







.markdown-body pre,.markdown-body pre>code.hljs{color:#333;background:#f8f8f8}.hljs-comment,.hljs-quote{color:#998;font-style:italic}.hljs-keyword,.hljs-selector-tag,.hljs-subst{color:#333;font-weight:700}.hljs-literal,.hljs-number,.hljs-tag .hljs-attr,.hljs-template-variable,.hljs-variable{color:teal}.hljs-doctag,.hljs-string{color:#d14}.hljs-section,.hljs-selector-id,.hljs-title{color:#900;font-weight:700}.hljs-subst{font-weight:400}.hljs-class .hljs-title,.hljs-type{color:#458;font-weight:700}.hljs-attribute,.hljs-name,.hljs-tag{color:navy;font-weight:400}.hljs-link,.hljs-regexp{color:#009926}.hljs-bullet,.hljs-symbol{color:#990073}.hljs-built_in,.hljs-builtin-name{color:#0086b3}.hljs-meta{color:#999;font-weight:700}.hljs-deletion{background:#fdd}.hljs-addition{background:#dfd}.hljs-emphasis{font-style:italic}.hljs-strong{font-weight:700}
引言
python 内置正则表达式模块 re 提供了一个功能强大且高度灵活的工具集,使得正则表达式的使用变得更加高效和直观,本文包含了大部分使用re时会使用的功能,同时提供使用用例
使用指南
导入模块
在 Python 中,使用正则表达式功能前需要先导入 re 模块:
import re
基本语法
python使用 r"正则表达式" 来将字符串定义为模式串,用以匹配字符串,使用下方语法创建模式串
- 字符类
- 锚点
- 量词与分支
- 标志
- 组和引用
- 零宽断言
字符类
-
匹配集合中的任意*字符: `[abc]````
text = “bar ber bir bor bur”
result = re.findall(r"b[eo]r", text)
print(result) # 输出 [‘ber’, ‘bor’] -
匹配不在集合中的任意字符:`[^abc]````
text = “bar ber bir bor bur”
result = re.findall(r"b[^eo]r", text)
print(result) # 输出 [‘bar’, ‘bir’, ‘bur’] -
匹配范围:
[a-z]能够匹配a-z的26字母,除此之外还有0-9,A-Z等```
text = “bar ber bir bor bur”
result = re.findall(r"b[a-z]r", text)
print(result) # 输出 [‘bar’, ‘ber’, ‘bur’]text = “abcdefghijklmnopqrstuvwxyz”
result = re.findall(r"[e-i]", text)
print(result) # 输出 [‘e’, ‘f’, ‘g’, ‘h’, ‘i’] -
通配符匹配:`.````
result = re.findall(r".", “hi012_-!?”)
print(result) # 输出: [‘h’, ‘i’, ‘0’, ‘1’, ‘2’, ‘_’, ‘-’, ‘!’, ‘?’] -
匹配字母、数字或下划线: `\w````
text = “hi012_-!? foo_bar123”
result = re.findall(r"\w", text)
print(result) # 输出: [‘h’, ‘i’, ‘0’, ‘1’, ‘2’, ‘f’, ‘o’, ‘o’, ‘b’, ‘a’, ‘r’, ‘1’, ‘2’, ‘3’] -
匹配除字母、数字和下划线之外的任意字符: `\W````
text = “hi012_-!? foo_bar123”
result = re.findall(r"\w", text)
print(result) # 输出: [‘-’, ‘-’, ‘!’, ‘?’, ’ '] -
匹配所有数字: `\d````
text = “Call 123-456-7890!”
result = re.findall(r"\D", text)
print(result) # 输出: [‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘0’] -
匹配除数字外的任意字符 `\D````
text = “Call 123-456-7890!”
result = re.findall(r"\D", text)
print(result) # 输出: [‘C’, ‘a’, ‘l’, ‘l’, ’ ', ‘-’, ‘-’, ‘!’] -
匹配所有空白字符: `\s````
text = “Hello World!\nThis is a test.”
result = re.findall(r"\s", text) print(result) # 输出: [’ ', ‘\n’, ’ ', ’ ', ’ '] -
匹配除空白字符以外的任意字符: `\S````
text = “Hello World!\n”
result = re.findall(r"\S", text)
print(result) # 输出: [‘H’, ‘e’, ‘l’, ‘l’, ‘o’, ‘W’, ‘o’, ‘r’, ‘l’, ‘d’, ‘!’]
```
- 匹配特殊字符:
\在正则表达式中,反斜杠\是转义字符,因此需要使用双反斜杠\\来匹配实际的反斜杠字符,使用\.来表示.,使用\+来表示+,等字符```
text = r"This is a path: C:\Users\Name\Documents and \Settings"
# 匹配所有反斜杠
result = re.findall(r"\\", text)
print(result) # 输出: ['\\', '\\', '\\', '\\', '\\']
```
锚点
-
匹配字符串或行的开头: `^````
text = “an answer or a question”
result = re.findall(r"^\w+", text)
print(result) # 输出: [‘an’] -
匹配字符串或行的结尾: `KaTeX parse error: Undefined control sequence: \w at position 61: …= re.findall(r"\̲w̲+", text)
print(result) # 输出: [‘question’] -
匹配单词的开头或结尾: `\b````
text = “an answer or a question”
result = re.findall(r"n\b", text)
print(result) # 输出: [‘n’, ‘n’]这里匹配的是位于单词结尾的n 匹配的是an和question
-
匹配不在单词开头或末尾的位置:`\B````
text = “an answer or a question”
result = re.findall(r"n\B", text)
print(result) # 输出: [‘n’]这里匹配的是不在单词结尾的n 匹配的是answer
量词与分支
-
匹配一个或多个:`+````
text = “bp bep beep beeep”
result = re.findall(r"be+p", text)
print(result) # 输出: [‘bep’, ‘beep’, ‘beeep’] -
匹配零个或多个:`````
text = “bp bep beep beeep”
result = re.findall(r"bep", text)
print(result) # 输出: [‘bp’, ‘bep’, ‘beep’, ‘beeep’] -
匹配指定范围:`{n, m}````
text = “bp bep beep beeep”
result = re.findall(r"be{1,2}p", text)
print(result) # 输出: [‘bep’, ‘beep’] -
匹配可选: `?````
text = “color colour colr”
result = re.findall(r"colou?r", text)
print(result) # 输出: [‘color’, ‘colour’] -
分支条件: `|````
text = “fat cat rat”
result = re.findall(r"cat|rat", text)
print(result) # 输出: [‘cat’, ‘rat’]可以与()结合使用
text = “Error 404: Page not found. Error 500: Internal server error.”
