







引言:为什么故障排查能力决定你的运维天花板
在运维领域工作十年,我深刻体会到:优秀运维和普通运维的核心差距,不在于会多少工具,而在于故障来临时的排查思路和处理效率。
本文将通过真实案例,系统性地分享Linux运维中最常见的故障场景及其排查方法。无论你是运维新手还是老兵,相信都能从中获得启发。
一、建立系统化的故障排查思维模型
1.1 黄金排查法则:STEP模型
在处理任何故障前,请牢记这个模型:
-
• Symptom(症状):准确描述故障现象
-
• Time(时间):确定故障发生的时间点
-
• Environment(环境):了解系统环境和最近变更
-
• Problem(问题):定位根因并解决
1.2 故障优先级判定矩阵
紧急程度 × 影响范围 = 处理优先级
P0:核心业务全部中断(立即处理)
P1:核心业务部分中断(15分钟内处理)
P2:非核心业务受影响(1小时内处理)
P3:个别用户受影响(计划内处理)二、CPU相关故障排查实战
2.1 CPU使用率100%的排查思路
故障现象:系统响应缓慢,top显示CPU使用率持续100%
排查步骤:
# 1. 找出CPU占用最高的进程
top -c
# 按P键按CPU排序,记录PID
# 2. 查看进程的线程CPU占用
top -Hp [PID]
# 3. 获取问题线程的堆栈信息
# 将线程ID转换为16进制
printf"%x\n" [ThreadID]
# 4. 如果是Java进程,打印线程堆栈
jstack [PID] | grep -A 20 [16进制ThreadID]
# 5. 使用perf分析CPU热点
perf top -p [PID]
perf record -p [PID] -g -- sleep 30
perf report真实案例:某电商平台促销期间CPU飙升
问题定位过程:
-
1. 通过top发现Java进程占用CPU 800%(8核满载)
-
2. jstack分析发现大量线程阻塞在某个synchronized方法
-
3. 代码review发现是日志写入使用了同步锁
-
4. 解决方案:改用异步日志框架,CPU立即降至30%
经验总结:
-
• CPU高的常见原因:死循环、正则表达式回溯、GC频繁、锁竞争
-
• 养成使用perf、火焰图等工具的习惯
-
• 建立CPU使用基线,及时发现异常
2.2 Load Average居高不下
故障现象:Load Average达到30+,但CPU使用率只有50%
# 排查步骤
# 1. 查看负载和进程状态
uptime
vmstat 1 5
# 2. 分析进程状态分布
ps aux | awk '{print $8}' | sort | uniq -c
# 3. 查看D状态(不可中断睡眠)进程
ps aux | grep " D "
# 4. 分析IO等待
iostat -x 1 5
iotop -o
# 5. 查看系统调用
strace -c -p [PID]根因分析:Load高但CPU不高,通常是IO等待或锁等待导致
三、内存故障深度剖析
3.1 内存泄漏排查全流程
故障现象:内存使用持续增长,最终OOM Kill
# 1. 查看内存使用趋势
free -h
cat /proc/meminfo
# 2. 找出内存占用最高的进程
ps aux --sort=-%mem | head
# 3. 查看进程内存映射
pmap -x [PID]
cat /proc/[PID]/status | grep -i vm
# 4. 内存泄漏检测(C/C++程序)
valgrind --leak-check=full --show-leak-kinds=all ./program
# 5. Java程序内存分析
jmap -heap [PID]
jmap -histo:live [PID]
jmap -dump:format=b,file=heap.bin [PID]
# 使用MAT或jhat分析dump文件实战案例:Redis内存异常增长问题
排查过程:
# 1. 进入Redis查看内存信息
redis-cli info memory
# 2. 分析大key
redis-cli --bigkeys
# 3. 采样分析key分布
redis-cli --memkeys
# 4. 发现问题:某个Hash类型key包含1000万个field
# 5. 解决:拆分大key,设置合理过期时间3.2 缓存命中率优化
监控指标:
# 查看系统缓存情况
free -h
cat /proc/meminfo | grep -E "Cached|Buffer"
# 查看页面缓存命中率
sar -B 1 10
# 清理缓存(慎用于生产环境)
echo 1 > /proc/sys/vm/drop_caches # 清理页缓存
echo 2 > /proc/sys/vm/drop_caches # 清理dentries和inodes
echo 3 > /proc/sys/vm/drop_caches # 清理所有缓存四、磁盘IO故障处理
4.1 IO性能瓶颈定位
故障现象:数据库响应变慢,IO wait居高不下
# 1. 查看磁盘IO情况
iostat -x 1 10
# 重点关注:%util、await、r/s、w/s
# 2. 查看哪些进程在进行IO
iotop -o -P
# 3. 追踪具体的IO操作
blktrace -d /dev/sda -o trace
blkparse trace.* | head -n 100
# 4. 查看文件系统缓存
slabtop
# 5. 分析进程的IO模式
pidstat -d 1 10优化方案:
# 1. 调整IO调度算法
cat /sys/block/sda/queue/scheduler
echo deadline > /sys/block/sda/queue/scheduler
# 2. 调整预读大小
blockdev --getra /dev/sda
