



腾讯混元大模型面试,差点跪了…
是时候准备实习和面试了。
不同以往的是,当前职场已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,分享技术面试中的那些弯弯绕绕。
1. 简要介绍你了解的一两个大模型,并分析它们的区别?
答:我了解的两个大模型是 Qwen 和 DeepSeek。
以下是二者的对比:
-
开发商:Qwen 由阿里巴巴达摩院开发
-
DeepSeek 由深度求索科技(DeepSeek)开发
模型类型与效率:
-
DeepSeek 系列主打混合专家架构(MoE),通过在推理时动态选择子模块专家提升效率,且强调低训练成本设计,适合资源受限场景。
-
Qwen系列则采用传统的稠密模型架构,侧重于资源效率优化,尤其在小参数规模下(如32B)保持高性能,更适合端侧部署。
推理能力强化:
-
DeepSeek-R1 通过自我进化策略(如长链思维蒸馏)提升复杂逻辑推理能力,在数学、编程等任务中表现突出。
-
Qwen则通过领域知识蒸馏增强垂直领域适应性,例如在医学问答(Clinical Chemistry MCQs)中准确率超过人类专家。
模型规模:
-
DeepSeek 模型主打 671B 参数的混合专家架构,有 72B、32B、7B、8B 的蒸馏版本。
-
Qwen 模型规模较小且尺寸更为全面,原生支持 0.5B、1.5B、7B、14B、32B、72B 等版本,从 Qwen3 开始推出 235B 版本。
开源策略:
-
DeepSeek推行全栈开源,覆盖基础模型、蒸馏版本和部署工具链,且 API 调用成本仅为 GPT-4 的 1/30。
-
Qwen 采用部分开源策略,仅开放基础模型权重,高级功能(如领域适配模块)需商业授权。
2. 为什么大家都开始探索 MoE 架构?MoE 相比 Dense 有什么好处?
答:核心原因是因为基于 MoE 架构的模型,如 Deepseek 等表现出先进的性能,具体来说:
动态计算分配机制:MoE 通过路由器网络(Router)动态选择每个输入 token 激活的专家集合,仅需激活部分参数(如 DeepSeek-V3 激活 37B 参数,占总量 671B 的 5.5%),实现计算效率与模型规模解耦。
相较密集模型全参数激活的模式,MoE 的 FLOPs 可降低至传统架构的 30% 以下。
细粒度专家分割:DeepSeekMoE 等创新架构将单个专家分割为多个细粒度子专家(如将 FFN 隐藏维度拆分),通过组合式激活提升知识表达的灵活性。实验显示,32 个子专家配置可使模型在数学推理任务中的准确率提升 18%。
共享专家隔离技术:保留部分专家作为共享知识库(如 DeepSeekMoE 隔离 15% 共享专家),既降低参数冗余度,又增强跨领域知识迁移能力。在医疗问答测试中,该技术使模型准确率从 91% 提升至 94%。
3. Qwen LoRA 微调和全参微调的性能差距?
答:Qwen 模型的全参数微调与 LoRA 的性能差异呈现任务依赖性和参数规模敏感性特征。
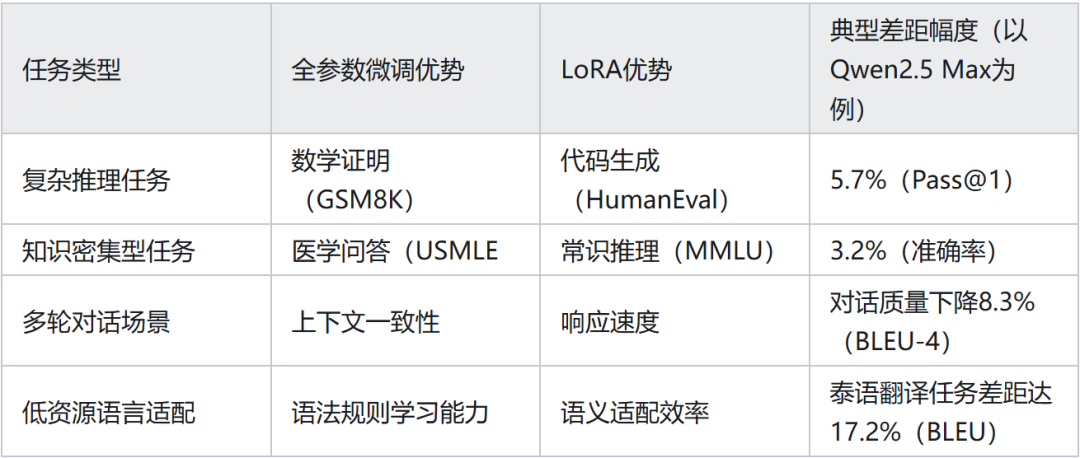
在结构化生成任务(编程、翻译)中,LoRA 性能可达全参数微调的 92%-97%。
在非结构化逻辑推理(数学证明、临床诊断)中,LoRA 性能差距扩大至全参数的 70%-85%。
对于长文本连续理解(多轮对话、学术写作),LoRA 在主题一致性指标上落后全参数微调 10% 以上。
4. 大模型训练和推理的流程?SFT 和 RLHF 的作用分别是什么?
