




【简历修改、职业规划、大厂实习请私信联系~】
先预览一下 AE 和 VAE 模型的效果(第一行是输入原图,第二行是 AE 重构结果,第三行是 VAE 重构结果),几乎完美重构!

本文介绍 Diffusion 模型推理加速的一种常见方式:用AE(AutoEncoder) 和 VAE(Variational AutoEncoder) 进行图片压缩/反压缩。理论部分学完之后立即用代码进行实践,彻底掌握 AE/VAE。
AE 基础知识
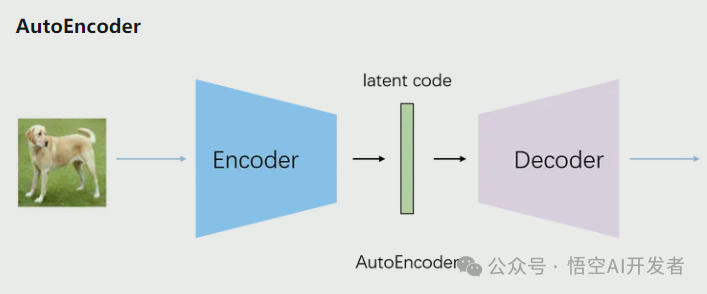
自编码器(AutoEncoder,AE)是一种无监督学习的神经网络模型,主要用于数据压缩和特征学习。它的核心结构包括两个主要部分:编码器和解码器。编码器负责将输入数据压缩到一个低维的潜在空间,这个过程可以看作是提取输入数据的关键特征。解码器则尝试从这个压缩的表示重构原始输入,目标是使重构的输出尽可能接近原始输入。
AE 通过最小化重构误差来训练,这促使网络学习输入数据的最重要特征。训练完成后,编码器可以用于降维、特征提取或数据压缩,而完整的 AE 可以用于去噪或异常检测等任务。
AE 的优点包括结构简单、训练相对快速,以及可以学习紧凑的特征表示。然而,它也存在一些局限性,如生成能力有限,难以生成新的、有意义的样本。
VAE 基础知识
变分自编码器(VAE)是自编码器的一种概率变体,它结合了变分推断和神经网络,用于生成模型和表示学习。VAE 的核心思想是将输入数据编码为概率分布,而不是固定的向量。
VAE 的结构包括编码器、采样层和解码器。编码器将输入映射到潜在空间的均值和方差,采样层从这个分布中采样,解码器则从采样的潜在向量重构输入。
VAE 的训练目标包括两部分:重构损失和 KL 散度。重构损失确保模型能够准确重建输入,而 KL 散度则作为正则化项,使潜在空间的分布接近标准正态分布。