pattern =
result = re.findall(r"Error (404|500)", text)匹配 “Error 404” 或 “Error 500”
print(result) # 输出: [‘404’, ‘500’]
使用findall函数,若正则表达式中有分组(),则只返回分组中内容
标志
-
忽略大小写:`re.I````
text = “CaT cat cAt”
result = re.findall(r"cat", text, flags=re.I)
print(result) # 输出: [‘CaT’, cat, cAt] -
多行模式:
re.M主要针对^和$,添加后可以匹配到每一行的行头和行尾,否则只能匹配到整个字符串的开头和末尾```
multiline_text = “cat\ncat\ncat”result = re.findall(r"^cat", multiline_text)
print(result) # 输出: [‘cat’]result = re.findall(r"^cat", multiline_text, flags=re.M)
print(result) # 输出: [‘cat’, ‘cat’, ‘cat’] -
添加注释:
re.X可以使用"""和#为自己写的正则表达式添加注释```
a = re.compile(r"“”\d + # the integral part
. # the decimal point
\d * # some fractional digits"“”, re.X)
b = re.compile(r"\d+.\d*")这两者的效果相等
组和引用
如果在findall中使用分组,只会返回匹配成功后分组内的内容
-
使用括号分组:
()用于将正则表达式的一部分组合在一起,方便后续应用量词或提取数据```
text = “hahaha hah haha”匹配重复的 “ha”
result = re.findall(r"(ha)+", text)
匹配到 hahaha ha haha
print(result) # 输出: [‘ha’, ‘ha’, ‘ha’]
-
引用表达式的分组:
\1,\2, …\1引用第一个分组,\2引用第二个分组,依此类推```
text = “hah haa dad”匹配模式是 “某字符 + a + 相同字符”
result = re.findall(r"(\w)a\1", text)
匹配到 haa dad
print(result) # 输出: [‘h’, ‘d’]
-
创建无法引用的分组:
(?: )(?: )表示一个非捕获分组,不会存储匹配内容```
text = “hahaha hah haha”匹配 “ha” 多次,但不捕获分组内容
result = re.findall(r"(?:ha)+", text)
print(result) # 输出: [‘hahaha’, ‘ha’, ‘haha’]使用正常分组的结果:[‘ha’, ‘ha’, ‘ha’]
text = “hah haa dad”
re.findall(r"(?:\w)a\1", text) # 抛错 -
分组命名:`(?P…)````
text = “apple=apple banana=orange grape=grape”
result = re.findall(r"(?P\w+)=(?P=word)", text)
print(result) # 输出:[‘apple’, ‘grape’](?P\w+) 定义了一个名为 word 的分组,匹配一个单词
(?P=word) 引用了分组 word 的内容,要求后面的部分与前面的单词一致
验证HTML标签的正确配对
pattern = r"<(?P\w+)>.*?</(?P=tag)>"
text = “contenttext
another”
result = re.findall(pattern, text)
print(result) # 输出:[(‘div’,), (‘p’,)](?P\w+) 定义了一个名为 tag 的分组,用来匹配 HTML 标签名称
</(?P=tag)> 引用了 tag 分组,要求结束标签与开始标签名称一致
零宽断言
零宽断言匹配的是位置,而不是字符
-
正向前瞻:
(?=...)匹配满足某条件的前一个字符或位置。```
text = “1st 2nd 3pc”匹配数字后面跟着 “nd” 的情况
result = re.findall(r"\d(?=nd)", text)
print(result) # 输出: [‘2’] -
负向前瞻:
(?!...)匹配不满足某条件的前一个字符或位置```
text = “1st 2nd 3pc”匹配数字后面不是 “nd” 的情况
result = re.findall(r"\d(?!nd)", text)
print(result) # 输出: [‘1’, ‘3’] -
正向后瞻:
(?<=...)匹配满足某条件的后一个字符或位置```
text = “#1 $2 %3”匹配 “前面是 %” 的数字
result = re.findall(r"(?<=%)\d", text)
print(result) # 输出: [‘3’] -
负向后瞻:
(?<!...)匹配不满足某条件的后一个字符或位置```
text = “#1 $2 %3”匹配 “前面不是 %” 的数字
result = re.findall(r"(?<!%)\d", text)
print(result) # 输出: [‘1’, ‘2’]
贪婪模式与非贪婪模式
python默认就是贪婪模式,在量词后添加?可以变成非贪婪模式
贪婪模式
* 、+会尽量多地匹配字符,直到无法再匹配为止
text = "<h1>Title</h1><p>Paragraph</p>"
# 贪婪模式:匹配整个 HTML 标签内容
result = re.search(r'<.*>', text)
print(result.group()) # 输出: <h1>Title</h1><p>Paragraph</p>
非贪婪模式
*?、+?会尽量少地匹配字符,通常在满足匹配条件时就停止
text = "<h1>Title</h1><p>Paragraph</p>"
# 非贪婪模式:只匹配第一个 HTML 标签内容
result = re.search(r'<.*?>', text)
print(result.group()) # 输出: <h1>
核心函数
re.compile(pattern, flags=0)
作用:将正则表达式模式串编译成一个正则表达式对象,后续可以多次使用,提高匹配效率 参数:
pattern:字符串类型,正则表达式模式串flags(可选):匹配模式,通常是re.M,re.I等
返回:返回一个 Pattern 对象
示例:
pattern = re.compile(r"\d{3}-\d{2}-\d{4}")
result = pattern.match("123-45-6789")
