



作者:Michael Dain

无题,David Shrigley 2022
本文作者的核心观点是:在 AI 时代,我们不该继续盲目追求形式上的努力和勤奋,而应该主动拥抱一种‘聪明的懒惰’,把重复、低效、装样子的工作交给机器,把人的智慧用在创造性、判断性、更具人性价值的部分上。
而作为一个长期在一线干 AI 项目的工程人,从芯片设计、电路开发、GPU 部署,到 Linux 系统和模型训练,十多年下来我越来越意识到一件事:最聪明的“努力”,往往是把事情设计得无需努力。
正文:
那些“思考不到五秒”的工作将会是最先被取代的。——创新工场 CEO 李开复(Rouhiainen, 2020)
我们已经进入了一个连“智慧”都可以被商品化的时代。生成式 AI 工具现在可以模仿最受推崇天才的知识和表达能力,耐心而流利地回答任何问题。这些系统并不无知——它们接触过的学科远超过一个人一辈子能掌握的数量。它们也不笨——笨意味着通过行动来学习,而 AI 不会行动,只会在高度可理解的上下文中“动作”。它们也不一定“愚蠢”——愚蠢是明知故犯,为了眼前的好处、欺骗、或者盲目顺从一些有问题的动机。现在 AI 让“认真学习”变得不确定了,我们必须重新思考我们与“努力”之间的关系。如果我们抗拒这种转变,就会陷入一场“表演赛”,而不是实质性进步。但如果我们顺势而为,也许我们最终可以建立一种尊重“懒惰”的文化——不是那种无所事事的懒,而是有意识地避免不必要的努力,换来更聪明、更有效的解决方案。
可能我们的问题不是“智力”——而是“惯性加传统”。我们花了几百年优化自己的能力,所以对“改变”——尤其是工作和学习方式的改变——特别抗拒。我们喜欢现状,即使它早就过时了,就像一张用了 30 年没人敢删的 Excel 表。在物理世界里,努力是有意义的。你不能把通水管或者做甜点的事外包给一个聊天机器人。但在知识工作领域,学习已经变得怪怪的了。我们以前是训练实际动手技能,现在追的是学历证书,把知识当零食一样吞,效率和专业傻傻分不清。我们想让学习更快、更有趣、更有效——但奇怪的是,我们却越来越搞不清楚“值得学的到底是什么”,这不是靠快、靠累能解决的,而是靠一种“慢慢懒着、带点专注”的节奏。
疫情期间,那些有幸可以在家办公的人,对时间有了全新的认识,一个信号就是——全民开始做酸面包。我也一样,把它当作一种锚点,一种回归人类本质的感觉。从有人的那天起,就有了面包。而做面包的材料——面粉、水、空气——就在我们身边。
养酸种、让它变成能吃的东西,其实不需要什么专业技能。你只要有时间、有耐心,再加点“人在场”的感觉。我不想用“引导”这个词,但它就是这么起作用的——温柔地关注,而不是死命地折腾。一星期的面包,只需要一天的时间就够了,还能安排在你手表提醒你“起身拉伸”之间的间隙里完成。
它提醒了我:不是所有努力都得“费劲”。也许我们早就忘了最核心的一课——学习、创造、或是贡献,并不一定得靠硬拼。有时候,是靠对一个漫长过程的慢信任。可惜的是,这种过程在现代体系里已经越来越稀有了。在学校、在公司、在科技领域——大家都在比谁快,结果是看起来“聪明”比“人在现场”更容易得分。于是,如果我们放弃了深度参与,很多人就开始……变得越来越会“投机取巧”。
优化陷阱
当“看起来成功”比“真正理解”更容易得奖的时候,欺骗就成了最高效的策略。无论是在学校、工作、还是商业里,作弊往往能带来短期回报——即使它迟早会带来长远的麻烦。整个生态系统都在靠这个生存:营销噱头、标题党内容、表演型生产力。在这种意义下,“愚蠢”不是没脑子,而是甘愿接受假象,放弃本质。至于“懒惰”,也不总是敌人。在团队合作中,我看过不少“懒人”从别人努力里受益,而真正协同的团队其实非常稀少。但也许这才是重点。真正的目标不该是逼更多人去卷,而是设计出一种系统——让每个人都可以“有效懒”,不浪费努力,砍掉那些没必要的事,把那些原来我们默认该自己干的苦活交给 AI。
