



抛出,问题
最近项目碰到这么一个技术上的需求:
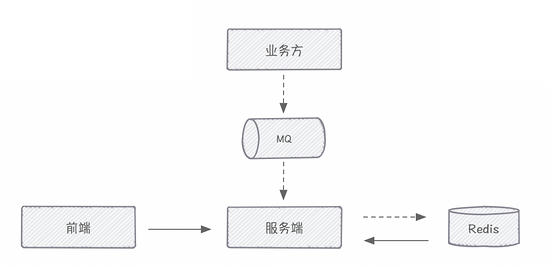
前端通过长轮询的机制(http long polling),获取服务端的消息数据。而服务端是需要订阅所有业务方的业务消息,再通知到给前端。
长轮询,其实简单来说,就是前端发起一个http请求,服务端把当前的请求 hang 住,直到超时或者有需要返回的内容,才return。 Apollo 配置中心就是使用这个机制实现配置的更新通知。
但有这么一种情况,假如服务端消费到消息,但此时前端与服务端的连接刚好断开了,那这个消息就没法通知到前端。
所以,我们得需要把服务端消费的消息保存下来,保证前端的每次发起长轮询的时候,都能拿到消息数据。
如果说,前端能直接订阅业务方的消息队列的话,那其实就没服务端什么关系了。当然,这是不允许的,前端不能连接咱们的消息中间件,并且业务方的消息数据也需要清洗处理后才能给到前端。
思考,方案
Apollo 的实现机制是,所有的配置都会写入数据库。每次请求过来,会去数据库获取是否有数据变更。
考虑到我们实际的业务场景,我们的业务消息其实时候时效性的,也就是说消息如果过期了,那其实也没用了。
要考虑轻量,我第一想到的就是 Redis Lists,利用其可以实现队列的特性,所以综合考虑最终采用 Redis 作为消息的存储模型。
优化,代码
Redis 的 Lists 数据结构,是简单的字符串链表,按插入顺序排序。可以在头部(Left)或者尾部(Right)添元素。
利用这个特性,我们可以实现队列(先进先出)的数据结构,搭配命令 rpush + lpop 或者 lpush + rpop 。
但是不管是 lpop 或是 rpop ,列表都只会弹出一个数据,没法达到我们的需求一次获取多个。
网上搜索了一下相关的解决方案,再结合官网的命令文档。
得出一种比较可行的方案: lrange + ltrim + pipeline
lrange 和 ltrim 是Redis Lists 的指令
lrange mylist 0 5
表示从队列头部(Left)开始取,下标为0,到下标为5的元素。如果是负数的话,表示队列尾部(Right)开始取。
ltrim mylist 0 5
ltrim 的含义是只保留指定范围的元素,上面的意思是,只保留列表下标为 0 - 5 的元素,其他的都会被删掉。
那如果要删掉前6条数据,就可能需要这么写:
ltrim mylist 5 -1
负数表示队列尾部(Right)开始取。
按实现来说, lrange + ltrim 就能实现从 List 获取多个元素的效果,为什么还需要用上 pipeline 呢?
其实这里有一个很显然的并发问题,这两个命令对于redis来说, 并不是原子操作 ,假如有其他线程在执行这两个命令的线程之间,删除了队列的一部分数据,那么第二个命令执行的时候,其实是list里面的数据已经是不对了。
而 Redis 的 pipeline 功能,可以解决我们上面说的这个问题。
大部分人可能对pipeline 比较陌生,因为平时业务上也很少用到。
先来看看 Redis Pipelining 的定义
A Request/Response server can be implemented so that it is able to process new requests even if the client hasn't already read the old responses. This way it is possible to send multiple commands to the server without waiting for the replies at all, and finally read the replies in a single step.
This is called pipelining, and is a technique widely in use for many decades. For instance many POP3 protocol implementations already support this feature, dramatically speeding up the process of downloading new emails from the server.
简单来说,它能够支持支持客户端一次发送多个命令,服务端接收到这些命令后,会统一按顺序处理,并且是在一个原子事务里。
显然,Pipelining 最明显的优势在于提高 client 与 server 的交互响应时间。将几个命令放在同一个请求中,和每个命令作为一个请求相比,效率是肯定提高的。
PS:这种方式,跟我为什么要获取多个list 数据的思路类似的。前端长轮询获取数据结果时,要返回多个数据。
话不多说,直接贴上示例代码:
@AutowiredRedisTemplate<String, Object> redisTemplate;public void run() throws Exception { System.out.println("start......"); String key = "key:list"; Integer number = 5; // 每次获取5个 List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() { @Override public Object doInRedis(RedisConnection connection) throws DataAccessException { connection.lRange(key.getBytes(StandardCharsets.UTF_8), 0, number - 1); connection.lTrim(key.getBytes(StandardCharsets.UTF_8), number, -1); return null; } }); System.out.println(Arrays.toString(objects.toArray())); System.out.println("end......");}
redisTemplate 提供了两种类型的方法:
- executePipelined(RedisCallback action)
- executePipelined(SessionCallback session)
这两者实现的功能都差不多,只不过 SessionCallback 比 RedisCallck 封装的更友好一下,后者的话更加底层,用法更加贴近与原生命令。

















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