print(result.group()) # 输出: 123-45-6789
re.search(pattern, string, flags=0)
作用:扫描整个字符串,查找第一个匹配正则表达式的子串,返回一个匹配对象 match,如果没有找到匹配,返回 None 参数:
pattern:字符串类型,正则表达式模式串string:要进行匹配的目标字符串flags(可选):匹配模式,通常是re.M,re.I等
返回:返回一个 Match 对象,或者如果没有找到匹配,返回 None
示例:
result = re.search(r"\d{3}-\d{2}-\d{4}", "My number is 123-45-6789")
if result:
print(result.group()) # 输出: 123-45-6789
re.match(pattern, string, flags=0)
作用:尝试从字符串的开头开始匹配,如果开头的部分匹配正则表达式,则返回一个匹配对象。如果匹配失败,则返回 None 参数:
pattern:字符串类型,正则表达式模式串string:要进行匹配的目标字符串flags(可选):匹配模式,通常是re.M,re.I等
返回:返回一个 Match 对象,或者如果没有匹配,返回 None
示例:
result = re.match(r"\d{3}-\d{2}-\d{4}", "123-45-6789")
if result:
print(result.group()) # 输出: 123-45-6789
re.fullmatch(pattern, string, flags=0)
作用:如果整个字符串完全匹配正则表达式,则返回匹配对象。如果只有部分匹配,则返回 None 参数:
pattern:字符串类型,正则表达式模式串string:要进行匹配的目标字符串flags(可选):匹配模式,通常是re.M,re.I等
返回:返回一个 Match 对象,或者如果没有匹配,返回 None
示例:
result = re.fullmatch(r"\d{3}-\d{2}-\d{4}", "123-45-6789")
if result:
print(result.group()) # 输出: 123-45-6789
result = re.fullmatch(r"\d{3}-\d{2}-\d{4}", "123-45-678910")
print(result) # 输出: None
re.split(pattern, string, maxsplit=0, flags=0)
作用:根据正则表达式匹配的分隔符分割字符串,返回一个列表 参数:
pattern:字符串类型,正则表达式模式串string:要进行匹配的目标字符串maxsplit(可选):最大分割次数。如果指定了maxsplit,则只进行maxsplit次分割flags(可选):匹配模式,通常是re.M,re.I等
返回:返回一个列表,包含分割后的子串
示例:
result = re.split(r"\s+", "This is a test string")
print(result) # 输出: ['This', 'is', 'a', 'test', 'string']
result = re.split(r'\W+', 'Words, words, words.', maxsplit=1)
print(result) #输出:['Words', 'words, words.']
re.findall(pattern, string, flags=0)
作用:返回所有匹配项的列表,每个匹配项是一个字符串,如果有捕获组,则返回捕获组内容 参数:
pattern:字符串类型,正则表达式模式串string:要进行匹配的目标字符串flags(可选):匹配模式,通常是re.M,re.I等
返回:返回一个列表,包含所有匹配的子串
示例:
result = re.findall(r"\d+", "123 abc 456 def 789")
print(result) # 输出: ['123', '456', '789']
re.finditer(pattern, string, flags=0)
作用:类似于 findall(),但返回的是一个迭代器,每个元素是一个 match 对象,可以获取匹配的具体信息(如位置) 参数:
pattern:字符串类型,正则表达式模式串string:要进行匹配的目标字符串flags(可选):匹配模式,通常是re.M,re.I等
返回:返回一个迭代器,迭代每个匹配的 Match 对象
示例:
text = "abc123def456ghi789"
matches = re.finditer(r"\d+", text)
for match in matches:
print(f"Matched: {match.group()}, Start: {match.start()}, End: {match.end()}")
# 输出:
# Matched: 123, Start: 3, End: 6
# Matched: 456, Start: 9, End: 12
# Matched: 789, Start: 15, End: 18
re.sub(pattern, repl, string, count=0, flags=0)
作用:用指定的替换字符串替换正则表达式匹配的所有部分,返回替换后的字符串 参数:
pattern:字符串类型,正则表达式模式串repl:用于替换的字符串string:要进行匹配的目标字符串count(可选):替换的最大次数,默认替换所有匹配项flags(可选):匹配模式,通常是re.M,re.I等
返回:返回替换后的字符串
示例:
result = re.sub(r"\d+", "X", "123 abc 456 def 789")
print(result) # 输出: X abc X def X
re.subn(pattern, repl, string, count=0, flags=0)
作用:与sub()类似,但返回的是一个元组 (替换后的字符串, 替换次数) 参数:
pattern:字符串类型,正则表达式模式串repl:用于替换的字符串string:要进行匹配的目标字符串count(可选):替换的最大次数,默认替换所有匹配项flags(可选):匹配模式,通常是re.M,re.I等
返回:返回一个元组,包含替换后的字符串和替换的次数
示例:
result = re.subn(r"\d+", "X", "123 abc 456 def 789")
print(result) # 输出: ('X abc X def X', 3)
re.escape(pattern)
作用:对字符串中的特殊字符进行转义,使它们能够作为普通字符使用,返回转义后的字符串 参数:
pattern:要进行转义的字符串
返回:返回转义后的字符串
示例:
result = re.escape("Hello. How are you?")
print(result) # 输出: Hello\. How are you\?