“穷人应该有闲暇时间”这个想法对富人来说一直很刺耳。在英国,你会发现很多有钱人真心觉得穷人不该有空闲,因为他们不可信,肯定不会善用它。在美国,即使人很有钱,也常常拼命加班,因为他们觉得这是自己的“责任”。但这种强迫努力的结果会是什么?就是东西生产太多,人却被累垮。
——伯特兰·罗素《懒惰的赞歌》1932
“战略性懒惰”不是新玩意
我研究如何用电脑工作和学习已经几十年,期间碰到一个很讽刺的悖论:我们文化中那种根深蒂固的“拼命努力才成功”的信念,反而让我们离真正优雅有效的解决方案越来越远。我们太忙于表现出自己“很努力”,以至于忘了去问:有没有更好的做法?我们现在对“工作”的理解,很多时候靠的是“让别人觉得你在努力”而不是“你真的做了啥”。当 AI 成了万能解法,我们需要的不是更聪明的电脑或更聪明的人,而是整个文化认知的进化——换个角度看“努力”和“才华”应该扮演什么角色。但如果我们不设规则、不立准则,这些新技术可能反而会让人更加混乱。我们得帮自己和别人“如何懒得聪明”,而不是“蠢得勤快”。
想想 1918 年福特和他的效率专家之间的故事。那些专家被雇来评估工厂,看到有个人什么都不干,脚翘在桌子上,就建议立刻开除他。福特回:“那人以前想出了个主意,帮我们省了几百万美元。当时他也是翘着脚坐在桌子上。”
这个小故事很深刻。我们和“工作”与“创新”的关系,常常被误解。最有价值的贡献,往往不是来自“一直在动”,而是来自“安静地想”。但我们的制度——从学校到公司——仍然主要奖励那种工业时代的模式:只要你看起来很努力,就比你真的做对了更重要。
骗时间表
你可能每天都遇到这种情况——我们更在意“状态”,而不是“目标”;更在意自己做了什么,而不是理解自己的工作在公司整体愿景中扮演了什么角色。我们不停地产出,但很少真正“思考”。
我曾在一家超大的公司工作,那里的升职基本靠你安排了多少会议。后来我们团队换了个合作风格——大家挤在一个屋子里,直接聊,2~3 分钟就能解决问题。但我们的老板很不开心。他还是躲在办公室里,重视“行程表”多于“对话”。排满的会议比快速沟通更有价值。
最后有个人(不是我老板)升了职,成了董事总经理,后来被发现——他很多会议都是编出来的,于是被开除了。但这个事,并没有改变整个系统,只是把“犯规最明显”的人赶了出去而已。
我们的文化,还是把“努力”放在结果前面,把“仪式”放在目的前面。这种错位,扭曲了从企业行为到教育政策,再到我们怎么安排“空闲时间”的一切。

我们知道自己有缺点,那我们该怎么应对挑战,把这些缺点改掉?
工作、职能、责任
“工作”这词,暴露了我们理解“努力”和“价值”的一个很古怪的问题。当我们说某件事“需要努力”,我们其实是在承认它不完美、不完整,甚至可能是失败的。我们围绕“工作”的词汇里,经常藏着一种微妙的“不够好”的意味——“我正在努力中”“辛苦工作”“重新回去干活”——这些话都带着挣扎感,而不是成就感。我们甚至建起了完整的社会结构,全都围绕着这种“永远要努力”的概念。
来想想“工作”和“目标”之间的基本区别。最基本的工作,就是“出力气”,通常是重复的、单调的,就像每天都得做饭,不管饭是不是好吃、有没有营养。而“职务”这个概念则不一样:它是一种责任和在场感的结构,理想状态下,它给人提供成长、合作的框架。最好的时候,它是一块保护区,可以试错、学习、头脑风暴。最坏的时候,它就变成了一座“形式主义的庙”。
这让我们谈到人类行为的一个关键分野。当我们说某个行为“愚蠢”,通常是指“你临时脑抽了”——就是你没好好想就动手了,是个一眼就能看出来的问题。而“蠢”,是一种系统性的错误:你明知道有更好的办法,却偏偏选了最低效的,常常是为了方便或图一时省事。就像有人明明有钥匙,偏要撞门进去——这不只是低效,是在“反着来”。
