 深度学习:正则化与归一化详解
深度学习:正则化与归一化详解








|架构师带你玩转AI
在深度学习模型训练中,你是否也遇到过这样的困扰:“为什么我的模型在训练集上表现完美,但在测试集上却一塌糊涂?”又或者"为什么我的神经网络训练了几百个epoch还是不收敛?"
深度学习资料+AI学习路线可以上图扫码获取
资料包:一、 人工智能学习路线及大纲
二、计算机视觉OpenCV【视频+书籍】
三、AI基础+ 深度学习 + 机器学习 +NLP+ 机器视觉 教程
四、李飞飞+吴恩达+李宏毅合集
五、自动驾驶+知识图谱等资料
六、人工智能电子书合集【西瓜书、花书等】
七、各阶段AI论文攻略合集【论文带读/代码指导/本硕博/SCI/EI/中文核心】
这背后的原因在于,模型的成功不仅取决于网络架构的设计,更在于训练过程的精细调控。在这个调控过程中,有两个技术占据着举足轻重的地位:正则化与归一化。前者如同智慧的导师,防止模型过度拟合训练数据;后者如同稳定的基石,确保训练过程平稳高效。

一、正则化(Regularization)
正则化(Regularization)是什么?正则化是一种减少模型过拟合风险的技术。
一个训练过度的模型就像一个只会死记硬背的学生。它不仅掌握了知识的核心要点,还把教材中的每个标点符号、甚至是印刷错误都一并记住了。虽然这样的学生在期末考试(训练集)中能拿满分,但面对新的题目(测试集)时却往往束手无策,因为它缺乏真正的理解和泛化能力。
正则化的目的是通过引入额外的约束或惩罚项来限制模型的复杂度,从而提高模型在未知数据上的泛化能力。

如何实现正则化?正则化是通过重新定义损失函数来实现的。新的损失函数由两部分组成:原始的预测损失和一个正则化项。
正则化通过给损失函数"加料",在原有的预测误差基础上,再添加一个基于模型参数计算得出的惩罚项。这样一来,模型在优化过程中不仅要考虑预测准确性,还要兼顾参数的简洁性。

L1正则化和L2正则化是最主流的两种正则化技术,前者通过引入权重绝对值的约束来产生稀疏权重(许多权重为零),后者则通过权重平方和的惩罚来控制参数规模(保持权重值较小)。无论选择哪种方法,训练过程都遵循同样的原理——通过优化算法不断调整参数以最小化新的损失函数L_new,从而达到正则化的效果。
1. L1正则化(Lasso)
L1正则化在损失函数L中添加L1正则项,得到新的损失函数L_new = L + λ∑|w_i|,其中λ是正则化系数,w_i是模型参数。
-
方法:在损失函数中添加模型参数绝对值之和作为惩罚项。
-
特点:倾向于产生稀疏权重矩阵,即部分特征权重为零,有助于特征选择。
def l1_regularization(model, lambda_l1):
l1_loss = 0
for param in model.parameters():
l1_loss += torch.norm(param, p=1) # 绝对值之和
return lambda_l1 * l1_loss
# 训练时修改loss计算
loss = criterion(outputs, labels) + l1_regularization(model, 0.001)
2. L2正则化(Ridge)
L2正则化则在损失函数L中添加L2正则项,得到新的损失函数L_new = L + λ∑w_i^2,其中λ是正则化系数,w_i是模型参数。
-
方法:在损失函数中添加模型参数平方和作为惩罚项。
-
特点:倾向于使权重值均匀分布且较小,有助于防止模型过于复杂,减少过拟合。
def l2_regularization(model, lambda_l2):
l2_reg = torch.tensor(0.0)
for param in model.parameters():
l2_reg += torch.norm(param, p=2) # 平方和
return lambda_l2 * l2_reg
# 在训练循环中手动添加
loss = criterion(outputs, labels) + l2_regularization(model, 0.001)
二、归一化(Normalization)
归一化(Normalization)是什么?归一化是一种数据预处理技术,目的是将数据分布调整为特定尺度(如均值为0,标准差为1),旨在解决数据分布不一致的问题。
当面对来自不同量纲的特征数据时,归一化能够将它们统一转换到相同的数值范围内,比如标准正态分布(均值0,标准差1)。通过这种统一化处理,可以消除原始数据中不同特征维度间的尺度差异,让神经网络能够更均衡地学习各个特征的重要性。
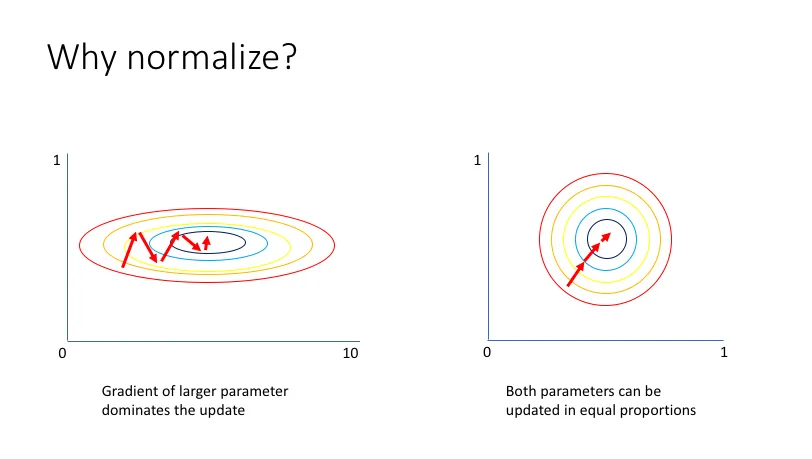
归一化的过程是什么?归一化是通过确定数据的取值范围,应用相应的归一化公式将数据转换到新的稳定尺度,从而得到更加适合后续分析和处理的数据集。
-
确定归一化范围:找出数据的最大值和最小值,或根据需要选择均值和标准差等统计量。
-
应用归一化公式:使用相应公式将数据转换到新尺度,如线性归一化(映射到[0,1]或[-1,1])或Z-score标准化(转换为标准正态分布)。
-
获得归一化数据:经过公式处理后,得到数值更稳定、便于后续分析的标准化数据集。