核心对象
Match对象
Match 对象通常由 re.match(), re.search(), re.finditer()等函数返回
属性:
-
string:原始输入字符串```
match = re.match(r"(\d+)-(\d+)", “123-456-234”)
print(match.group()) # 输出:123-456
print(match.string) # 输出:123-456-234 -
pos:匹配的起始位置(相对于原字符串的偏移量)```
match = re.match(r"(\d+)-(\d+)", “123-456-234”)
print(match.pos) # 输出:0 -
endpos:匹配的结束位置(相对于原字符串的偏移量),结束是指最后一个匹配字符的后一位```
match = re.match(r"(\d+)-(\d+)", “123-456-234”)
print(match.endpos) # 输出:11 -
lastgroup:返回最后一个捕获组的名称(如果有命名组)```
match = re.match(r"(?P\d+)-(?P\d+)", “123-456”)命名第一个分组为first,第二个分组为second
print(match.lastgroup) # 输出: second
-
lastindex:返回最后一个捕获组的索引(数字表示)```
match = re.match(r"(\d+)-(\d+)", “123-456”)
print(match.lastindex) # 输出: 2
方法:
-
group([group1, …]): 返回匹配的子字符串或多个子字符串,如果没有指定参数,返回整个匹配内容,如果指定了参数,返回指定组的内容```
match = re.match(r"(\d+)-(\d+)", “123-456”)不使用分组也能输出
print(match.group()) # 输出: ‘123-456’
使用分组后才能输出,否则会报错
print(match.group(1)) # 输出: ‘123’
print(match.group(2)) # 输出: ‘456’ -
start([group]):返回匹配的起始位置,如果指定了组号,返回该组匹配的起始位置```
match = re.match(r"(\d+)-(\d+)", “abc-123-456”)
print(match.start(1)) # 输出: 0 (组 1 匹配的开始位置)match = re.search(r"(\d+)-(\d+)", “abc-123-456”)
print(match.start(1)) # 输出:4 -
end([group]):回匹配的结束位置,如果指定了组号,返回该组匹配的结束位置,结束是指最后一个匹配字符的后一位```
match = re.match(r"(\d+)-(\d+)", “123-456”)
print(match.end(1)) # 输出: 3 (组 1 匹配的结束位置)
print(match.end()) # 输出:7 -
span([group]):返回匹配的
(start, end)位置元组,表示匹配的起始和结束位置,结束是指最后一个匹配字符的后一位```
match = re.match(r"(\d+)-(\d+)", “123-456”)
print(match.span(2)) # 输出: (4, 7) -
groupdict(default=None):返回一个字典,其中键为命名的分组名,值为分组匹配到的内容,如果某个命名分组没有匹配内容,则返回
default参数的值```
text = “2024-12-23”
pattern = r"(?P\d{4})-(?P\d{2})-(?P\d{2})"
print(match.groupdict()) # 输出:{‘year’: ‘2024’, ‘month’: ‘12’, ‘day’: ‘23’}pattern = r"(?P\d{4})-(?P\d{2})-(?P\d{2})-?(?P
-
expand(template):使用指定的模板格式化匹配结果,模板中的
\g<name>或\number表示引用命名分组或捕获组```
pattern = r"(?P<area_code>\d{3})-(?P\d{7})"
text = “123-4567890”引用命名分组
match = re.match(pattern, text)
print(match.expand(r"(\g<area_code>) \g")) # 输出: (123) 4567890引用分组编号
match = re.match(r"(\d{3})-(\d{7})“, text)
print(match.expand(r”(\1) \2")) # 输出: (123) 4567890
Pattern对象
Pattern 对象是通过 re.compile() 编译正则表达式后得到的对象,它代表了一个正则表达式的预编译版本,可以重复使用,以提高性能
属性:
-
flags: 返回用于编译正则表达式时所用的标志(flags)```
pattern = re.compile(r"(?i)hello", re.M)
print(pattern.flags) # 输出: 42
print(pattern.flags & re.MULTILINE) # 输出:re.MULTILINE
print(pattern.flags & re.S) # 输出:re.NOFLAG -
groups:返回模式中捕获组的数量(即括号
()的个数),非捕获组(?:...)不会计入捕获组数```
pattern = re.compile(r"(a)(b©)")
print(pattern.groups) # 输出: 3 (对应: a, b, c) -
groupindex:返回一个字典,映射命名分组的名称到对应的分组编号,如果没有使用命名分组,则返回空字典```
pattern = re.compile(r"(?Pa)(?Pb)")
print(pattern.groupindex) # 输出: {‘first’: 1, ‘second’: 2}pattern = re.compile(r"(a)(b)")
print(pattern.groupindex) # 输出: {} -
pattern:返回原始的正则表达式字符串```
pattern = re.compile(r"hello\d+")
print(pattern.pattern) # 输出: hello\d+
方法:
-