答:训练流程:预训练+(有监督)微调+对齐。
预训练阶段:基于海量无标注数据(如互联网文本、多模态数据)进行自监督学习,通过语言建模(LM)、对比学习等任务建立通用表征能力。典型参数规模为千亿至万亿级别,需千卡级 GPU 集群训练数月。
监督微调(SFT)阶段:使用标注数据(如领域问答、指令遵循)调整模型参数,使其适配下游任务。SFT 阶段仅需 0.1%-1% 的预训练数据量即可显著提升特定任务性能。
强化学习对齐(RLHF)阶段:通过人类偏好数据训练奖励模型(Reward Model),指导大模型生成符合伦理和安全规范的内容。此阶段可将有害输出率降低 54%-78%。
5. 在 RLHF 中,目前主流的强化学习算法有哪几个?写一下损失函数表达式
直接偏好优化(DPO):

以下三个直接参考 DAPO 原文,文中都给出了总结:
近端偏好优化(PPO):

组相关偏好优化(GRPO):
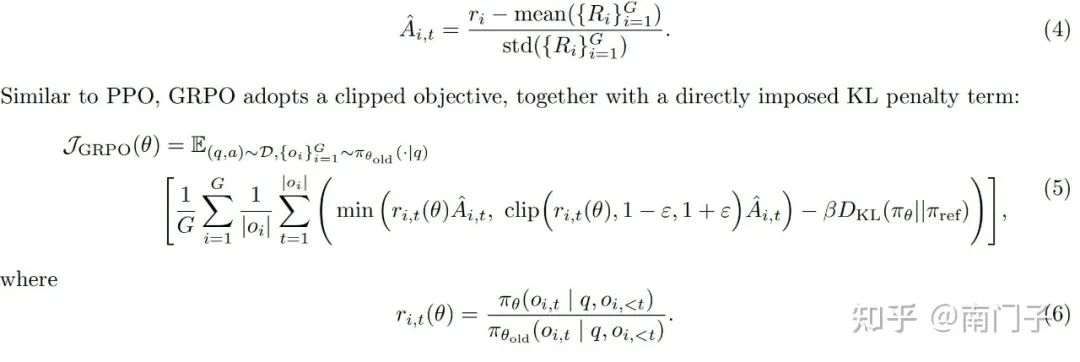
解耦裁剪和动态采样策略优化(DAPO):
