





Vegapunk No.01 海贼王角色,用 ChatGPT 生成
这是我们新系列《DeepSeek-V3 解读》的第一篇文章,在这个系列里,我们会努力揭开 DeepSeek 刚开源的最新模型 DeepSeek-V3 [1, 2] 的神秘面纱。
在这个系列里,我们计划覆盖两个主要话题:
• DeepSeek-V3 的主要架构创新,包括 MLA(Multi-head Latent Attention)[3]、DeepSeekMoE [4]、无辅助损失负载均衡 [5] 和多 token 预测训练。
• DeepSeek-V3 的训练流程,包括预训练、微调、以及强化学习(RL)对齐阶段。
这篇文章主要聚焦在 Multi-head Latent Attention 上,最早在 DeepSeek-V2 开发过程中首次提出,后来也被用到了 DeepSeek-V3 上。
• 背景 我们会先回顾一下标准的 Multi-Head Attention(MHA),解释为什么在推理过程中需要 Key-Value(KV)缓存。然后,我们会探讨 MQA(Multi-Query Attention)和 GQA(Grouped-Query Attention)是怎么去优化内存和计算效率的。最后,还会简单说一下 RoPE(旋转式位置编码)是怎么把位置信息融合进注意力机制的。 • Multi-head Latent Attention 深入介绍 MLA,涵盖它的核心动机、为什么需要解耦 RoPE、以及它是怎么比传统注意力机制表现更好的。
🔍 我们在研究这些新架构的同时,也在整理一套完整的「LLM底层机制拆解系列」资料,聚焦模型结构演进与推理效率优化。如果你也在搭建或评估大模型系统,不妨关注这个系列一起深入分析底层设计背后的工程逻辑。
背景
为了更好地理解 MLA,并让这篇文章能自洽,我们先在这一节里回顾一些相关概念,然后再正式进入 Multi-head Latent Attention 的细节。
只用 Decoder 的 Transformer 里的 MHA
要注意,MLA 是专门为了加速自回归文本生成推理而设计的。所以,这里提到的 Multi-Head Attention(MHA)是在只用 Decoder 的 Transformer 架构下的。
下面这张图比较了三种用于解码的 Transformer 架构。图(a)展示了在《Attention is All You Need》论文里最初提出的 Encoder-Decoder 架构。后来,[6] 对这个 Decoder 设计进行了简化,变成了图(b)这种只用 Decoder 的 Transformer,也成了 GPT [8] 等一大票生成式模型的基础。
现在,大型语言模型(LLM)更常用图(c)这种架构,因为它训练起来更稳定。这个设计里,归一化是应用在输入上而不是输出上,LayerNorm 也换成了更稳定的 RMSNorm。这也是本文讨论的基础架构。
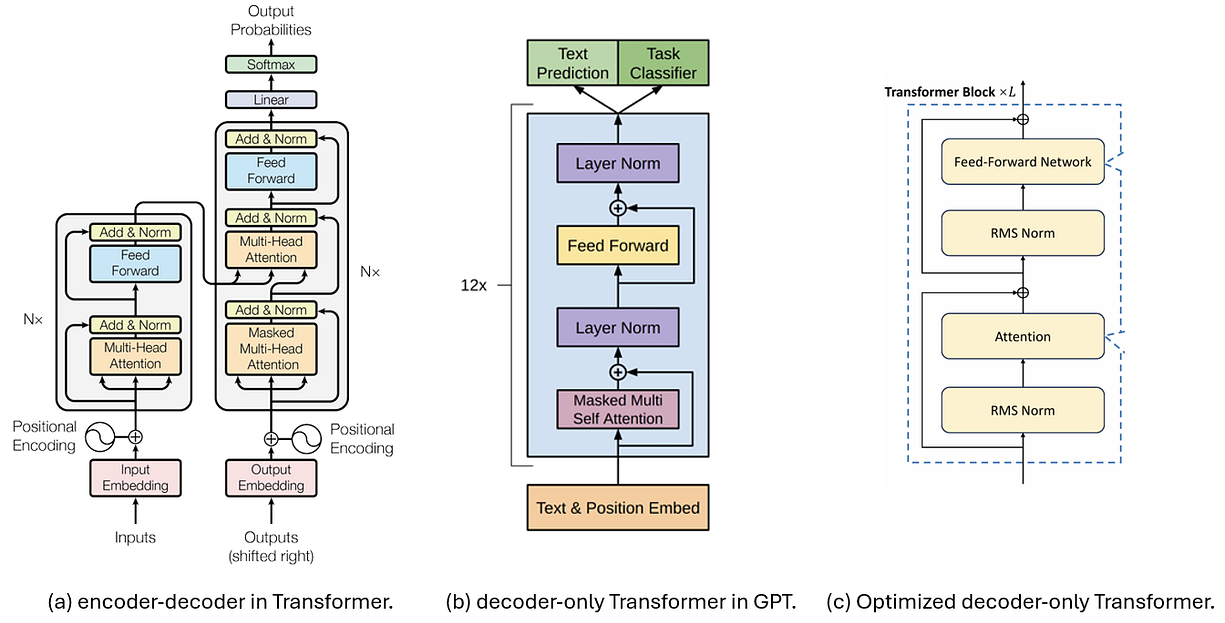
图 1. Transformer 架构。(a)[6] 中提出的 Encoder-Decoder。(b)[7] 中提出并在 GPT [8] 中使用的只用 Decoder 的 Transformer。(c)在(b)基础上优
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









