




图像由 Google ImageFX 生成
前言:
📌 本文整理自 NoProp 原始论文与实践代码,并结合多个公开实现细节进行了全流程复现。
🔍 对神经网络训练机制的探索仍在不断演进,如果你也在研究反向传播之外的新路径,这篇内容可能会给你一些启发。
正文:
反向传播(Backpropagation)首次出现在 1986 年,是如今几乎所有主流机器学习模型训练背后的关键算法之一。
它简单,容易实现,而且在训练大规模神经网络时效果很好。
不过,尽管被广泛接受为最优方法,它还是有一些明显的缺点,比如训练时内存占用高、以及因为算法是顺序执行的,难以实现并行训练。
那有没有一种算法,可以有效训练神经网络,又不带这些缺点?
牛津大学的一个研究团队刚刚提出了这样一种算法,它直接把反向传播给淘汰了。
他们的算法叫做 NoProp,甚至连前向传播都不需要,它基于扩散模型(Diffusion models)的原理,可以在不传递梯度的情况下,独立训练神经网络的每一层。
我们接下来就要深入探索这个算法的工作机制,对比其效果,还会从零开始写代码训练一个神经网络。
走起!
但首先,啥是反向传播?
MLP(多层感知机,Multi-Layer Perceptron)是全连接前馈型的深度神经网络,是今天所有 AI 技术的核心结构。
它们由一种叫“神经元”的单元组成。
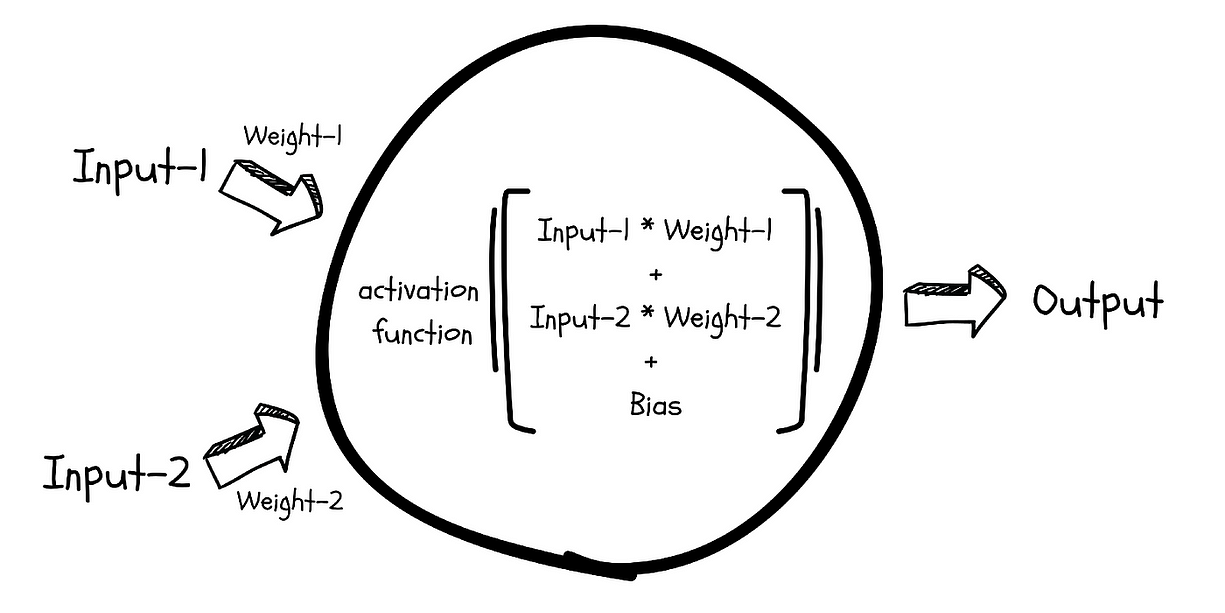
神经元内部结构,是 MLP 的基本单位
神经元被堆叠成多层,在 MLP 中,一层的每个神经元都会和下一层的每个神经元相连接。
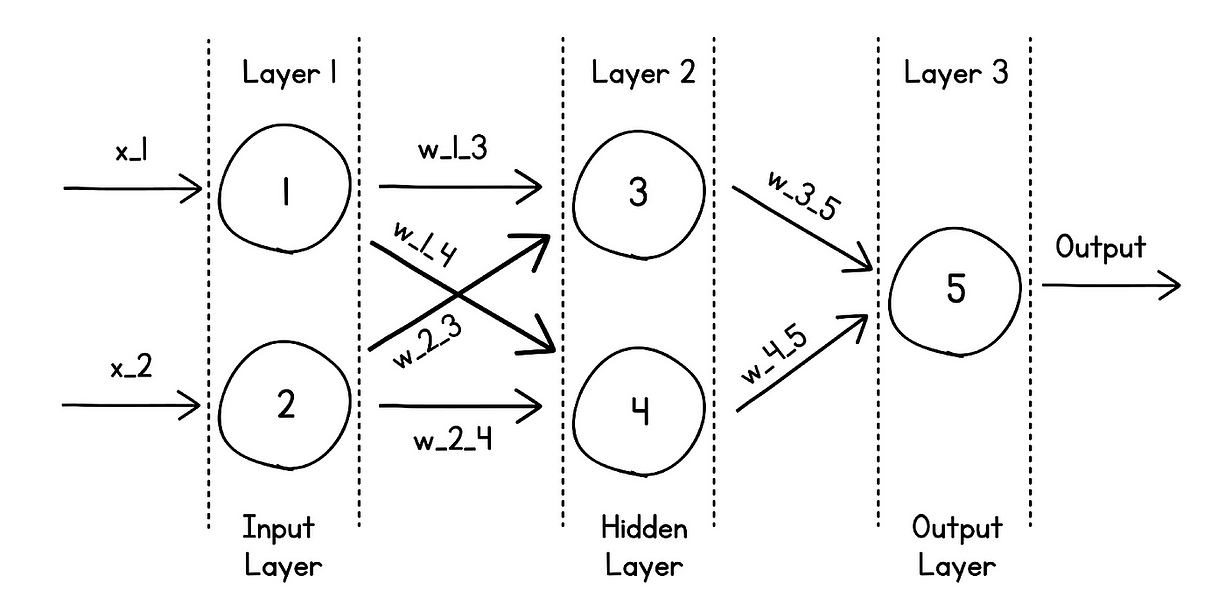
MLP 中连接方式的示意图
训练时,输入数据会穿过这些神经网络,每一层会对它施加权重、偏置和激活函数,逐层处理,最终在最后一层输出结果或预测。