常用的归一化有哪些?常用的归一化主要包括批量归一化(BN)、层归一化(LN)、实例归一化(IN)和组归一化(GN)等,它们各有其独特的应用场景和优势,选择哪种归一化方法通常取决于具体任务和数据的特点。
1. 批量归一化(Batch Normalization, BN)-- 图像处理首选
-
方法:在神经网络的每一层中,对每个mini-batch的输入进行归一化处理。通过减去均值,再除以标准差,将输入数据转化为均值为0,标准差为1的分布。
-
优点:加速网络训练、防止梯度问题、优化正则化效果、降低学习率要求,并有助于缓解过拟合,从而显著提升神经网络的性能和稳定性。
-
应用场景:适用于大多数神经网络场景,特别是在训练深层网络时。
# 卷积网络标准配置
nn.Sequential(
nn.Conv2d(3, 64, 3),
nn.BatchNorm2d(64), # 批量归一化
nn.ReLU()
)
2. 层归一化(Layer Normalization, LN)-- Transformer标配
-
方法:在神经网络的每一层中,对每个样本的所有特征维度进行归一化处理。通过减去均值,再除以标准差,将每个样本的特征维度转化为均值为0,标准差为1的分布。
-
优点:在训练样本较小、样本间相互影响较大的情况下更稳定。
-
应用场景:如循环神经网络(RNN)、Transformer等场景。
# Transformer Block结构
class TransformerLayer(nn.Module):
def __init__(self):
super().__init__()
self.ln1 = nn.LayerNorm(512)
self.ln2 = nn.LayerNorm(512)
3. 实例归一化(Instance Normalization, IN)-- 风格迁移神器
-
方法:对每个样本的特征维度进行归一化。通过减去均值,再除以标准差,将每个样本的特征维度转化为均值为0,标准差为1的分布。
-
优点:更适用于图像生成等任务中,每个样本的特征维度独立于其他样本的情况。
-
应用场景:图像生成任务等。
# 风格迁移网络片段
style_transfer = nn.Sequential(
nn.Conv2d(3, 128, 3),
nn.InstanceNorm2d(128), # 单样本单通道归一化
nn.AdaptiveAvgPool2d(1)
)
4. 组归一化(Group Normalization, GN)-- 小批量救星
-
方法:在神经网络的每一层中,将特征分成若干组,对每个组的特征进行归一化处理。通过减去均值,再除以标准差,将每个组的特征维度转化为均值为0,标准差为1的分布。
-
优点:适用于样本较小、样本间相互影响较大,但又不需要对整个mini-batch进行归一化的情况。
-
应用场景:图像分割任务等。
# 医学图像分割网络
nn.Sequential(
nn.Conv2d(64, 128, 3),
nn.GroupNorm(4, 128), # 128通道分为4组
nn.LeakyReLU()
)


















 5534
5534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