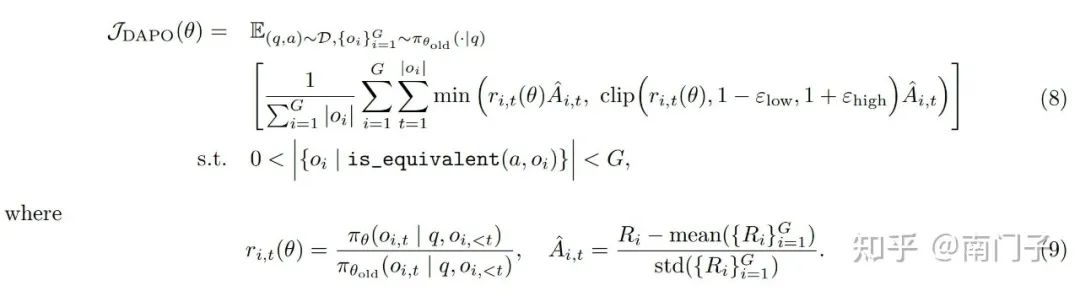
6. Deepspeed ZeRO-1,ZeRO-2,ZeR0-3 三个模式的区别是什么?
Huggingface 贴出的这张图记住就 OK 了,地址在:
https://huggingface.co/docs/trl/deepspeed_integration
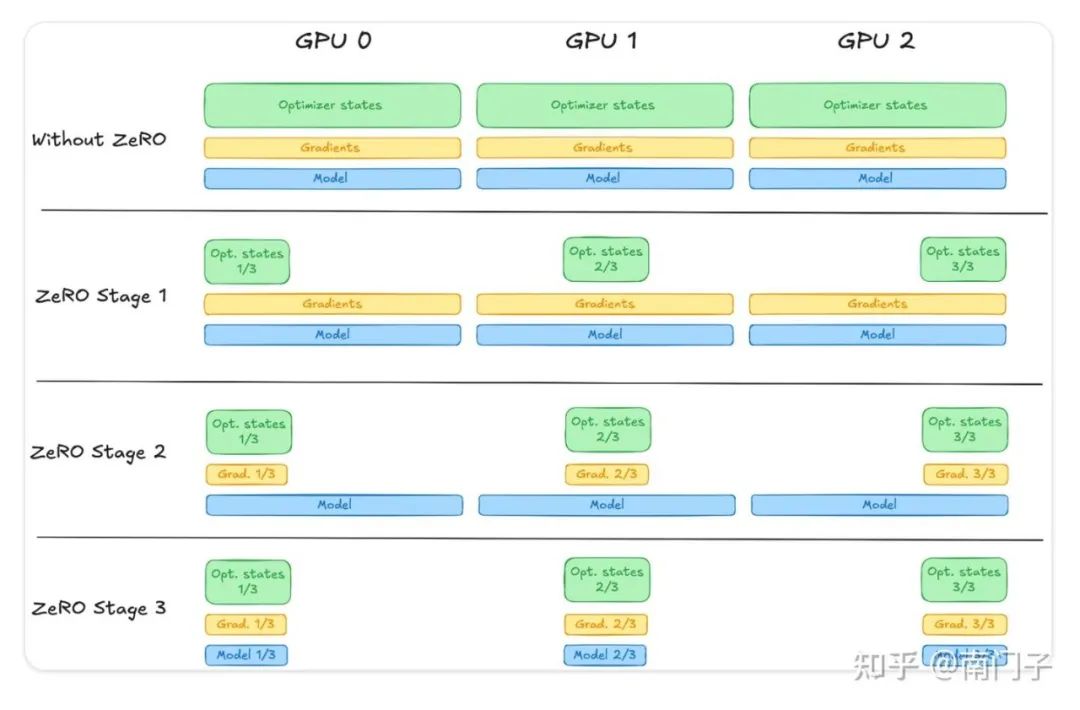
ZeRO-1:只把优化器参数平均分配到各个 GPU 上,每个 GPU 上仍然完整保存一份模型参数和梯度。
ZeRO-2:把优化器参数和梯度平均分配到各个 GPU 上,但每个 GPU 上仍然完整保存一份模型参数。
ZeRO-3:把优化器参数+梯度+模型参数都平均分配到各个 GPU 上。
7. 用 DeepSpeed ZeRO-3来微调 Qwen2-72B,每一张卡占用的显存大概是多少,估算一下为什么是占这么多的显存?