这个过程叫作 前向传播(Forward pass 或 Forward propagation)。
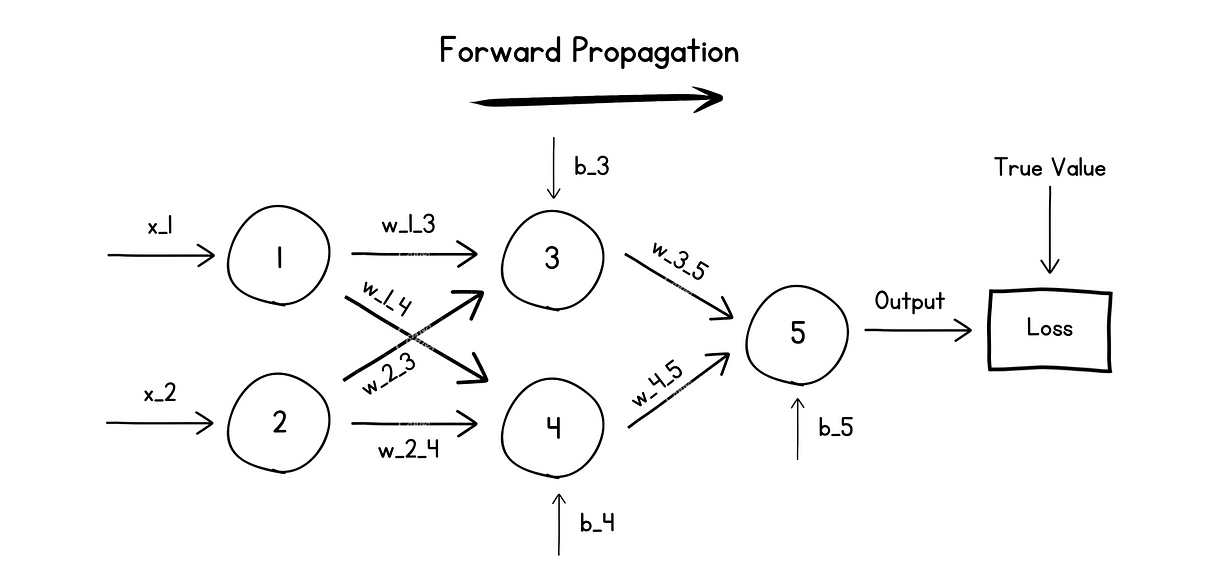
前向传播的可视化
接下来,前向传播得到的输出会和输入数据对应的真实标签做比较,计算出误差或损失函数。
这时就轮到反向传播算法上场了,它会从最后一层开始,计算损失函数对网络参数(权重和偏置)的梯度。
这个过程通过微积分中的链式法则完成,并告诉我们每个参数对错误有多大贡献(也叫 credit assignment)。
这一步就叫 反向传播(Backward pass)。
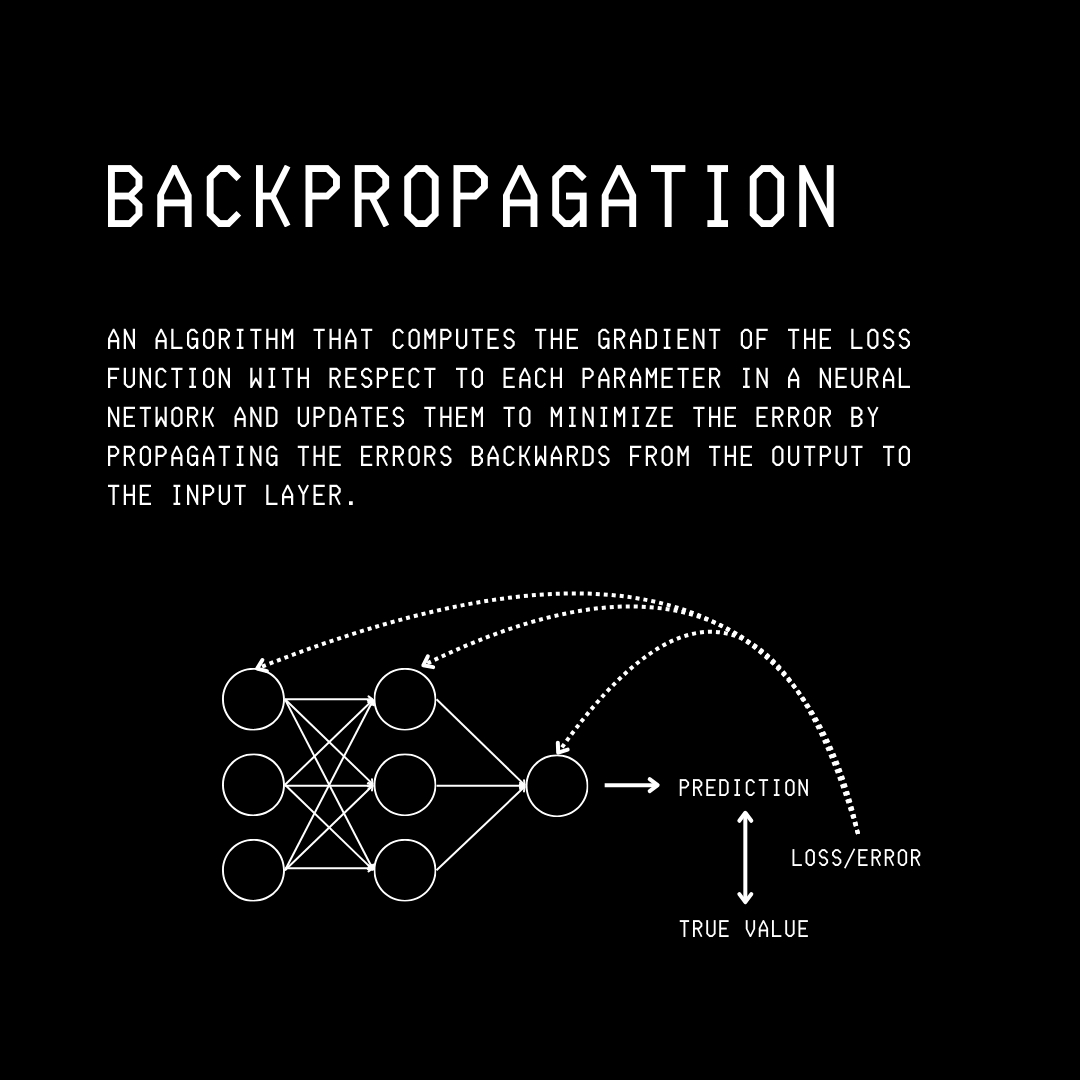
反向传播的可视化
完成反向传播后,优化器会一层层更新/调整这些参数,以降低损失,从而让模型变得更优秀。
但反向传播的问题在哪?
