) 是难以直接实现两个字节直接相加运算(虽然机器指令中可能有这种字节相加指令)。所以,表达式中各种长度可能小于int长度的整型值,都必须先转换为int或unsigned int,然后才能送入CPU去执行运算。
整型提升的规则:
整型提升是按照变量的数据类型的符号位来提升的,若无符号直接补0。
4.有无符号的数据区分
以char类型为例:
字符型数据char可分为unsigned char(无符号)和signed char(有符号)
具体char代表的是有符号字符型还是不符号字符型,取决于你编译器的具体实现。以VS2019为例,char所代表的便是signed char。
由此可见,signed char的取值范围是-128到127,unsigned char的范围是255.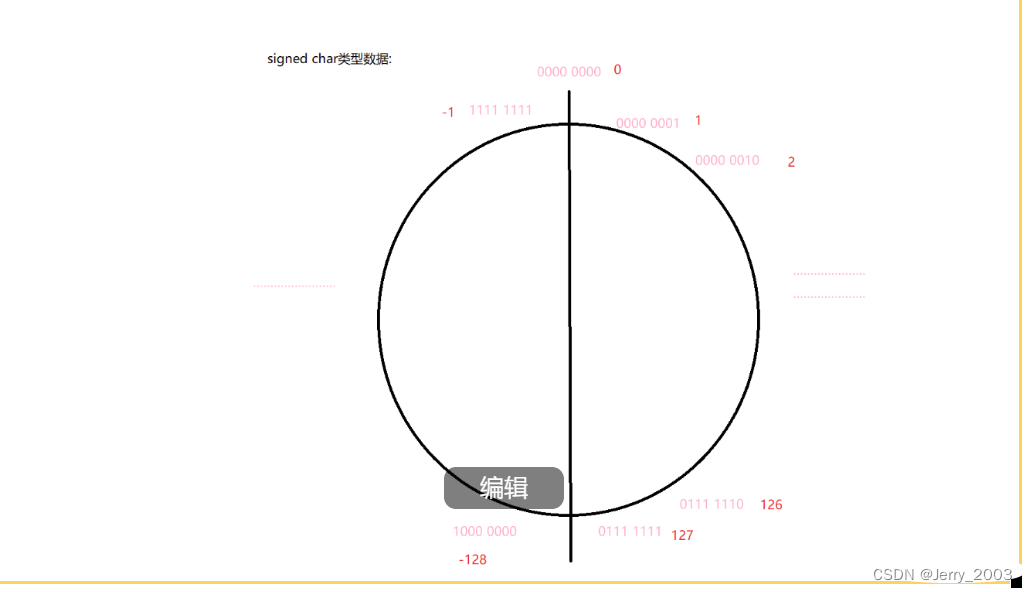
三、浮点型在内存中的存储
根据国际标准IEEE(电气和电子工程协会)754,任意一个二进制浮点数可以表示成下面的形式:
(-1)^S * M * 2^E(即用科学计数法表示)
IEEE 754规定
(1)对于32位的浮点数,最高的1位是符号位S,接着的8位是指数E,剩下的23位为有效数字M。
(2)对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。
M
计算机内部保存M时,默认这个数的第一位总是1。因此,可以被舍去,只保存后面的小数部分,读取时再将第一位的1加上。节省一位有效数字,可提高小数部分的精确度。
E
(1)放入
E为一个无符号整数。若E为8位,它的取值范围位0-255。若E为11位,它的取值范围为0-2047。
但科学计数法中的E是可以出现负数的。所以IEEE 754规定,存入内存时E的真实值必须加上一个中间值。对于8位的E,中间值位127。对于11位的E,中间值为1023。
(2)取出
1.E不全为0或不全为1
E减127(1023)得E的真实值——即正常反向计算
2.E全为0
浮点数的指数E等于1-127(或者1-1023)即为真实值。有效数字M不再加上第一位的1,而是还原为0.xxx的小数。这样是为了表示+/-0,以及接近于0的很小的数字。

















 1462
1462




 到【灌水乐园】发言
到【灌水乐园】发言







