




📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、(架构篇)、《解密程序员的思维密码——沟通、演讲、思考的实践》作者、清华大学出版社签约作家、Java领域优质创作者、优快云博客专家、阿里云专家博主、51CTO专家博主、产品软文专业写手、技术文章评审老师、技术类问卷调查设计师、幕后大佬社区创始人、开源项目贡献者。
📘拥有多年一线研发和团队管理经验,研究过主流框架的底层源码(Spring、SpringBoot、SpringMVC、SpringCloud、Mybatis、Dubbo、Zookeeper),消息中间件底层架构原理(RabbitMQ、RocketMQ、Kafka)、Redis缓存、MySQL关系型数据库、 ElasticSearch全文搜索、MongoDB非关系型数据库、Apache ShardingSphere分库分表读写分离、设计模式、领域驱动DDD、Kubernetes容器编排等。
📙不定期分享高并发、高可用、高性能、微服务、分布式、海量数据、性能调优、云原生、项目管理、产品思维、技术选型、架构设计、求职面试、副业思维、个人成长等内容。

💡在这个美好的时刻,笔者不再啰嗦废话,现在毫不拖延地进入文章所要讨论的主题。接下来,我将为大家呈现正文内容。

🌟 Redis的Java客户端:SpringDataRedis
🍊 特点
SpringDataRedis是一个用于简化Redis操作的Java客户端,它提供了以下特点:
| 特点 | 描述 |
|---|---|
| 客户端整合 | 支持Lettuce和Jedis两种Redis客户端,方便用户根据需求选择,Lettuce提供了异步和响应式编程的支持,而Jedis则提供了同步API,两者各有优势。 |
| 统一API | 提供RedisTemplate统一API,简化Redis操作,使得开发者无需关心底层的Redis客户端实现细节,只需关注业务逻辑。 |
| 发布订阅 | 支持Redis的发布订阅模型,实现消息传递,可以用于构建消息队列、事件监听等应用场景。 |
| 哨兵和集群 | 支持Redis哨兵和Redis集群,提高系统可用性和扩展性,哨兵可以监控Redis实例的健康状态,并在需要时进行故障转移;集群则可以将数据分散存储在多个节点上,提高数据存储的可靠性和性能。 |
| 响应式编程 | 支持基于Lettuce的响应式编程,提高并发处理能力,可以更好地应对高并发场景。 |
| 数据序列化 | 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化,方便用户根据需求选择合适的序列化方式。 |
| JDKCollection实现 | 支持基于Redis的JDKCollection实现,方便使用,例如RedisSet、RedisList等,可以直接在Redis中操作这些数据结构,无需进行额外的数据转换。 |
🍊 RedisTemplate使用的入门案例
🎉 1. 创建一个SpringBoot工程
首先,创建一个SpringBoot工程,用于演示SpringDataRedis的使用。
🎉 2. 引入依赖
在SpringBoot工程的pom.xml文件中,引入以下依赖:
<!--redis依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool依赖-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--testng依赖-->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>7.1.0</version>
</dependency>
🎉 3. 编写连接配置文件application.yml
在src/main/resources/application.yml文件中,配置Redis连接信息:
spring:
redis:
host: 192.168.80.132
port: 6379
password: root
lettuce:
pool:
max-active: 8 #最大连接数
max-idle: 8 #最大空闲连接
max-wait: 100 #连接等待时间
min-idle: 0 #最小空闲连接
🎉 4. 在测试类中进行测试
创建一个测试类RedisSpringdataApplicationTests,注入RedisTemplate并测试字符串操作:
package com.lrc;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class RedisSpringdataApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
//插入一条string类型的数据
redisTemplate.opsForValue().set("name", "李四");
//读取一条string类型数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name=" + name);
}
}
🎉 5. 运行得到结果
运行测试类,查看控制台输出结果,验证RedisTemplate是否正常工作。
🍊 RedisTemplate的序列化机制
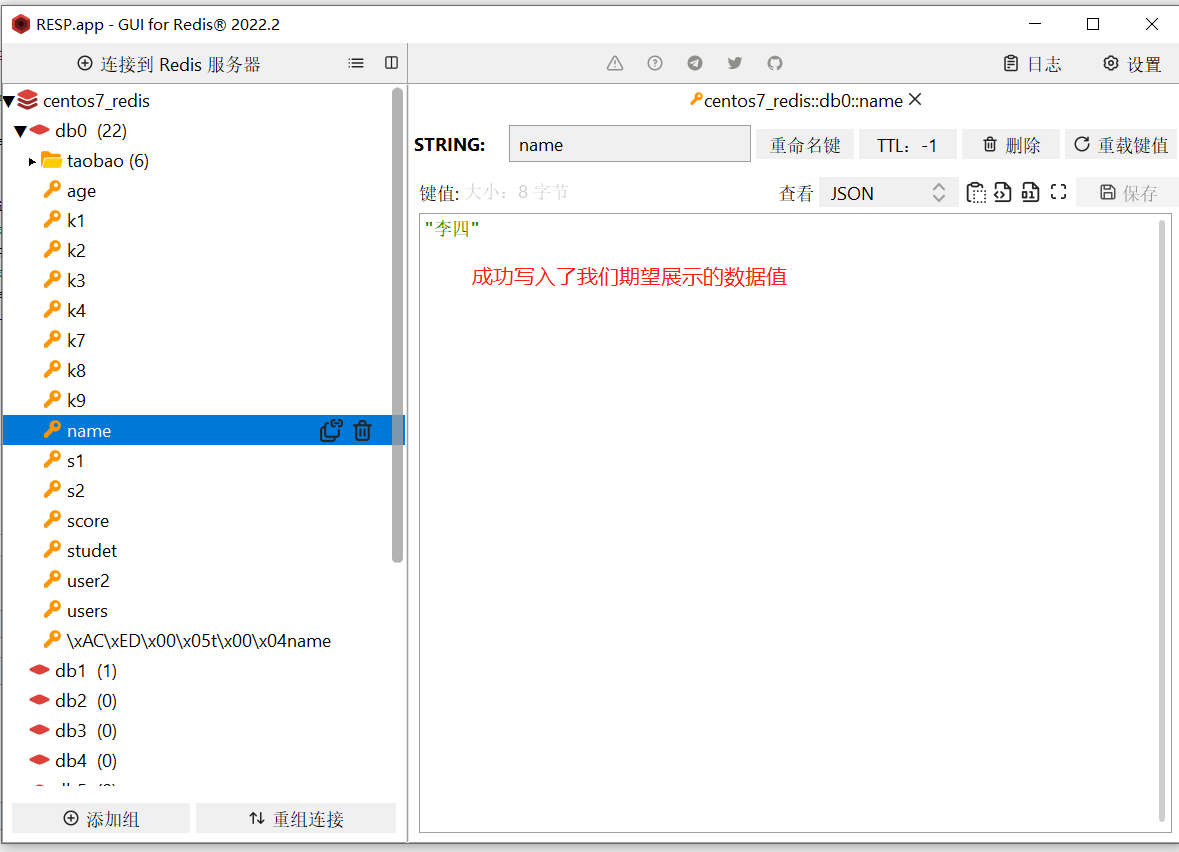
🎉 引入
在入门案例中,我们向Redis插入了一条{"name":"李四"}的数据,但在Redis可视化界面看到的数据并不是我们预期的结果。这是因为RedisTemplate默认采用JDK序列化,将对象序列化为字节形式存储。
🎉 自定义序列化步骤
- 引入Jackson依赖,处理序列化操作:
<!--Jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
- 在
com.lrc.redis.config包下新建一个RedisConfig配置类:
package com.lrc.redis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
//创建一个redisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
//设置连接工厂
template.setConnectionFactory(redisConnectionFactory);
//设置序列化工具
GenericJackson2JsonRedisSerializer jonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//key和hashkey采用String序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