尽管反向传播效果很好,但它对内存的消耗非常大。
你还记得前向传播时,每一层输出的结果吗?这些输出也叫作“中间激活值(Intermediate activations)”,它们必须被存储,因为后面做反向传播时还需要用到。
对于有几百层、上百万神经元的神经网络来说,训练时光是存这些中间激活值就可能占用好几个 GB 的 GPU 显存。
(确实有像“梯度检查点(Gradient checkpointing)”这种技术来缓解这个问题,但本质上还是很耗资源。)
此外,由于反向传播是顺序算法,每一层的梯度计算都依赖于下一层的梯度。
这意味着我们无法把所有层的梯度计算并行执行,每一层都得等下一层计算完自己那部分梯度,才能继续。
而且,用反向传播训练出来的神经网络,是按“分层方式”来学习的,也就是说,学习过程是分多个抽象层级的,低层学简单模式,高层在此基础上学更复杂的。
但当梯度从高层向低层传播时,不同任务或样本的数据更新有可能会互相干扰,甚至导致模型把以前学过的东西彻底忘掉(这个现象叫 灾难性遗忘 Catastrophic Forgetting)。
以下是之前出现过的一些反向传播替代方法,但都没太成功,因为它们在准确率、计算效率、可靠性或可扩展性方面表现不佳:
- Zero-order gradient methods
- Direct search gradient-free methods
- Model-based gradient-free methods
- Natural evolution strategies
- Difference Target Propagation
- Forward-Forward algorithm
那么,现在还可能有真正有效的“无反向传播学习”方法吗?
NoProp 来了
NoProp 算法借鉴了扩散模型(原本主要用在图像生成任务中的思路),把它用在了图像分类(监督学习)任务上。
如果你时间不多,想跳过数学细节,下面是这个算法的简略工作原理:
训练时,神经网络中的每一层/模块都会接收到一个带噪的标签和一个训练输入,然后它预测目标标签。
每一层都是独立训练的,使用的是一个去噪损失函数(denoising loss),这使得训练过程中完全不需要前向传播。
不过和训练不一样的是,在推理阶段,所有层是一起工作的。
从高斯噪声开始,每一层都会接收上一层生成的带噪标签,并将其去噪。
这个过程一层接一层进行,直到最终一层输出最终的真实类别(即完全去噪后的表示)。
接下来我们就要详细讲解这个算法的内部机制。
(如果你对扩散模型已经熟的话,看懂这一部分会更容易。)
假设我们有一个样本输入 x 和它的标签 y,我们的目标是训练一个模型,给定 x 预测出 y。