blockdev --setra 256 /dev/sda
# 3. 使用ionice调整进程IO优先级
ionice -c3 -p [PID] # 设置为idle级别4.2 磁盘空间问题快速处理
# 1. 快速找出大文件
du -h / 2>/dev/null | grep '[0-9]G' | sort -rn
# 2. 查找最近修改的大文件
find / -type f -mtime -1 -size +100M 2>/dev/null
# 3. 查看已删除但未释放的文件
lsof | grep deleted
# 4. 查看inode使用情况
df -i
# 5. 找出inode占用最多的目录
for i in /*; do echo $i; find $i -type f | wc -l; done经典案例:日志文件被删除但空间未释放
# 问题:rm删除了大日志文件,但df看空间没有释放
# 原因:进程仍在写入已删除的文件
# 解决方法1:找出占用进程并重启
lsof | grep deleted
kill -USR1 [nginx_pid] # 重新打开日志文件
# 解决方法2:清空文件而不是删除
> /var/log/large.log # 推荐做法五、网络故障排查技巧
5.1 网络连接故障定位
# 1. 检查网络连通性
ping -c 4 目标IP
traceroute 目标IP
mtr 目标IP # 结合ping和traceroute
# 2. 检查DNS解析
nslookup domain.com
dig +trace domain.com
# 3. 检查端口连通性
telnet IP PORT
nc -zv IP PORT
# 4. 查看连接状态
ss -antp
netstat -antp | awk '{print $6}' | sort | uniq -c
# 5. 抓包分析
tcpdump -i eth0 -nn -s0 -v port 80
tcpdump -i eth0 -w capture.pcap # 保存后用Wireshark分析5.2 TIME_WAIT过多问题
故障现象:大量TIME_WAIT连接导致端口耗尽
# 查看TIME_WAIT数量
ss -ant | grep TIME-WAIT | wc -l
# 优化内核参数
cat >> /etc/sysctl.conf << EOF
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 0 # 注意:不建议开启
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_fin_timeout = 30
EOF
sysctl -p5.3 网络性能优化
# 1. 查看网络流量
iftop -i eth0
nethogs
# 2. 查看网络错误和丢包
ip -s link show eth0
ethtool -S eth0
# 3. 优化网络缓冲区
echo'net.core.rmem_max = 134217728' >> /etc/sysctl.conf
echo'net.core.wmem_max = 134217728' >> /etc/sysctl.conf
echo'net.ipv4.tcp_rmem = 4096 87380 134217728' >> /etc/sysctl.conf
echo'net.ipv4.tcp_wmem = 4096 65536 134217728' >> /etc/sysctl.conf六、进程和服务故障处理
6.1 僵尸进程处理
# 查找僵尸进程
ps aux | grep defunct
ps aux | awk '$8 ~ /^Z/ { print }'
# 找出僵尸进程的父进程
ps -ef | grep defunct | grep -v grep | awk '{print $3}' | sort | uniq
# 处理方法
# 1. 向父进程发送SIGCHLD信号
kill -SIGCHLD [父进程PID]
# 2. 如果无效,重启父进程
systemctl restart [服务名]6.2 服务无法启动排查
# 1. 查看服务状态和日志
systemctl status service_name
journalctl -u service_name -n 50
# 2. 检查端口占用
ss -tlnp | grep :端口号
lsof -i :端口号
# 3. 检查配置文件语法
nginx -t
httpd -t
mysql --help --verbose | grep -A 1 "Default options"
# 4. 检查权限问题
ls -la /path/to/service
namei -l /path/to/service/file
# 5. 查看SELinux问题
getenforce
setenforce 0 # 临时关闭测试
ausearch -m AVC -ts recent七、系统日志分析技巧
7.1 高效的日志分析命令
# 1. 快速定位错误日志
grep -E "ERROR|WARN|FATAL" /var/log/app.log | tail -100
# 2. 统计错误频率
awk '/ERROR/ {print $1,$2}' app.log | uniq -c | sort -rn
# 3. 分析访问日志
# 统计状态码分布
awk '{print $9}' access.log | sort | uniq -c | sort -rn
# 统计慢请求
awk '$NF > 1000 {print $7,$NF}' access.log | sort -k2 -rn | head
# 4. 实时日志监控
tail -f /var/log/messages | grep --line-buffered ERROR