具体操作
编码器:将输入数据x编码为隐变量z的均值μ和标准差σ。
采样:从标准正态分布中采样一个ε,通过μ和σ计算z = μ + ε* σ。
解码器:将z解码为生成样本x'。
计算重构误差(如均方误差MSE)和KL散度,并通过优化算法调整模型参数,以最小化两者的和。
相比传统的自编码器,VAE 具有更强的生成能力,可以生成新的、合理的样本。它的潜在空间是连续的,便于插值,并且具有一定的正则化效果,有助于减少过拟合。
VAE 广泛应用于图像生成、异常检测、数据增强等领域。然而,它的训练过程可能较为复杂和不稳定,且 KL 散度项可能导致模型忽视部分输入信息。
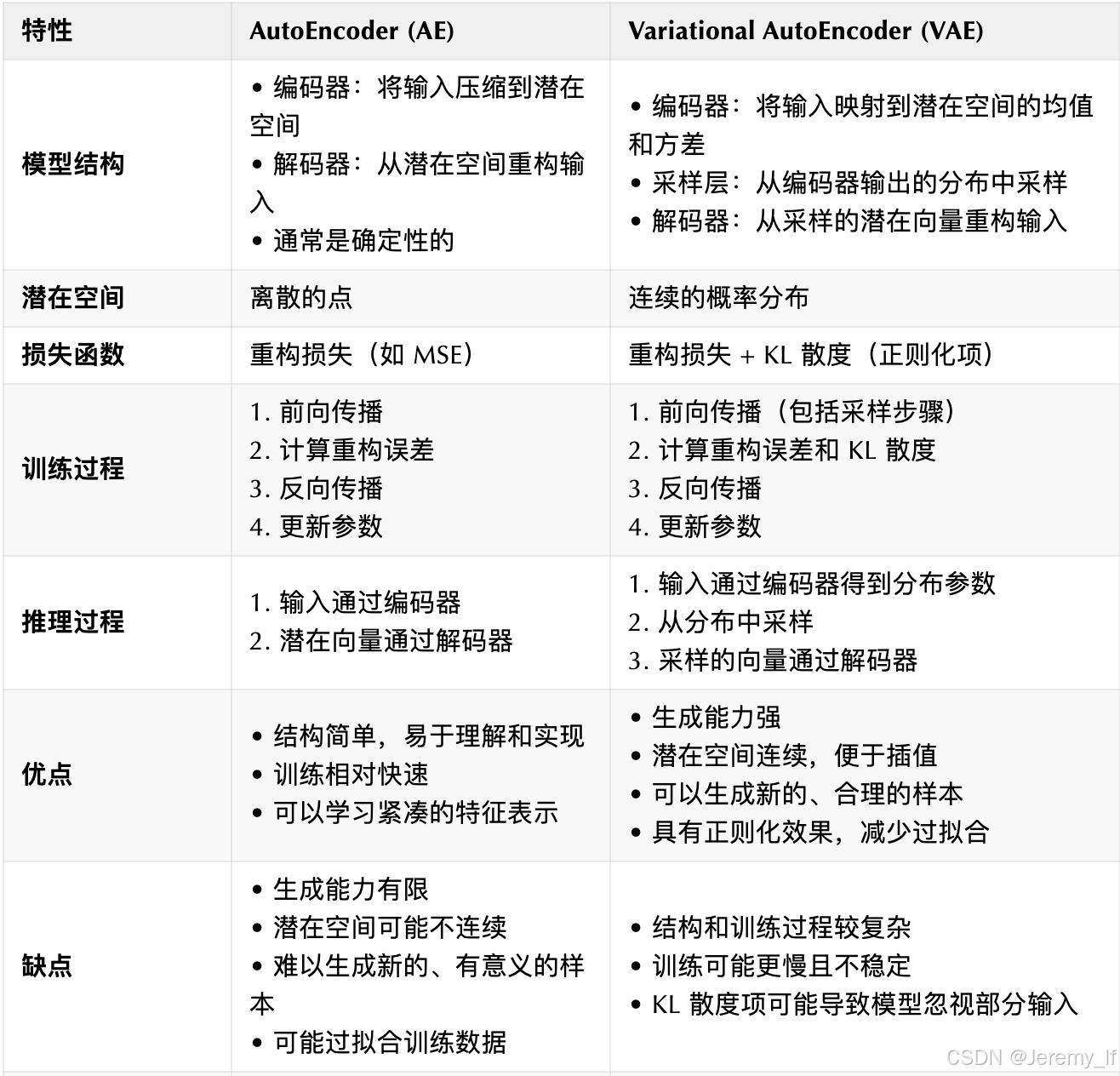
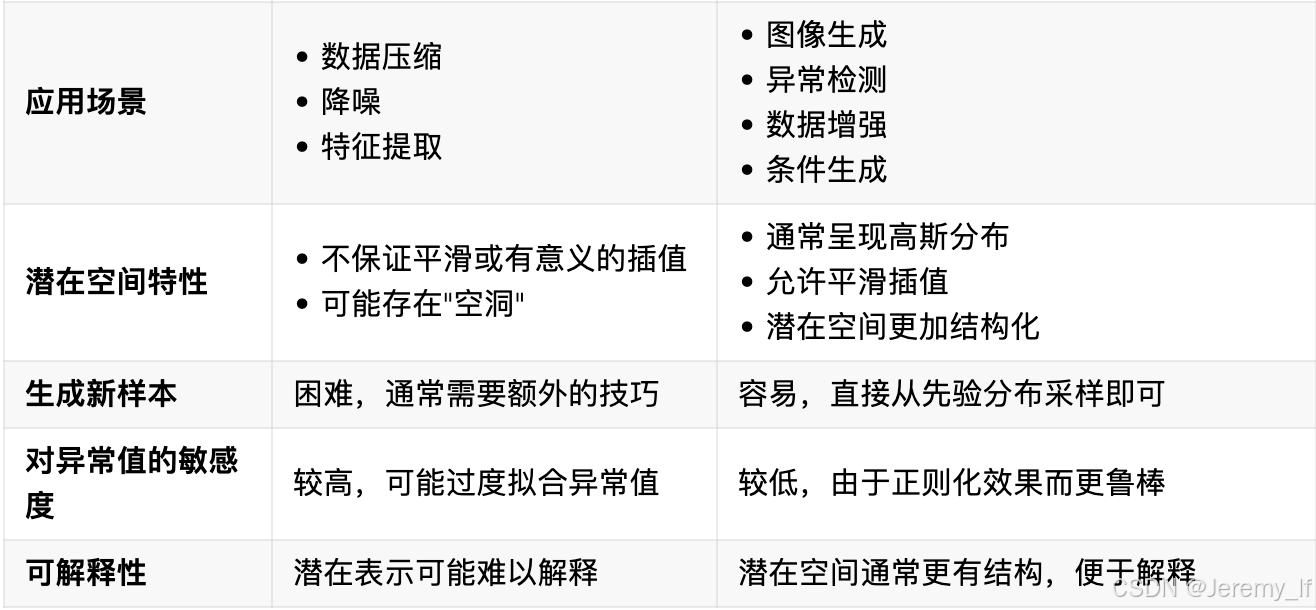
对比 AE 和 VAE
代码实战
import torch,os
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# 设置随机种子以确保结果可复现
torch.manual_seed(42)
# 准备MNIST数据集
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 创建数据加载器
# batch_size: 每批处理的样本数
# shuffle: 是否在每个epoch打乱数据
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False)
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
# 编码器:将28x28的输入压缩到3维潜在空间
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