//value和hashValue采用JSON序列化
template.setValueSerializer(RedisSerializer.json());
template.setHashValueSerializer(RedisSerializer.json());
return template;
}
}
- 测试自定义序列化机制后的结果:
package com.lrc;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class RedisSpringdataApplicationTests {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Test
void testString() {
//插入一条string类型的数据
redisTemplate.opsForValue().set("name", "李四");
//读取一条string类型数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name=" + name);
}
}
🎉 验证向Redis写入对象的结果
- 在
com.lrc.redis.pojo包下新建一个实体类User:
package com.lrc.redis.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private String name;
private Integer age;
}
- 测试下向Redis插入一个对象数据的结果:
@Test
void testAddUser() {
//写入数据
redisTemplate.opsForValue().set("user:100", new User("王五", 21));
//读取数据
User user = (User) redisTemplate.opsForValue().get("user:100");
System.out.println("user=" + user);
}
- 执行测试:

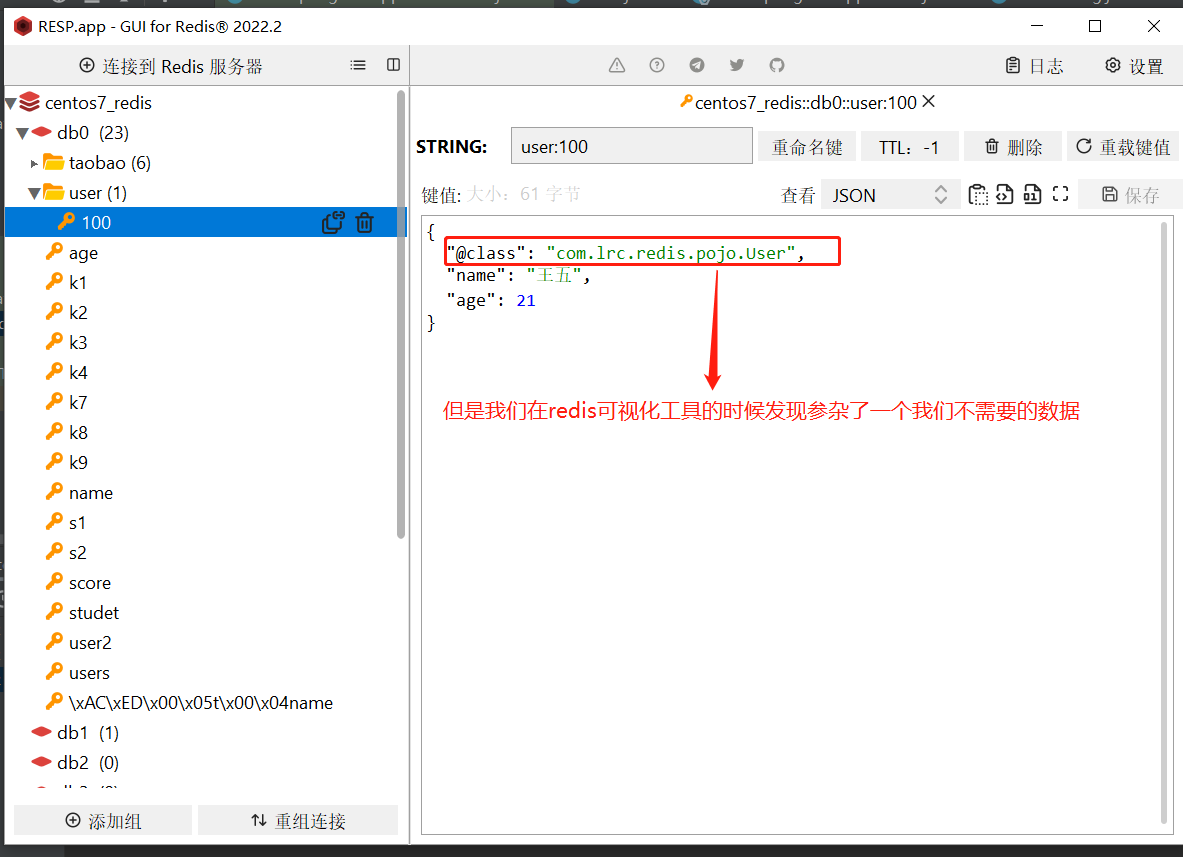
🎉 出现这种结果的原因
- RedisTemplate存在一个自动反序列机制,那么它就需要存起反序列化的对象才能知道对哪个对象进行反序列化,显然这种结果往往我们也不想要,因为会有很大的内存开销。
🎉 优化方案
- Spring默认还提供了一个StringRedisTemplate类,它的key和value的序列化方式默认就是String方式。省去了我们自定义RedisTemplate的过程。
🎉 使用步骤
- 测试类中注入StringRedisTemplate:
@Autowired
private StringRedisTemplate stringRedisTemplate;
- new一个序列化工具:
// JSON工具
private static final ObjectMapper mapper = new ObjectMapper();
- 手动编写序列化操作:
@Test
void testAddUserMyself() throws JsonProcessingException {