# 5. 多文件日志合并分析
zcat /var/log/app.log*.gz | grep ERROR | less7.2 使用journalctl高效排查
# 查看指定时间段的日志
journalctl --since "2024-01-01 00:00:00" --until "2024-01-01 01:00:00"
# 查看指定服务的日志
journalctl -u nginx.service -f
# 查看内核日志
journalctl -k
# 查看指定优先级的日志
journalctl -p err..emerg
# 导出日志for分析
journalctl -u service_name -o json > service.json八、数据库故障处理
8.1 MySQL性能问题排查
# 1. 查看慢查询
show variables like 'slow_query%';
show variables like 'long_query_time';
# 2. 查看当前执行的SQL
show processlist;
show full processlist;
# 3. 查看锁等待
show engine innodb status\G
SELECT * FROM information_schema.INNODB_LOCKS;
SELECT * FROM information_schema.INNODB_LOCK_WAITS;
# 4. 查看表锁情况
show open tables where in_use > 0;
# 5. 分析SQL执行计划
explain select * from table where condition;死锁处理案例:
-- 查看最近的死锁信息
SHOW ENGINE INNODB STATUS\G
-- 找出持有锁的事务
SELECT * FROM information_schema.INNODB_TRX\G
-- 杀掉问题事务
KILL [进程ID];8.2 Redis故障处理
# 1. 查看Redis状态
redis-cli ping
redis-cli info
# 2. 查看慢查询
redis-cli slowlog get 10
# 3. 查看客户端连接
redis-cli client list
# 4. 查看内存使用
redis-cli info memory
# 5. 紧急清理缓存
redis-cli FLUSHDB # 清空当前库
redis-cli FLUSHALL # 清空所有库(慎用)九、容器化环境故障排查
9.1 Docker容器故障
# 1. 查看容器状态
docker ps -a
docker inspect [容器ID]
# 2. 查看容器日志
docker logs --tail 100 -f [容器ID]
# 3. 进入容器排查
docker exec -it [容器ID] /bin/bash
# 4. 查看容器资源使用
docker stats
docker top [容器ID]
# 5. 查看容器网络
docker network ls
docker port [容器ID]9.2 Kubernetes故障排查
# 1. 查看Pod状态
kubectl get pods -o wide
kubectl describe pod [pod-name]
# 2. 查看Pod日志
kubectl logs -f [pod-name]
kubectl logs -f [pod-name] -c [container-name]
# 3. 进入Pod调试
kubectl exec -it [pod-name] -- /bin/bash
# 4. 查看事件
kubectl get events --sort-by=.metadata.creationTimestamp
# 5. 查看资源使用
kubectl top nodes
kubectl top pods十、自动化故障处理脚本
10.1 CPU监控告警脚本
#!/bin/bash
# CPU监控告警脚本
CPU_THRESHOLD=80
LOAD_THRESHOLD=10
# 获取CPU使用率
CPU_USAGE=$(top -bn1 | grep "Cpu(s)" | awk '{print $2}' | cut -d'%' -f1)
LOAD_AVG=$(uptime | awk -F'load average:''{print $2}' | awk '{print $1}')
# 判断并告警
if (( $(echo "$CPU_USAGE > $CPU_THRESHOLD" | bc -l) )); then
echo"警告: CPU使用率过高: ${CPU_USAGE}%"
# 发送告警通知
curl -X POST "https://your-webhook-url" \
-H "Content-Type: application/json" \
-d "{\"text\":\"CPU告警: 使用率${CPU_USAGE}%\"}"
fi
if (( $(echo "$LOAD_AVG > $LOAD_THRESHOLD" | bc -l) )); then
echo"警告: 系统负载过高: ${LOAD_AVG}"
# 记录高负载进程
ps aux --sort=-%cpu | head -10 > /tmp/high_cpu_processes.log
fi10.2 磁盘空间自动清理脚本
#!/bin/bash
# 磁盘空间自动清理脚本
THRESHOLD=80
LOG_DIR="/var/log"
DAYS_TO_KEEP=7
# 检查磁盘使用率
USAGE=$(df -h / | awk 'NR==2 {print $5}' | sed 's/%//')
if [ $USAGE -gt $THRESHOLD ]; then
echo"磁盘使用率超过${THRESHOLD}%,开始清理..."