从数学角度讲,我们不是要找一个函数 f(x) = y,而是要训练一个神经网络,去建模一个从随机噪声转换成可估计 y 的形式的随机过程。
在这个过程中,有两个分布是需要理解的:
1. 随机前向/去噪过程
这个过程用 p 来表示,如下所示:
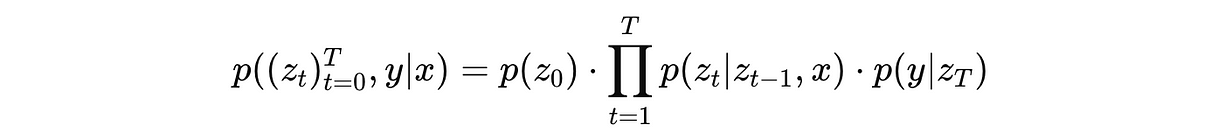
它建模了我们如何从噪声开始,经过一系列步骤,把它去噪到最终表示 z(T),然后用这个去预测标签 y。
数学上来说,它是所有中间噪声表示 z(0), …, z(T) 和标签 y 在给定输入 x 下的联合概率。
在这个公式里:
- p(z(0)) 表示标准高斯噪声
- p(z(t) ∣ z(t−1), x) 表示每一层是如何去噪输入噪声的
- p(y ∣ z(T)) 表示如何根据最终表示 z(T) 分类出 y
p(z(t) ∣ z(t−1), x) 是用神经网络参数化的,如下所示:
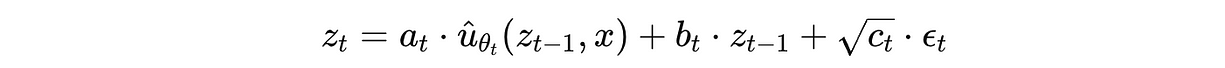
其中:
- 带参数 θ 的神经网络 û,乘上系数 a(t),根据带噪输入 z(t−1) 和 x 预测去噪后的表示
- b(t) ⋅ z(t−1) 是一个带权重的 skip connection(跳跃连接)
- √c(t) ⋅ ϵ(t) 是随机高斯噪声
- a(t), b(t), c(t) 是三个标量,用来分别给公式中的三项加权
2. 反向加噪过程 / 变分后验
这个过程用 q 表示,如下所示:
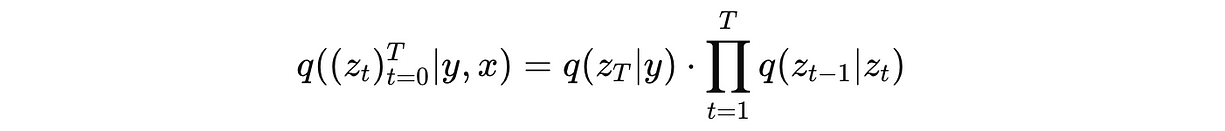
它建模了我们如何从标签 y(以它的嵌入 u(y) 的形式)开始,逐步加噪,直到得到 z(0)。
数学上来说,它是给定标签 y 和输入 x 下,最终带噪表示 z(T) 的概率分布。
在这个公式里:
- q(z(T) ∣ y) 表示给定标签 y 的表示 z(T)
- q(z(t−1) ∣ z(t)) 表示反向扩散过程,也就是通过加噪回到更早的噪声表示
q(z(T) ∣ y) 如下所给:
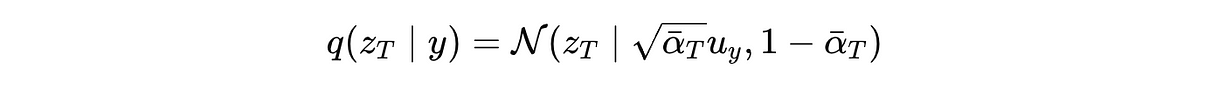
这表示这是一个关于潜变量 z(T) 的高斯分布,其中 √αˉ(T)⋅ u(y) 是均值,1 — αˉ(T) 是方差。
u(y) 是标签嵌入,αˉ(T) 表示在加噪过程中 u(y) 还剩多少。
q(z(t−1) ∣ z(t)) 给出如下公式:
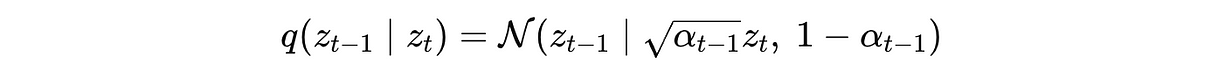
这表示这是一个关于潜变量 z(t-1) 的高斯分布,其中 √α(t-1)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 190
190


 到【灌水乐园】发言
到【灌水乐园】发言