现代职场就像一个矛盾体。一方面我们文化里天天鼓吹“勤奋”——看起来你有多努力多重要;另一方面我们却活在一个越来越要求“另一种智慧”的系统里。这不只是“努力 vs 聪明”的老话题,而是认清科技进步已经彻底改变了“人类贡献价值”的本质。
看看现在还有多少社会死死抱着工业时代的“生产力模型”,甚至还用童工维持产能。而我们的教育系统也很尴尬——一边想搞职业教育,一边又舍不得人文课,结果搞出来个四不像。我们还在为“昨天的问题”训练学生,现实却是“明天的工具”一天比一天厉害。

设计思维已经在解决各种问题上推广了这套新思路
聪明的懒惰
现在计算系统能干的活,很多以前得人类干一辈子才学会,这让我们不得不面对一个不太舒服的问题:如果我们过去对“工作和学习”的方法,不只是效率低,而是根本在“拖后腿”呢?真正该担心的,还不是你抵抗新东西,而是你默默延续着“已经没用了的老做法”——那种“蠢里蠢气”的执拗方式。
那我们就换个思路吧:试试我们说的“聪明地懒”——有策略地减少无意义的努力,把注意力腾出来干点高阶思考或创造力的活。这可不是说“啥都不干”,别做白日梦了,哪怕你梦想站台上来段吉他独奏,你也得苦练。这里说的是,从根上重新想想:在智能系统时代,人类的价值应该体现在哪。
难的不是“做得更多”,而是“做得更对”——搞清楚我们那些“努力”和“检查”的老办法,什么时候已经开始拖后腿了。我们得学会一种“分辨的智慧”:啥是真正的投入,啥只是动来动去;啥是值得人来判断,啥早该交给自动系统去做。
这不是空谈——在这人脑算力没变,机器算力暴涨的时代,这个问题越来越实在。不是“要不要适应”,而是“怎么有意识地适应”。

我们哪怕干得很烂还能玩得很开心,其实就是在展示真正的能力。
蠢工作
从这个角度出发,我们得重新审视职场上“什么才是真正有价值”的东西。真正的专业,不是把复杂事重复做得多熟练,而是能设计出“不需要再重复”的系统。愿意接受“制定策略 + 执行到位”是需要时间的这种现实,愿意花时间判断“认知资源该投在哪”,这才是高手——而这往往是试错后的结果。
不是所有劳动都是可见的,也不是所有辛苦都有效。在很多岗位上——尤其是“照护、支持、服务”这类工作——最难的不是技术或体力,而是情绪劳动。这种累,是看不到的那种:你要忍住不发火、在团队焦虑时扛住气氛、每天都带着共情地出现。这些不会写进工时记录,但它却让工作真的能运转起来。而它几乎从来不被认可,更别说奖励了。
我看现在工作的变化,最明显的张力就是:我们一边本能地想通过“多做点”来掌控局面,另一边又越来越需要“用设计去信任”系统。我认识最有效率的人,根本不是加班最多或盯得最紧的,而是那些擅长“发现 + 删除”无效工作的高手。他们能建出一种“良性循环”:每个人都能从中受益,于是这事就能自转,不用人天天去盯。
有个朋友,管着几百个工程师。他推行 Scrum,每个小组自管自理。他从每天开 14 小时会,变成“几乎啥事都不用做”。团队不再等人指令,而是自己动起来了。我很佩服他:因为他“日程清了”,所以有时间去解决更大、更难的问题。
理解的第一步,就是建立连接
这些年我们也在做类似的事。从一开始搞硬件、写驱动、搭平台,到后来搭推理引擎、搞模型优化,系统越复杂,我们越清楚:靠人力硬扛没有出路,越早系统化越能赢。
所以我常说,我们不是在“偷懒”,而是在“提前设计好不需要再努力的系统”。
学习的游戏
这不只是效率问题——而是要留出空间,让我们意识到:真正的“人类贡献”,很多时候跟“努力程度”根本没啥关系,而是看你有没有用心、有没时间“玩”。自动化那些重复、无趣、常规的任务,让我们能专注于“创意、战略和人性”这些才是真功夫的部分。把“懒”摆在“勤劳”对面特别有意思,尤其是在这个科技增强史无前例的时代。现在 GPT 都能 100% 通过大学数学开卷考试了,那我们自己考出来的分数,是不是更说明“我们是谁”?