基本思路:大模型训练的显存开销主要用于存储模型参数、梯度,优化器状态,以及激活值,其中模型参数、梯度,以及激活值通常均为 fp16 格式,而优化器状态必须是 fp32 格式。
由于激活值与批大小、序列长度等因素有关,需要单独考虑。但是模型参数、梯度,以及优化器状态占用的显存是固定的,分别占用 2x、2x,以及 12x 模型参数量的显存。即训练的显存开销至少是 16x 模型参数量(以 GB 为单位)。
显存占用估算(8 卡场景):
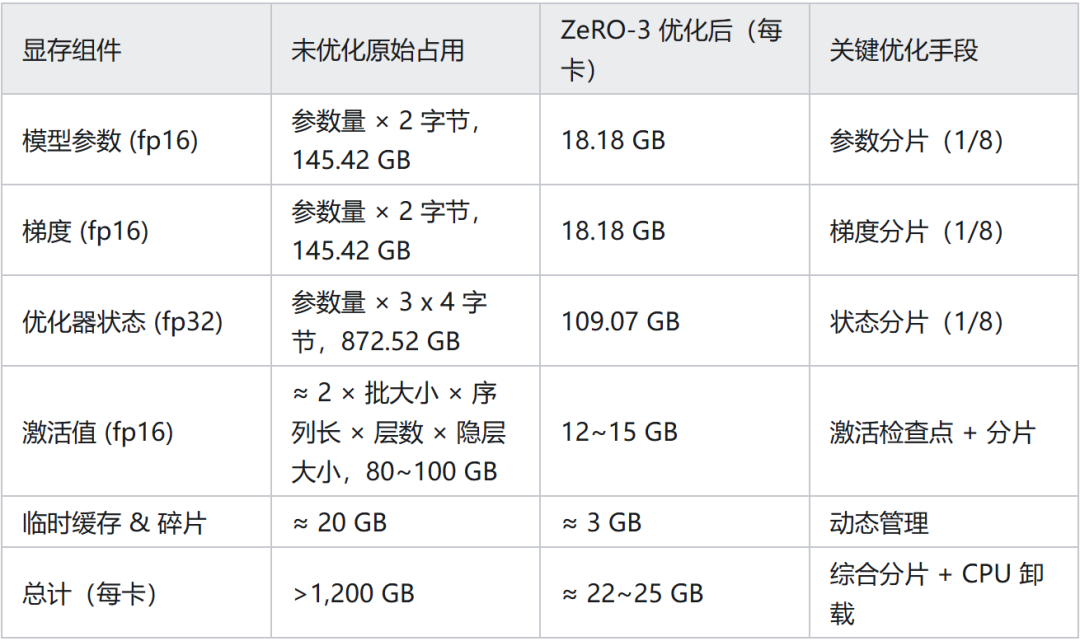
总结:
模型参数占用显存 = 参数量 × 2 GB(fp 16)
梯度占用显存 = 参数量 × 2 GB(fp 16) - 优化器状态占用显存 = 参数量 × 12 GB(fp 32)
(Adam)优化器状态包括参数备份、动量、方差三个部分,均为 fp 32 格式
实际场景:若启用 CPU/NVMe 卸载(如 offload_optimizer=cpu),每卡显存可进一步降至 15–18 GB。
8. 除了 DeepSpeed,还有什么其他的大模型训练优化方法?
混合精度训练:使用混合精度训练,保存 FP32 格式的权重副本,FP16 仅用于计算。
过程为:FP16 前向/反向计算 -> FP16 梯度 -> 转换为 FP32 -> 更新 FP32 权重副本 -> 同步至 FP16 副本。
模型并行、数据并行、混合并行(包括模型并行:(张量并行/流水线并行)+数据并行,3D 并行:数据并行+张量并行+流水线并行)
梯度累积:通过多次前向传播后再进行一次反向传播,减少显存占用。
激活检查点:激活值指神经网络中每一层输出的中间结果,即输入数据经权重计算后通过激活函数生成的输出值,计算梯度需基于前向传播的激活值。
梯度检查点(Gradient Checkpointing)核心思想:时间换空间,仅存储部分层的激活值(称为检查点),其余层在反向传播时临时重算。
激活检查点的实现步骤如下:
前向传播:
-
正常计算所有层输出
-
仅保存检查点层的输入和输出,其余激活值丢弃
反向传播:
-
从最近检查点重新前向计算该区段激活值
-
基于临时激活值计算局部梯度
-
完成后丢弃临时数据
9. LoRA 微调的原理,A和B两个矩阵怎么初始化?
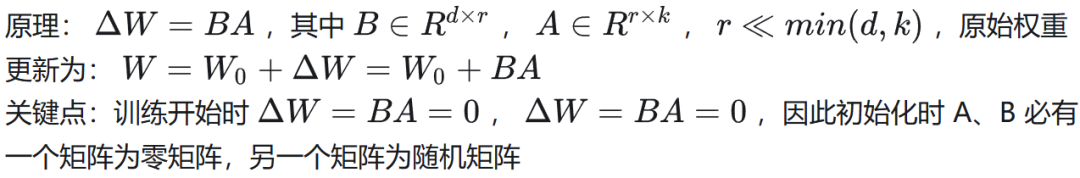
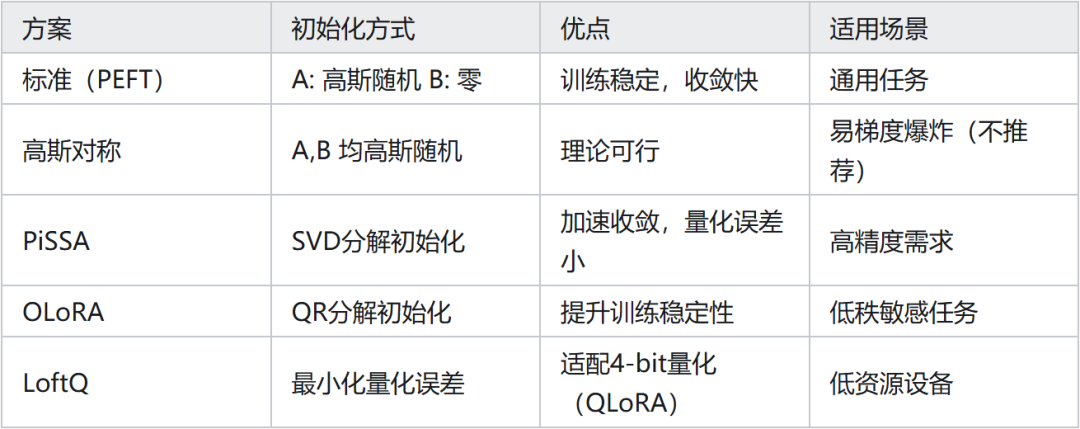
初始化方法:
10. 介绍 RLHF
人工反馈的强化学习(RLHF)一共 3 个步骤:
(1)有监督微调,通常是指令微调
(2)训练奖励模型:
生成候选回答:SFT 模型针对同一提示生成多个候选回答.
训练奖励模型:标注员对 K 候选回答(K=4 或 K=9)的质量进行排序,然后构造出交叉熵损失来训练奖励模型,每次给奖励模型两个候选回答,要求它对优质回答的打分要比劣质回答更高。
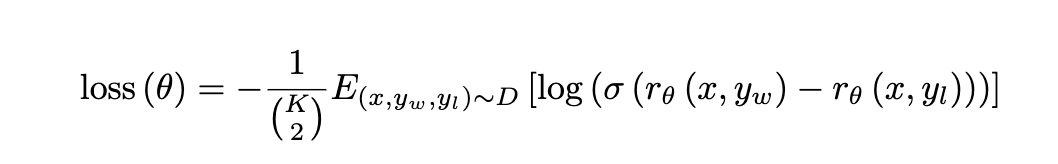
(3)强化学习:虽然使用了 PPO 算法,但也不是标准的 PPO,做出了三点改进:
-
将原版 PPO Token 级别的奖励替换为了句子级别的奖励
-
引入了 KL 正则项,以防止奖励模型的过度优化
-
加入有监督损失项,以确保模型在公开 NLP 数据集上的性能回归
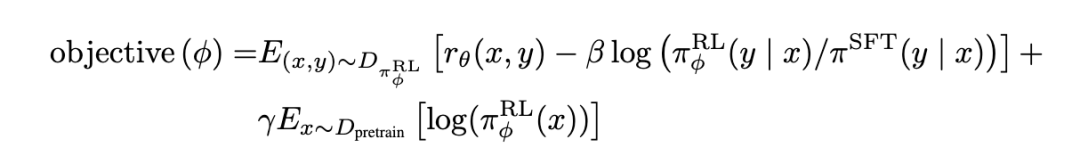
11. 在做对齐的时候,为什么 SFT 之后还要做 RLHF,只用 SFT 可以吗?
答:SFT 之后接 RLHF 是因为 SFT 仅确保了模型的语言生成能力,却不能保证生成的内容符合人类的道德和价值观。
通常不能用 SFT 来实现对齐,主要有以下两方面的原因:
学习目标不匹配:SFT 的学习目标是(理想情况下)让模型以 100% 的概率生成正确答案,而我们对大模型输出的预期是生成人类偏好的回答,二者目标不一致。
SFT 的局限性:
-
SFT 只能让模型学会什么是好的回答(只知其然),但不能让模型学会辨别什么样的回答是好的回答(而不知其所以然)
-
SFT 是 token 级的学习方法,存在暴露偏差等问题,容易导致幻觉现象的产生
代码一:22.括号生成
思路:回溯法
def generateParenthesis(self, n: int) -> List[str]:
代码二:多头注意力
class MultiHeadAttention(nn.Module):
代码三:无重复字符的最长子串
class Solution:
作者:南门子,已获作者授权发布
来源:https://zhuanlan.zhihu.com/p/1917606016717139973
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享


















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