search(string[, pos[, endpos]]):在字符串中搜索第一个匹配的子字符串,返回一个
Match对象;如果没有匹配,返回None- 参数:
string:要匹配的目标字符串pos:开始搜索的位置,默认为 0endpos:结束搜索的位置,默认为字符串的长度
pattern = re.compile(r"\d+") match = pattern.search("abc123xyz456") print(match.group()) # 输出: 123 - 参数:
-
match(string[, pos[, endpos]]):从字符串的开头匹配,如果匹配成功,返回一个
Match对象,否则返回None- 参数:
string:要匹配的目标字符串pos:开始搜索的位置,默认为 0endpos:结束搜索的位置,默认为字符串的长度
pattern = re.compile(r"\d+") match = pattern.match("123abc") print(match.group()) # 输出: 123 - 参数:
-
fullmatch(string[, pos[, endpos]]): 尝试将整个字符串与正则模式完全匹配,匹配成功则返回
Match对象;否则返回None- 参数:
string:要匹配的目标字符串pos:开始搜索的位置,默认为 0endpos:结束搜索的位置,默认为字符串的长度
pattern = re.compile(r"\d+") match = pattern.fullmatch("123") print(match.group()) # 输出: 123 - 参数:
-
split(string, maxsplit=0):使用正则表达式的匹配结果分割字符串,返回一个列表
- 参数:
string:要匹配的目标字符串maxsplit:最大分割次数,默认为 0 表示分割所有可能的位置
pattern = re.compile(r"\s+") result = pattern.split("a b c d") print(result) # 输出: ['a', 'b', 'c', 'd'] - 参数:
-
findall(string[, pos[, endpos]]):返回所有匹配项的列表,每个匹配项是一个字符串;如果有捕获组,则返回捕获组内容
- 参数:
string:要匹配的目标字符串pos:开始搜索的位置,默认为 0endpos:结束搜索的位置,默认为字符串的长度
pattern = re.compile(r"\d+") result = pattern.findall("abc123xyz456") print(result) # 输出: ['123', '456'] - 参数:
-
finditer(string[, pos[, endpos]]):类似于
findall(),但返回的是一个迭代器,每个元素是一个match对象- 参数:
string:要匹配的目标字符串pos:开始搜索的位置,默认为 0endpos:结束搜索的位置,默认为字符串的长度
pattern = re.compile(r"\d+") for match in pattern.finditer("abc123xyz456"): print(match.group()) # 输出: # 123 # 456 - 参数:
-
sub(repl, string, count=0):用指定的替换字符串替换正则表达式匹配的所有部分,返回替换后的字符串
- 参数:
repl:替换的内容,可以是字符串或函数string:目标字符串count:替换次数,默认为 0 表示替换所有匹配项
pattern = re.compile(r"\d+") result = pattern.sub("0", "abc123xyz456") print(result) # 输出: abc0xyz0 - 参数:
-
subn(repl, string, count=0):与
sub()类似,但返回的是一个元组(替换后的字符串, 替换次数)- 参数:
repl:替换的内容,可以是字符串或函数string:目标字符串count:替换次数,默认为 0 表示替换所有匹配项
pattern = re.compile(r"\d+") result = pattern.sub("0", "abc123xyz456") print(result) # 输出: ("abc0xyz0", 2) - 参数:
小结
本指南从基础到进阶,详细介绍了 re 模块的核心功能,并通过丰富的示例帮助您掌握其应用技巧,希望本文能够为深入学习正则表达式的读者提供启发,同时也为初学者实践打下坚实的基础
黑客/网络安全学习路线
对于从来没有接触过黑客/网络安全的同学,目前网络安全、信息安全也是计算机大学生毕业薪资相对较高的学科。
大白也帮大家准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
这也是耗费了大白近四个月的时间,吐血整理,文章非常非常长,觉得有用的话,希望粉丝朋友帮忙点个**「分享」「收藏」「在看」「赞」**
网络安全/渗透测试法律法规必知必会****
今天大白就帮想学黑客/网络安全技术的朋友们入门必须先了解法律法律。
【网络安全零基础入门必知必会】什么是黑客、白客、红客、极客、脚本小子?(02)
【网络安全零基础入门必知必会】网络安全专业术语全面解析(05)
【网络安全入门必知必会】《中华人民共和国网络安全法》(06)
【网络安全零基础入门必知必会】《计算机信息系统安全保护条例》(07)
【网络安全零基础入门必知必会】《中国计算机信息网络国际联网管理暂行规定》(08)
【网络安全零基础入门必知必会】《计算机信息网络国际互联网安全保护管理办法》(09)
【网络安全零基础入门必知必会】《互联网信息服务管理办法》(10)
【网络安全零基础入门必知必会】《计算机信息系统安全专用产品检测和销售许可证管理办法》(11)
【网络安全零基础入门必知必会】《通信网络安全防护管理办法》(12)
【网络安全零基础入门必知必会】《中华人民共和国国家安全法》(13)
【网络安全零基础入门必知必会】《中华人民共和国数据安全法》(14)
【网络安全零基础入门必知必会】《中华人民共和国个人信息保护法》(15)
【网络安全零基础入门必知必会】《网络产品安全漏洞管理规定》(16)
网络安全/渗透测试linux入门必知必会
【网络安全零基础入门必知必会】什么是Linux?Linux系统的组成与版本?什么是命令(01)
【网络安全零基础入门必知必会】VMware下载安装,使用VMware新建虚拟机,远程管理工具(02)
【网络安全零基础入门必知必会】VMware常用操作指南(非常详细)零基础入门到精通,收藏这一篇就够了(03)