# 清理老旧日志
find $LOG_DIR -name "*.log" -mtime +$DAYS_TO_KEEP -delete
find $LOG_DIR -name "*.gz" -mtime +$DAYS_TO_KEEP -delete
# 清理系统临时文件
find /tmp -type f -mtime +7 -delete
find /var/tmp -type f -mtime +7 -delete
# 清理包管理器缓存
yum clean all 2>/dev/null || apt-get clean 2>/dev/null
# 清理journal日志
journalctl --vacuum-time=7d
echo"清理完成,当前磁盘使用率: $(df -h / | awk 'NR==2 {print $5}')"
fi十一、故障预防和监控建设
11.1 构建完善的监控体系
关键监控指标:
-
1. 系统层面
-
• CPU使用率、Load Average
-
• 内存使用率、Swap使用情况
-
• 磁盘IO、磁盘使用率
-
• 网络流量、连接数
-
-
2. 应用层面
-
• 响应时间(P50/P90/P99)
-
• 错误率、成功率
-
• QPS/TPS
-
• 业务指标
-
-
3. 告警策略
# Prometheus告警规则示例
groups:
-name:system_alerts
rules:
-alert:HighCPUUsage
expr:100-(avg(rate(node_cpu_seconds_total{mode="idle"}[5m]))*100)>80
for:5m
labels:
severity:warning
annotations:
summary:"CPU使用率过高"
description: "CPU使用率超过80%已持续5分钟"11.2 故障演练和预案
定期进行故障演练:
-
• 模拟CPU打满场景
-
• 模拟内存泄漏
-
• 模拟磁盘故障
-
• 模拟网络分区
建立故障预案:
## 故障预案模板
### 1. 故障类型:[具体故障类型]
### 2. 故障等级:[P0/P1/P2/P3]
### 3. 影响范围:[受影响的业务和用户]
### 4. 处理流程:
1. 第一步:[具体操作]
2. 第二步:[具体操作]
3. 第三步:[具体操作]
### 5. 回滚方案:[如何回滚]
### 6. 责任人:[负责人及联系方式]十二、性能优化最佳实践
12.1 内核参数优化
# /etc/sysctl.conf 优化配置
# 网络优化
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 1
# 内存优化
vm.swappiness = 10
vm.dirty_ratio = 15
vm.dirty_background_ratio = 5