“我们不是推理机器,我们是类比机器。我们靠共鸣思考,不是靠逻辑推导。我们比自己以为的,更不理性。”
——Geoffrey Hinton,AI 先锋
这场变化的核心,不光是“过劳文化”、美式上升逻辑,或者经济博弈。真正被挑战的是:我们对“决策是怎么发生的”这个基本假设。不仅仅是机器做决定,而是“我们自己”做决定的方式,也被拷问了。
AI 这词现在被滥用了。但它真正带来的——一开始是悄悄的,后来爆炸性的——是一种“探索未知”的全新方式。以前程序员的梦想,是“预测所有结果”,写出干净的、确定性的系统。而生成式 AI 解决问题的方式完全不一样:它是靠“猜”。它用训练好的统计模型,根据海量多样的输入,不是一条条计划动作,而是投出可能性、评估效果、再改进猜法。它追的是“最低代价、最大有用性”,有点像大自然解决问题的方式——复杂得像谜,却根本不是靠“会”做到的。
它做的,其实跟人类的“直觉决策”很像——我们也常在信息不全时下决定,靠的是经验、图像感知、预感。我们曾以为“智慧是掌控”,现在看来,它更像是“即兴发挥”。
再往前走,还有个也许暂时没什么实用价值的例子:量子力学把这个模式又推远了一步。量子计算机不仅仅是算,它直接利用了“现实本质上的不确定性”。它们不是“真”就是“假”,而是介于中间。这种状态能模拟复杂度,是传统系统办不到的。AI 和量子计算都说明一个问题:真正的智能,不在于“按部就班”,而在于“精准地走进不确定”。
我们如何知道我们不知道什么
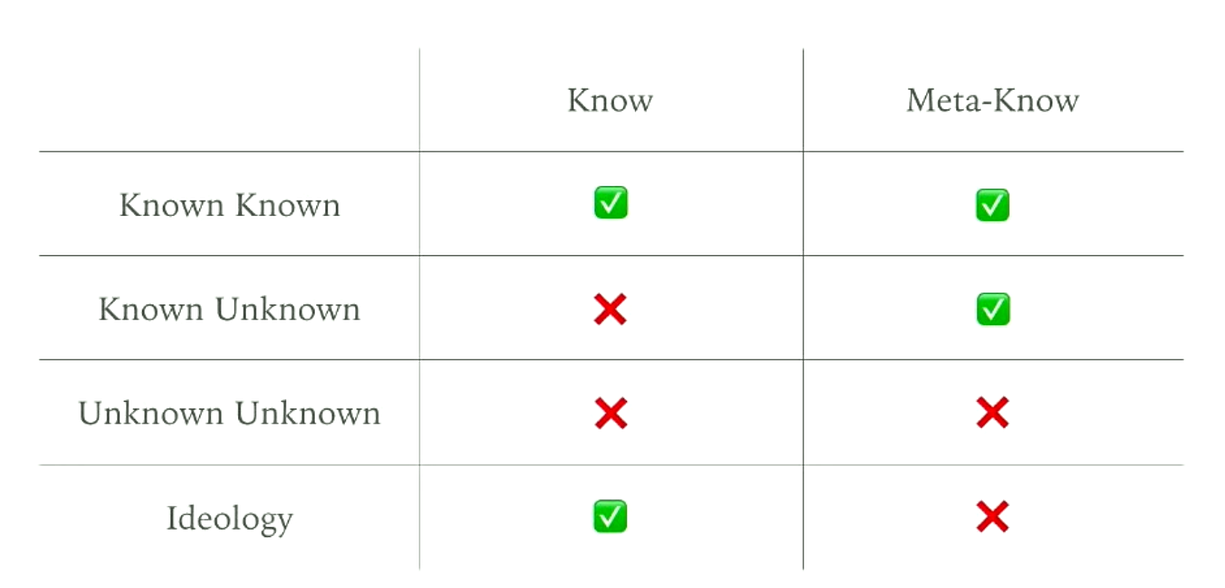
Rumsfeld 战略矩阵,来自《What UNIX Cost Us》——@jeamland
“与其去写一个模拟成人脑的程序,为什么不先写一个能模拟小孩的?”
——阿兰·图灵,《计算机器与智能》(1950)
所以我们现在已经发展出一套数学模型,帮电脑“更好地猜”。一开始它们学着像小孩一样玩桌游,然后我们把这种能力用在语言游戏上。现在它也开始擅长图像、电影、音乐这些游戏了。它已经、而且将会,成为历史的推动力之一。
那我们怎么利用这个新工具,让“懒”带来成功?不是当闲人,而是有目的地设计系统、奖励慢思考。奇怪的是,社会心理学这个领域,至今还没真正跟上。我们还在奖励“看起来聪明、看起来努力”的行为,而不是那些真正能产生洞见的行为。
如果我们真的聪明到能造出“会思考的机器”,那我们也许真的该聪明到“坐下来,好好用它”。
对我们这类搞 AI 应用的工程人来说,从底层硬件到模型设计,每个环节都在验证一个事实:让系统聪明,是为了让人类可以懒得高级一点。
我现在专注用十年工程经验 + 商业认知,帮企业把 AI 产品从概念做到落地。如果你也在做 AI、搞项目、配设备,欢迎评论区或、私信交流。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