【网络安全零基础入门必知必会】CentOS7安装流程步骤教程(非常详细)零基入门到精通,收藏这一篇就够了(04)
【网络安全零基础入门必知必会】Linux系统目录结构详细介绍(05)
【网络安全零基础入门必知必会】Linux 命令大全(非常详细)零基础入门到精通,收藏这一篇就够了(06)
【网络安全零基础入门必知必会】linux安全加固(非常详细)零基础入门到精通,收藏这一篇就够了(07)
网络安全/渗透测试****计算机网络入门必知必会****
【网络安全零基础入门必知必会】TCP/IP协议深入解析(非常详细)零基础入门到精通,收藏这一篇就够了(01)
【网络安全零基础入门必知必会】什么是HTTP数据包&Http数据包分析(非常详细)零基础入门到精通,收藏这一篇就够了(02)
【网络安全零基础入门必知必会】计算机网络—子网划分、子网掩码和网关(非常详细)零基础入门到精通,收藏这一篇就够了(03)
网络安全/渗透测试入门之HTML入门必知必会
【网络安全零基础入门必知必会】什么是HTML&HTML基本结构&HTML基本使用(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全零基础入门必知必会】VScode、PhpStorm的安装使用、Php的环境配置,零基础入门到精通,收藏这一篇就够了2
【网络安全零基础入门必知必会】HTML之编写登录和文件上传(非常详细)零基础入门到精通,收藏这一篇就够了3
网络安全/渗透测试入门之Javascript入门必知必会
【网络安全零基础入门必知必会】Javascript语法基础(非常详细)零基础入门到精通,收藏这一篇就够了(01)
【网络安全零基础入门必知必会】Javascript实现Post请求、Ajax请求、输出数据到页面、实现前进后退、文件上传(02)
网络安全/渗透测试入门之Shell入门必知必会
【网络安全零基础入门必知必会】Shell编程基础入门(非常详细)零基础入门到精通,收藏这一篇就够了(第七章)
网络安全/渗透测试入门之PHP入门必知必会
【网络安全零基础入门】PHP环境搭建、安装Apache、安装与配置MySQL(非常详细)零基础入门到精通,收藏这一篇就够(01)
【网络安全零基础入门】PHP基础语法(非常详细)零基础入门到精通,收藏这一篇就够了(02)
【网络安全零基础入门必知必会】PHP+Bootstrap实现表单校验功能、PHP+MYSQL实现简单的用户注册登录功能(03)
网络安全/渗透测试入门之MySQL入门必知必会
【网络安全零基础入门必知必会】MySQL数据库基础知识/安装(非常详细)零基础入门到精通,收藏这一篇就够了(01)
【网络安全零基础入门必知必会】SQL语言入门(非常详细)零基础入门到精通,收藏这一篇就够了(02)
【网络安全零基础入门必知必会】MySQL函数使用大全(非常详细)零基础入门到精通,收藏这一篇就够了(03)
【网络安全零基础入门必知必会】MySQL多表查询语法(非常详细)零基础入门到精通,收藏这一篇就够了(04)
****网络安全/渗透测试入门之Python入门必知必会
【网络安全零基础入门必知必会】之Python+Pycharm安装保姆级教程,Python环境配置使用指南,收藏这一篇就够了【1】
【网络安全零基础入门必知必会】之Python编程入门教程(非常详细)零基础入门到精通,收藏这一篇就够了(2)
python入门教程python开发基本流程控制if … else
python入门教程之python开发可变和不可变数据类型和hash
【网络安全零基础入门必知必会】之10个python爬虫入门实例(非常详细)零基础入门到精通,收藏这一篇就够了(3)
****网络安全/渗透测试入门之SQL注入入门必知必会
【网络安全渗透测试零基础入门必知必会】之初识SQL注入(非常详细)零基础入门到精通,收藏这一篇就够了(1)
【网络安全渗透测试零基础入门必知必会】之SQL手工注入基础语法&工具介绍(2)
【网络安全渗透测试零基础入门必知必会】之SQL注入实战(非常详细)零基础入门到精通,收藏这一篇就够了(3)
【网络安全渗透测试零基础入门必知必会】之SQLmap安装&实战(非常详细)零基础入门到精通,收藏这一篇就够了(4)
【网络安全渗透测试零基础入门必知必会】之SQL防御(非常详细)零基础入门到精通,收藏这一篇就够了(4)
****网络安全/渗透测试入门之XSS攻击入门必知必会
【网络安全渗透测试零基础入门必知必会】之XSS攻击基本概念和原理介绍(非常详细)零基础入门到精通,收藏这一篇就够了(1)
网络安全渗透测试零基础入门必知必会】之XSS攻击获取用户cookie和用户密码(实战演示)零基础入门到精通收藏这一篇就够了(2)
【网络安全渗透测试零基础入门必知必会】之XSS攻击获取键盘记录(实战演示)零基础入门到精通收藏这一篇就够了(3)
【网络安全渗透测试零基础入门必知必会】之xss-platform平台的入门搭建(非常详细)零基础入门到精通,收藏这一篇就够了4
【网络安全渗透测试入门】之XSS漏洞检测、利用和防御机制XSS游戏(非常详细)零基础入门到精通,收藏这一篇就够了5
****网络安全/渗透测试入门文件上传攻击与防御入门必知必会
【网络安全渗透测试零基础入门必知必会】之什么是文件包含漏洞&分类(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全渗透测试零基础入门必知必会】之cve实际漏洞案例解析(非常详细)零基础入门到精通, 收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之PHP伪协议精讲(文件包含漏洞)零基础入门到精通,收藏这一篇就够了3
【网络安全渗透测试零基础入门必知必会】之如何搭建 DVWA 靶场保姆级教程(非常详细)零基础入门到精通,收藏这一篇就够了4
【网络安全渗透测试零基础入门必知必会】之Web漏洞-文件包含漏洞超详细全解(附实例)5
【网络安全渗透测试零基础入门必知必会】之文件上传漏洞修复方案6
****网络安全/渗透测试入门CSRF渗透与防御必知必会
【网络安全渗透测试零基础入门必知必会】之CSRF漏洞概述和原理(非常详细)零基础入门到精通, 收藏这一篇就够了1
【网络安全渗透测试零基础入门必知必会】之CSRF攻击的危害&分类(非常详细)零基础入门到精通, 收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之XSS与CSRF的区别(非常详细)零基础入门到精通, 收藏这一篇就够了3
【网络安全渗透测试零基础入门必知必会】之CSRF漏洞挖掘与自动化工具(非常详细)零基础入门到精通,收藏这一篇就够了4