# 文件系统优化
fs.file-max = 2097152
fs.nr_open = 209715212.2 应用层优化建议
-
1. 数据库优化
-
• 合理使用索引
-
• 避免N+1查询
-
• 使用连接池
-
• 读写分离
-
-
2. 缓存策略
-
• 多级缓存架构
-
• 缓存预热
-
• 缓存更新策略
-
• 防止缓存雪崩
-
-
3. 代码优化
-
• 异步处理
-
• 批量操作
-
• 连接复用
-
• 资源池化
-
十三、运维工具推荐
13.1 必备命令行工具
# 系统性能分析
htop # 更友好的top
iotop # IO监控
iftop # 网络流量监控
sysstat # 系统统计工具集
dstat # 综合监控工具
# 进程追踪
strace # 系统调用追踪
ltrace # 库调用追踪
perf # 性能分析工具
# 网络工具
mtr # 网络诊断
nmap # 端口扫描
tcpdump # 抓包工具
ss # 套接字统计13.2 监控平台推荐
-
1. 开源方案
-
• Prometheus + Grafana
-
• Zabbix
-
• ELK Stack
-
• OpenFalcon
-
-
2. 商业方案
-
• Datadog
-
• New Relic
-
• 阿里云ARMS
-
• 腾讯云监控
-
十四、真实故障案例分享
案例1:双11电商平台宕机事件
背景:某电商平台双11期间,流量突增10倍,系统崩溃
故障现象:
-
• 用户无法下单
-
• 页面加载超时
-
• 数据库连接池耗尽
排查过程:
-
1. 发现数据库连接数达到上限
-
2. 慢查询日志显示大量全表扫描
-
3. 找到未加索引的热点查询
-
4. 紧急添加索引,连接数恢复正常
经验教训:
-
• 压测要覆盖真实场景
-
• 建立SQL审核机制
-
• 监控要设置合理阈值
案例2:Redis缓存雪崩导致服务瘫痪
故障过程:
00:00 - Redis集群某个节点宕机
00:01 - 大量请求直接打到数据库
00:03 - 数据库CPU飙升至100%
00:05 - 服务全面瘫痪解决方案:
-
1. 紧急扩容数据库
-
2. 实施限流降级
-
3. 修复Redis节点
-
4. 优化缓存策略,增加随机过期时间
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
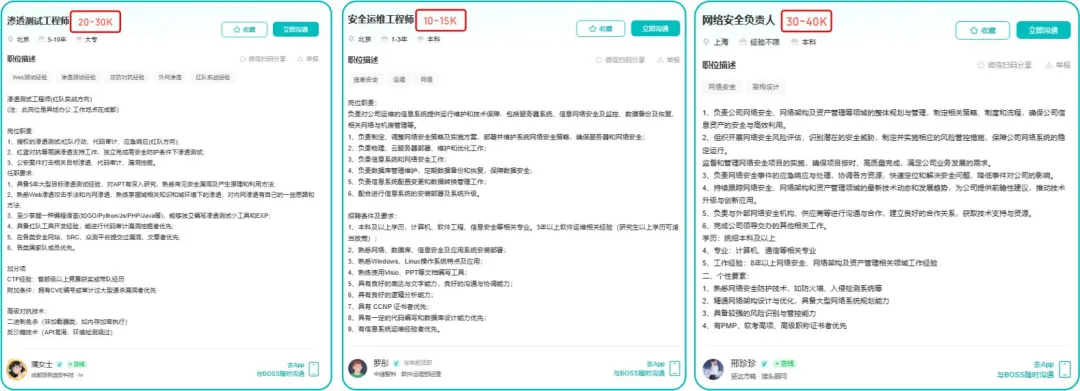
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
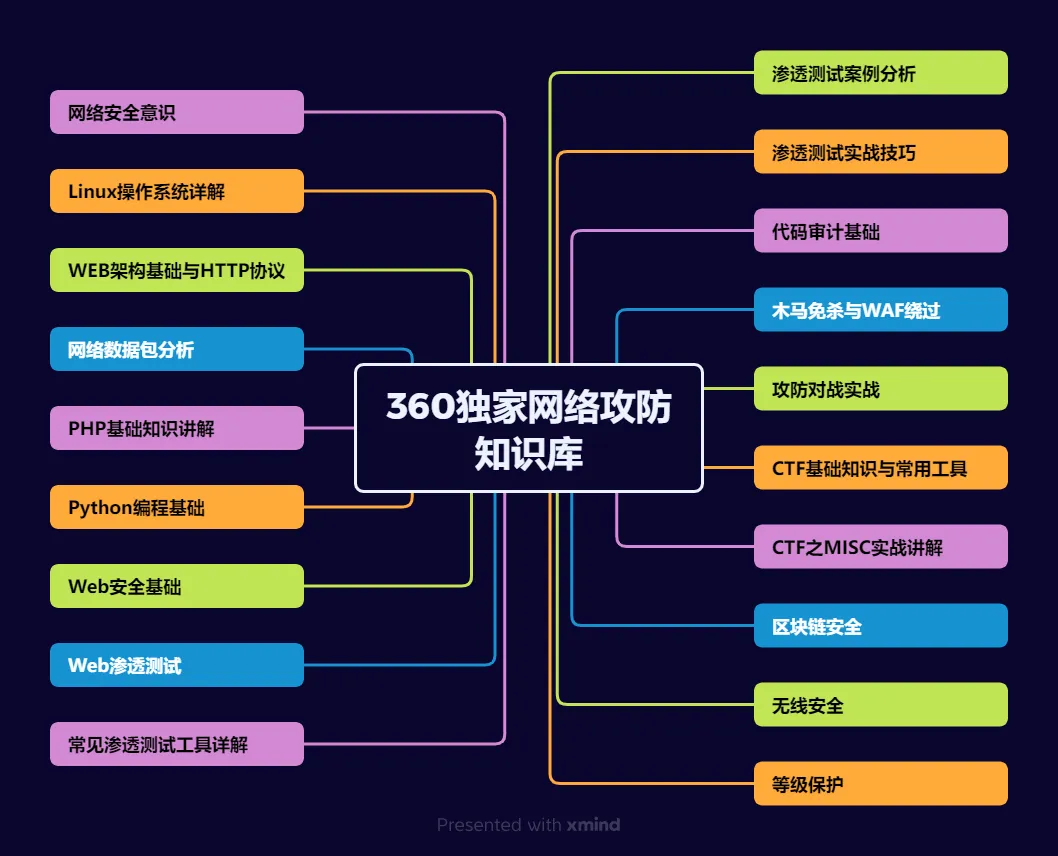
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取