







深度学习是机器学习的一个子集,通过构建多层神经网络模拟人脑的抽象和推理能力,特别擅长处理图像、语音、文本等非结构化数据。其核心优势在于自动特征提取能力,相比传统机器学习依赖人工设计特征,深度学习通过多层非线性变换自动发现数据中的隐藏规律。对于零基础学习者,建议遵循以下系统化学习路径:
一、基础能力构建(1-2个月)
1、数学基础
深度学习需要掌握线性代数(矩阵运算)、概率统计(贝叶斯理论)、微积分(梯度计算)三大核心领域。例如反向传播算法依赖链式法则求导,卷积神经网络(CNN)的核心是矩阵卷积运算。推荐通过《Deep Learning》书中的数学章节或MIT公开课《Mathematics for Computer Science》补齐基础。
2、编程与数据处理
Python是首选语言,需熟练掌握NumPy(矩阵操作)、Pandas(数据清洗)、Matplotlib(可视化)等库。例如使用NumPy实现向量点积:
import numpy as np
a = np.array([1,2,3])
b = np.array([4,5,6])
print(np.dot(a,b)) # 输出32
SQL用于大规模数据提取,可通过LeetCode或HackerRank刷题练习。
3、机器学习基础
理解监督学习(分类/回归)与无监督学习(聚类/降维)的区别。建议完成Andrew Ng的《Machine Learning》课程,重点掌握逻辑回归、决策树、SVM等基础算法。 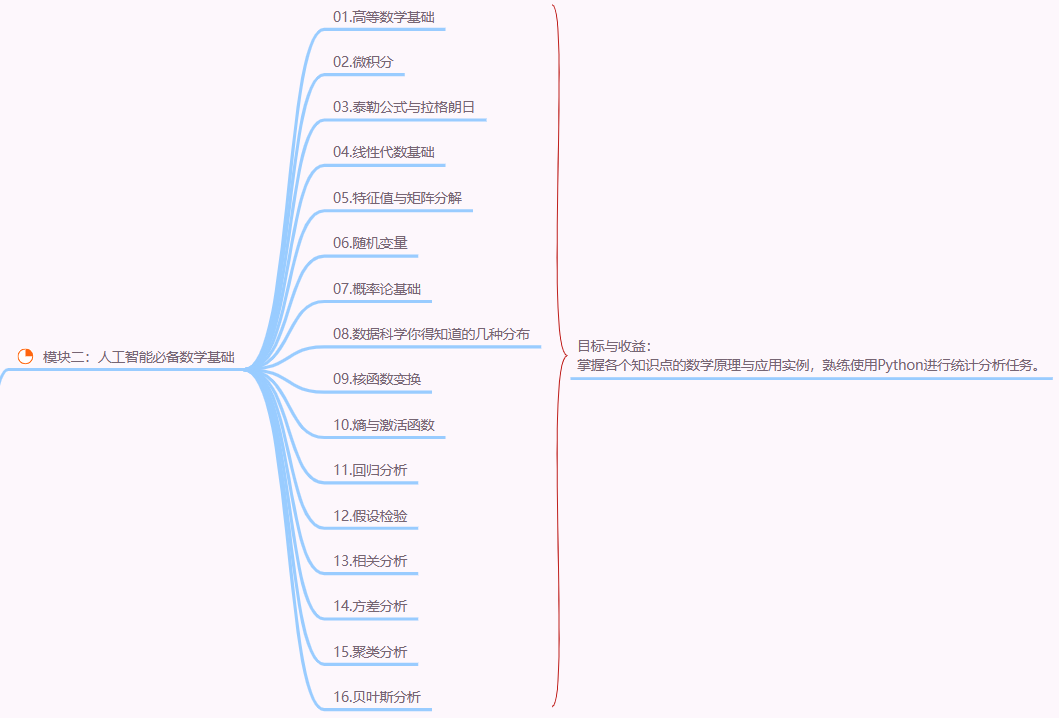
二、深度学习理论进阶(1个月)
1、神经网络基础
结构原理:输入层-隐藏层-输出层的权重连接,激活函数(如ReLU解决梯度消失)的作用。训练机制:损失函数(交叉熵、均方误差)、优化器(SGD、Adam)的选择,正则化(Dropout、L2)防止过拟合。例如使用PyTorch实现全连接网络:
import torch.nn as nn
model = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
2、主流模型架构
CNN:通过卷积核提取空间特征,适用于图像处理。经典案例:ResNet在ImageNet的Top-5错误率仅3.57%。
RNN/LSTM:处理序列数据,如文本生成。LSTM通过门控机制解决长程依赖问题。
Transformer:基于自注意力机制,在NLP领域超越RNN,如BERT的预训练模型。 
三、工具与实战(2-3个月)
1、框架选择
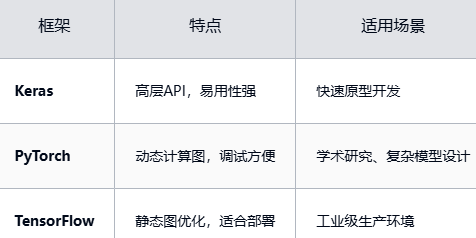
新手建议从PyTorch开始,因其代码可读性强且社区资源丰富。例如用PyTorch实现MNIST分类仅需20行代码。 
2、项目实战路径
入门级:Kaggle上的Titanic生存预测(结构化数据)、MNIST手写识别(图像)
进阶级:CIFAR-10图像分类(CNN)、IMDB情感分析(RNN)
挑战级:复现经典论文如AlexNet、Transformer,或参与天池竞赛
3、学习资源整合
四、持续提升策略
论文精读:每周精读1篇顶会论文(如NeurIPS、ICML),使用Arxiv-Sanity跟踪前沿。
工程优化:学习模型压缩(量化、剪枝)、分布式训练(Horovod)等工业级技术。
社区参与:在GitHub贡献代码、参加Meetup技术分享,构建个人技术影响力。
关键提示:避免陷入“调参陷阱”,初期应使用预训练模型(如VGG16)快速验证思路,再逐步深入原理。保持“理论-代码-调优”的迭代循环,才能实现从入门到精通的跨越。

















 36万+
36万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