【网络安全渗透测试零基础入门必知必会】之CSRF请求伪造&Referer同源&置空&配合XSS&Token值校验&复用删除5
****网络安全/渗透测试入门SSRF渗透与防御必知必会
【网络安全渗透测试零基础入门必知必会】之SSRF漏洞概述及原理(非常详细)零基础入门到精通,收藏这一篇就够了 1
【网络安全渗透测试零基础入门必知必会】之SSRF相关函数和协议(非常详细)零基础入门到精通,收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之SSRF漏洞原理攻击与防御(非常详细)零基础入门到精通,收藏这一篇就够了3**
**
****网络安全/渗透测试入门XXE渗透与防御必知必会
【网络安全渗透测试零基础入门必知必会】之XML外部实体注入(非常详细)零基础入门到精通,收藏这一篇就够了1
网络安全渗透测试零基础入门必知必会】之XXE的攻击与危害(非常详细)零基础入门到精通,收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之XXE漏洞漏洞及利用方法解析(非常详细)零基础入门到精通,收藏这一篇就够了3
【网络安全渗透测试零基础入门必知必会】之微信XXE安全漏洞处理(非常详细)零基础入门到精通,收藏这一篇就够了4
****网络安全/渗透测试入门远程代码执行渗透与防御必知必会
【网络安全渗透测试零基础入门必知必会】之远程代码执行原理介绍(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全零基础入门必知必会】之CVE-2021-4034漏洞原理解析(非常详细)零基础入门到精通,收藏这一篇就够了2
【网络安全零基础入门必知必会】之PHP远程命令执行与代码执行原理利用与常见绕过总结3
【网络安全零基础入门必知必会】之WEB安全渗透测试-pikachu&DVWA靶场搭建教程,零基础入门到精通,收藏这一篇就够了4
****网络安全/渗透测试入门反序列化渗透与防御必知必会
【网络安全零基础入门必知必会】之什么是PHP对象反序列化操作(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全零基础渗透测试入门必知必会】之php反序列化漏洞原理解析、如何防御此漏洞?如何利用此漏洞?2
【网络安全渗透测试零基础入门必知必会】之Java 反序列化漏洞(非常详细)零基础入门到精通,收藏这一篇就够了3
【网络安全渗透测试零基础入门必知必会】之Java反序列化漏洞及实例解析(非常详细)零基础入门到精通,收藏这一篇就够了4
【网络安全渗透测试零基础入门必知必会】之CTF题目解析Java代码审计中的反序列化漏洞,以及其他漏洞的组合利用5
网络安全/渗透测试**入门逻辑漏洞必知必会**
【网络安全渗透测试零基础入门必知必会】之一文带你0基础挖到逻辑漏洞(非常详细)零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门暴力猜解与防御必知必会
【网络安全渗透测试零基础入门必知必会】之密码安全概述(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全渗透测试零基础入门必知必会】之什么样的密码是不安全的?(非常详细)零基础入门到精通,收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之密码猜解思路(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之利用Python暴力破解邻居家WiFi密码、压缩包密码,收藏这一篇就够了4
【网络安全渗透测试零基础入门必知必会】之BurpSuite密码爆破实例演示,零基础入门到精通,收藏这一篇就够了5
【网络安全渗透测试零基础入门必知必会】之Hydra密码爆破工具使用教程图文教程,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之暴力破解medusa,零基础入门到精通,收藏这一篇就够了7
【网络安全渗透测试零基础入门必知必会】之Metasploit抓取密码,零基础入门到精通,收藏这一篇就够了8
****网络安全/渗透测试入门掌握Redis未授权访问漏洞必知必会
【网络安全渗透测试零基础入门必知必会】之Redis未授权访问漏洞,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Redis服务器被攻击后该如何安全加固,零基础入门到精通,收藏这一篇就够了**
**
网络安全/渗透测试入门掌握**ARP渗透与防御关必知必会**
【网络安全渗透测试零基础入门必知必会】之ARP攻击原理解析,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之ARP流量分析,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之ARP防御策略与实践指南,零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门掌握系统权限提升渗透与防御关****必知必会
【网络安全渗透测试零基础入门必知必会】之Windows提权常用命令,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Windows权限提升实战,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之linux 提权(非常详细)零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门掌握Dos与DDos渗透与防御相关****必知必会
【网络安全渗透测试零基础入门必知必会】之DoS与DDoS攻击原理(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Syn-Flood攻击原理解析(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之IP源地址欺骗与dos攻击,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之SNMP放大攻击原理及实战演示,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之NTP放大攻击原理,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之什么是CC攻击?CC攻击怎么防御?,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之如何防御DDOS的攻击?零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门掌握无线网络安全渗透与防御相关****必知必会