//创建对象
User user = new User("Tom", 29);
//手动序列化
String json = mapper.writeValueAsString(user);
//写入数据
stringRedisTemplate.opsForValue().set("user:300", json);
//读取数据
String s = stringRedisTemplate.opsForValue().get("user:300");
//进行反序列化
User user1 = mapper.readValue(s, User.class);
System.out.println("user1=" + user1);
}
- 执行测试:
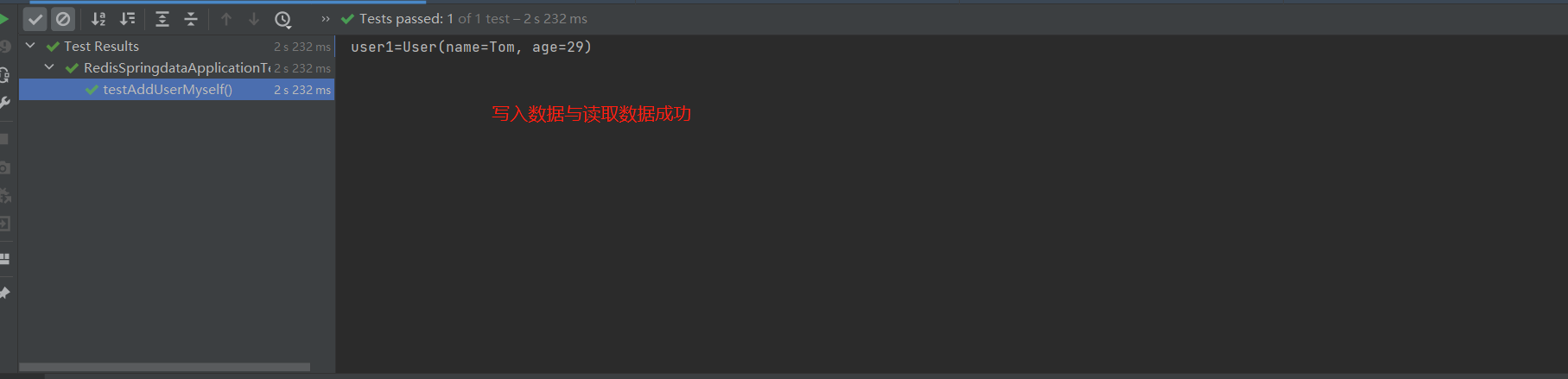
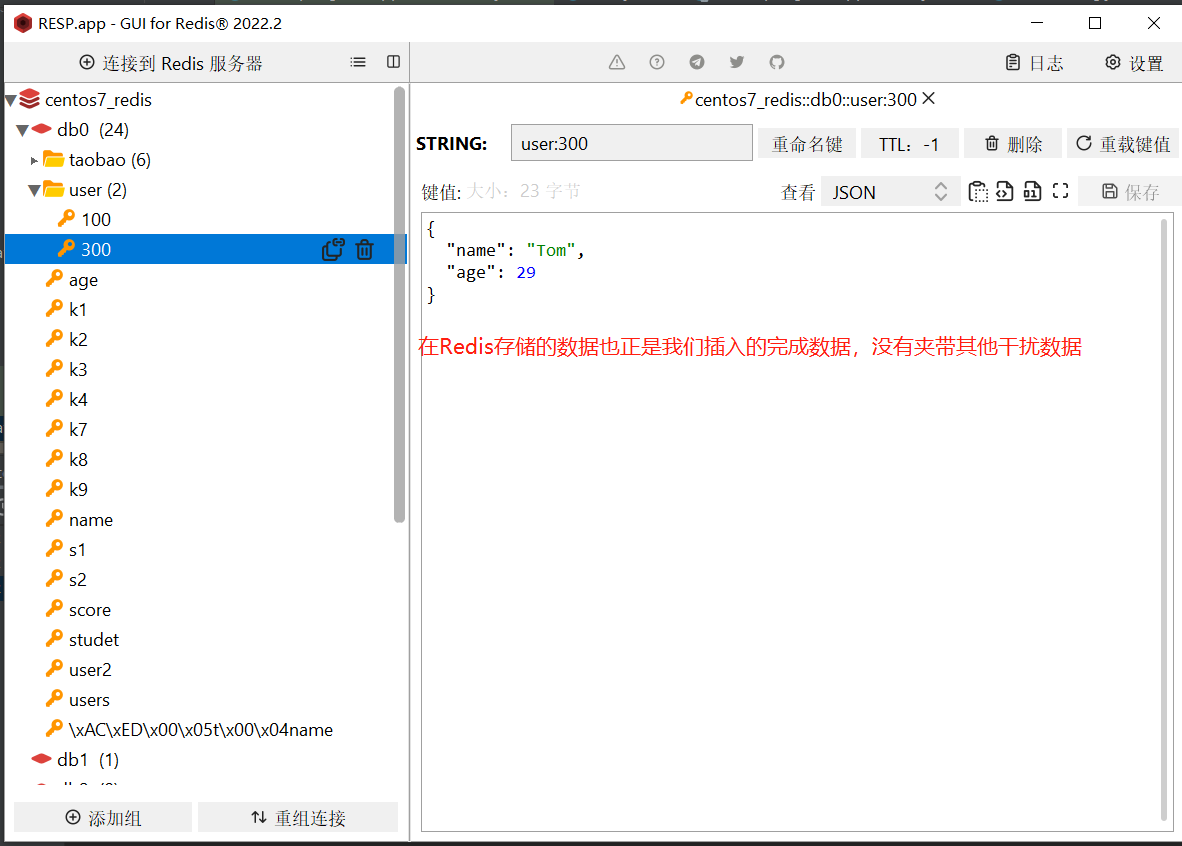
🎉 使用看来
- 还是使用StringRedisTemplate比较符合我们的实际应用场景。
🍊 使用StringRedisTemplate操作其他数据类型练习
🎉 1. 操作Hash类型
📝 1.1 使用put方法逐条存数据
@Test
void testHash() {
//存数据
stringRedisTemplate.opsForHash().put("user:400", "name", "hashName");
stringRedisTemplate.opsForHash().put("user:400", "age", "hashAge");
stringRedisTemplate.opsForHash().put("user:400", "handsome", "hashYes");
//取数据
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:400");
System.out.println("entries=" + entries);
}
📝 1.2 使用putAll方法批量存数据
@Test
void testHash02() {
//准备一个HashMap数据
HashMap<Object, Object> map = new HashMap<>();
map.put("name", "lrc");
map.put("age", "18");
map.put("description", "很帅气的小伙子");
//存入上述hashMap数据
stringRedisTemplate.opsForHash().putAll("user:500", map);
//取数据
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:500");
System.out.println("entries=" + entries);
}
🎉 2. 操作List类型数据
📝 2.1 逐条插入数据leftPush或者rightPush
@Test
void testList() {
//存数据
stringRedisTemplate.opsForList().leftPush("aKey", "aValue");
stringRedisTemplate.opsForList().leftPush("bKey", "bValue");