【网络安全渗透测试零基础入门必知必会】之Aircrack-ng详细使用安装教程,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之aircrack-ng破解wifi密码(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之WEB渗透近源攻击,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之无线渗透|Wi-Fi渗透思路,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之渗透WEP新思路Hirte原理解析,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之WPS的漏洞原理解析,零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门掌握木马免杀问题与防御********必知必会
【网络安全渗透测试零基础入门必知必会】之Metasploit – 木马生成原理和方法,零基础入门到精通,收藏这篇就够了
【网络安全渗透测试零基础入门必知必会】之MSF使用教程永恒之蓝漏洞扫描与利用,收藏这一篇就够了
网络安全/渗透测试入门掌握Vulnhub靶场实战********必知必会
【网络安全渗透测试零基础入门必知必会】之Vulnhub靶机Prime使用指南,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Vulnhub靶场Breach1.0解析,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之vulnhub靶场之DC-9,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Vulnhub靶机Kioptrix level-4 多种姿势渗透详解,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Vulnhub靶场PWNOS: 2.0 多种渗透方法,收藏这一篇就够了
网络安全/渗透测试入门掌握社会工程学必知必会
【网络安全渗透测试零基础入门必知必会】之什么是社会工程学?定义、类型、攻击技术,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之社会工程学之香农-韦弗模式,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之社工学smcr通信模型,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之社会工程学之社工步骤整理(附相应工具下载)收藏这一篇就够了
网络安全/渗透测试入门掌握********渗透测试工具使用******必知必会**
2024版最新Kali Linux操作系统安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之渗透测试工具大全之Nmap安装使用命令指南,零基础入门到精通,收藏这一篇就够了
2024版最新AWVS安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新burpsuite安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新owasp_zap安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新Sqlmap安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新Metasploit安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新Nessus下载安装激活使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新Wireshark安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
觉得有用的话,希望粉丝朋友帮大白点个**「分享」「收藏」「在看」「赞」**

黑客/网络安全学习包


资料目录
-
成长路线图&学习规划
-
配套视频教程
-
SRC&黑客文籍
-
护网行动资料
-
黑客必读书单
-
面试题合集
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

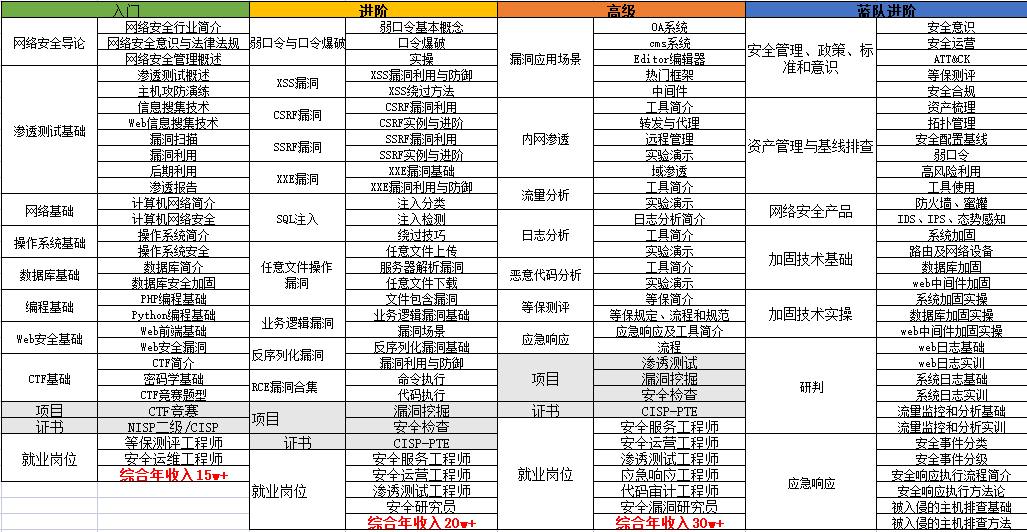
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
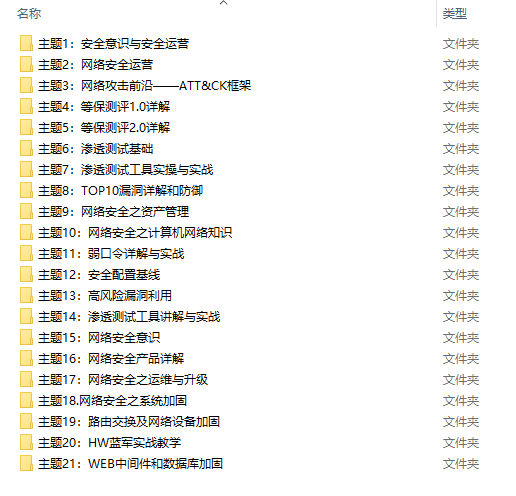
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.SRC&黑客文籍
大家最喜欢也是最关心的SRC技术文籍&黑客技术也有收录
SRC技术文籍:

黑客资料由于是敏感资源,这里不能直接展示哦!
4.护网行动资料
其中关于HW护网行动,也准备了对应的资料,这些内容可相当于比赛的金手指!
5.黑客必读书单
**

**
6.面试题合集
当你自学到这里,你就要开始思考找工作的事情了,而工作绕不开的就是真题和面试题。
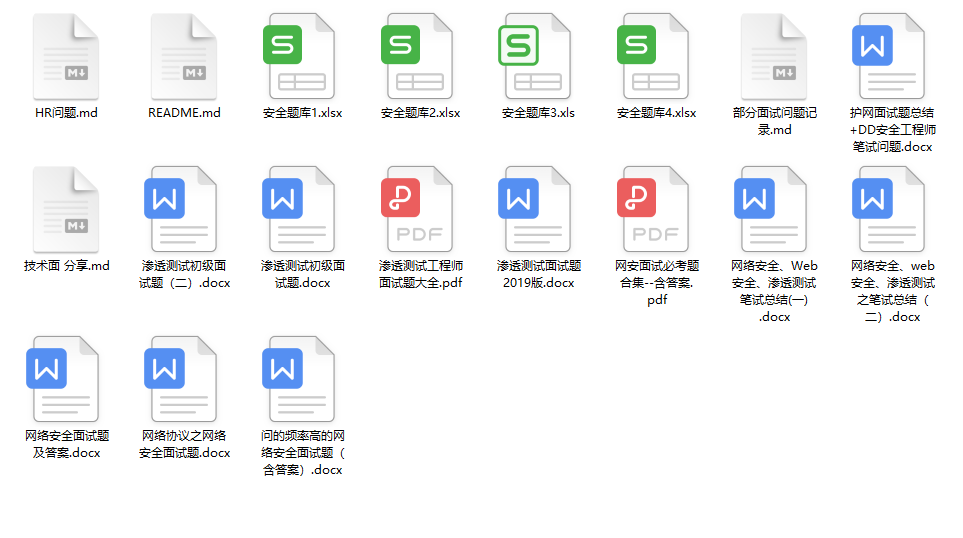
更多内容为防止和谐,可以扫描获取~

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
****************************优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享


















 4525
4525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