//取数据
String aKey = stringRedisTemplate.opsForList().leftPop("aKey");
String bKey = stringRedisTemplate.opsForList().leftPop("bKey");
System.out.println("akey=" + aKey + "\n" + "bKey=" + bKey);
}
📝 2.2 一次插入一个ArrayList集合数据
@Test
void testList02() {
//创建一个ArrayList
ArrayList list = new ArrayList();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("赵六");
//存数据
stringRedisTemplate.opsForList().leftPushAll("student", list);
//读数据
for (int i = 0; i < list.size(); i++) {
String student = stringRedisTemplate.opsForList().leftPop("student");
System.out.println("student=" + student);
}
}
🎉 3. 操作Set类型
@Test
void testSet() {
stringRedisTemplate.opsForSet().add("setData", "data1", "data2", "data3", "data4");
Set<String> setData = stringRedisTemplate.opsForSet().members("setData");
System.out.println("setData=" + setData);
}
🎉 4. 操作SortedSet类型
@Test
void testSortSet() {
//存数据
stringRedisTemplate.opsForZSet().add("key", "value1", 80);
stringRedisTemplate.opsForZSet().add("key", "value2", 90);
stringRedisTemplate.opsForZSet().add("key", "value3", 95);
stringRedisTemplate.opsForZSet().add("key", "value4", 98);
//取数据
Set<String> key = stringRedisTemplate.opsForZSet().range("key", 0, 2);
System.out.println("key=" + key);
})
博主分享
📥博主的人生感悟和目标

📙经过多年在优快云创作上千篇文章的经验积累,我已经拥有了不错的写作技巧。同时,我还与清华大学出版社签下了四本书籍的合约,并将陆续出版。
- 《Java项目实战—深入理解大型互联网企业通用技术》基础篇的购书链接:https://item.jd.com/14152451.html
- 《Java项目实战—深入理解大型互联网企业通用技术》基础篇繁体字的购书链接:http://product.dangdang.com/11821397208.html
- 《Java项目实战—深入理解大型互联网企业通用技术》进阶篇的购书链接:https://item.jd.com/14616418.html
- 《Java项目实战—深入理解大型互联网企业通用技术》架构篇待上架
- 《解密程序员的思维密码--沟通、演讲、思考的实践》购书链接:https://item.jd.com/15096040.html
面试备战资料
八股文备战
| 场景 | 描述 | 链接 |
|---|---|---|
| 时间充裕(25万字) | Java知识点大全(高频面试题) | Java知识点大全 |
| 时间紧急(15万字) | Java高级开发高频面试题 | Java高级开发高频面试题 |
理论知识专题(图文并茂,字数过万)
| 技术栈 | 链接 |
|---|---|
| RocketMQ | RocketMQ详解 |
| Kafka | Kafka详解 |
| RabbitMQ | RabbitMQ详解 |
| MongoDB | MongoDB详解 |
| ElasticSearch | ElasticSearch详解 |
| Zookeeper | Zookeeper详解 |
| Redis | Redis详解 |
| MySQL | MySQL详解 |
| JVM | JVM详解 |
集群部署(图文并茂,字数过万)
| 技术栈 | 部署架构 | 链接 |
|---|---|---|
| MySQL | 使用Docker-Compose部署MySQL一主二从半同步复制高可用MHA集群 | Docker-Compose部署教程 |
| Redis | 三主三从集群(三种方式部署/18个节点的Redis Cluster模式) | 三种部署方式教程 |
| RocketMQ | DLedger高可用集群(9节点) | 部署指南 |
| Nacos+Nginx | 集群+负载均衡(9节点) | Docker部署方案 |
| Kubernetes | 容器编排安装 | 最全安装教程 |
开源项目分享
| 项目名称 | 链接地址 |
|---|---|
| 高并发红包雨项目 | https://gitee.com/java_wxid/red-packet-rain |
| 微服务技术集成demo项目 | https://gitee.com/java_wxid/java_wxid |
管理经验
【公司管理与研发流程优化】针对研发流程、需求管理、沟通协作、文档建设、绩效考核等问题的综合解决方案:https://download.youkuaiyun.com/download/java_wxid/91148718
希望各位读者朋友能够多多支持!
现在时代变了,信息爆炸,酒香也怕巷子深,博主真的需要大家的帮助才能在这片海洋中继续发光发热,所以,赶紧动动你的小手,点波关注❤️,点波赞👍,点波收藏⭐,甚至点波评论✍️,都是对博主最好的支持和鼓励!
- 💂 博客主页: Java程序员廖志伟
- 👉 开源项目:Java程序员廖志伟
- 🌥 哔哩哔哩:Java程序员廖志伟
- 🎏 个人社区:Java程序员廖志伟
- 🔖 个人微信号:
SeniorRD
🔔如果您需要转载或者搬运这篇文章的话,非常欢迎您私信我哦~


















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









