




 本文深入解析Java集合框架,包括Collection和Map接口,以及List、Set、Map类的常见实现如ArrayList、LinkedList、HashSet、TreeSet、HashMap、LinkedHashMap和TreeMap的特性与应用场景。
本文深入解析Java集合框架,包括Collection和Map接口,以及List、Set、Map类的常见实现如ArrayList、LinkedList、HashSet、TreeSet、HashMap、LinkedHashMap和TreeMap的特性与应用场景。
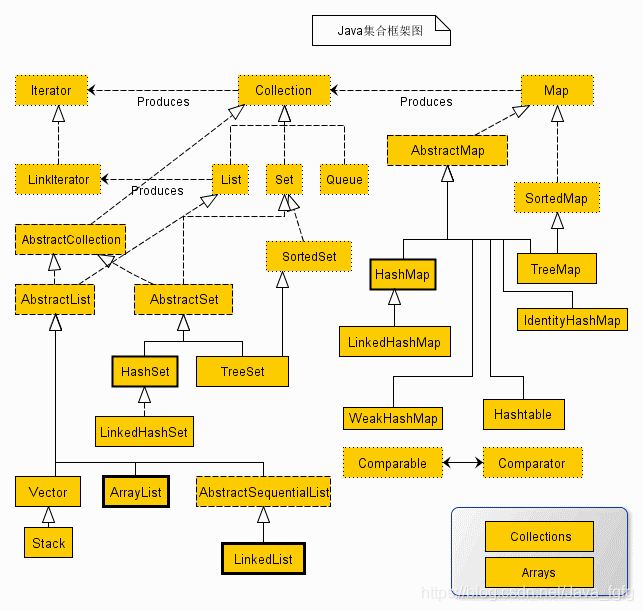
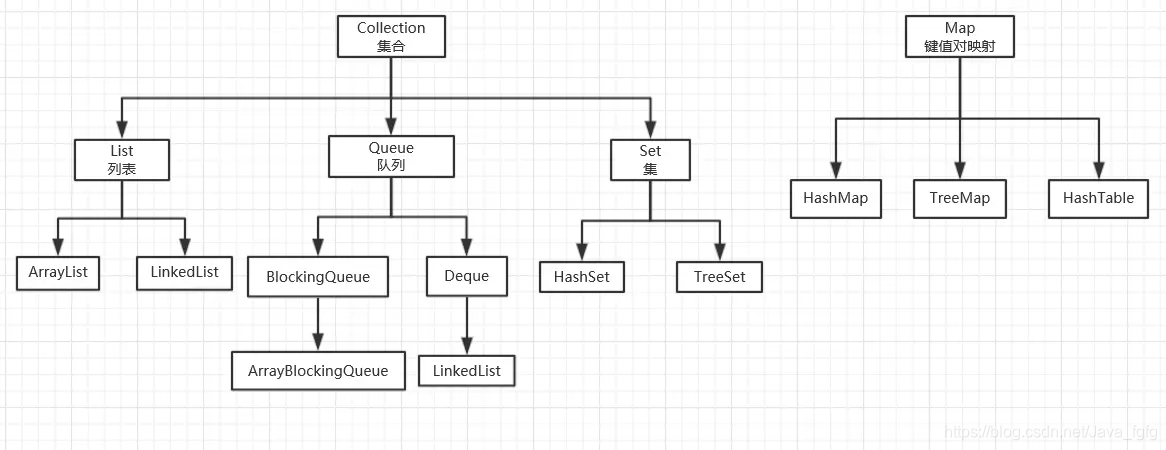
Java提供的众多集合类由两大接口衍生而来:Collection接口和Map接口
Collection接口
Collection接口定义了一个包含一批对象的集合。接口的主要方法包括:
- size() - 集合内的对象数量
- add(E)/addAll(Collection) - 向集合内添加单个/批量对象
- remove(Object)/removeAll(Collection) - 从集合内删除单个/批量对象
- contains(Object)/containsAll(Collection) - 判断集合中是否存在某个/某些对象
- toArray() - 返回包含集合内所有对象的数组
等
Map接口
Map接口在Collection的基础上,为其中的每个对象指定了一个key,并使用Entry保存每个key-value对,以实现通过key快速定位到对象(value)。Map接口的主要方法包括:
- size() - 集合内的对象数量
- put(K,V)/putAll(Map) - 向Map内添加单个/批量对象
- get(K) - 返回Key对应的对象
- remove(K) - 删除Key对应的对象
- keySet() - 返回包含Map中所有key的Set
- values() - 返回包含Map中所有value的Collection
- entrySet() - 返回包含Map中所有key-value对的EntrySet
- containsKey(K)/containsValue(V) - 判断Map中是否存在指定key/value
等
在了解了Collection和Map两大接口之后,我们再来看一下这两个接口衍生出来的常用集合类:
1. List类集合
在Collection中,List集合是有序的,Developer可对其中每个元素的插入位置进行精确地控制,可以通过索引来访问元素,遍历元素。
在List集合中,我们常用到ArrayList和LinkedList这两个类。
List选择
| 底层实现 | 特性 | 适用场合 | |
|---|---|---|---|
| Vector/Stack | 版本较低,避免使用 | ||
| ArrayList | 数组 | 访问快速 | 默认选择;需要执行大量的随机访问 |
| LinkedList | 双向链表 | 插入和删除代价低廉 | 要经常在表中插入或删除元素 |
1.1、ArrayList:
ArrayList是Java集合框架中使用最多的一个类,是一个数组队列,线程不安全集合。
ArrayList基于数组来实现集合的功能,其内部维护了一个可变长的对象数组,集合内所有对象存储于这个数组中,并实现该数组长度的动态伸缩
它继承于AbstractList,实现了List, RandomAccess, Cloneable, Serializable接口。
- ArrayList实现List,得到了List集合框架基础功能;
- ArrayList实现RandomAccess,获得了快速随机访问存储元素的功能,RandomAccess是一个标记接口,没有任何方法;
- ArrayList实现Cloneable,得到了clone()方法,可以实现克隆功能;
- ArrayList实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
它具有如下特点:
- 容量不固定,随着容量的增加而动态扩容(阈值基本不会达到)
- 有序集合(插入的顺序==输出的顺序)
- 插入的元素可以为null
- 增删改查效率更高(相对于LinkedList来说)
- 线程不安全
ArrayList基本操作
public class ArrayListTest {
public static void main(String[] agrs){
//创建ArrayList集合:
List<String> list = new ArrayList<String>();
System.out.println("ArrayList集合初始化容量:"+list.size());
//添加功能:
list.add("Hello");
list.add("world");
list.add(2,"!");
System.out.println("ArrayList当前容量:"+list.size());
//修改功能:
list.set(0,"my");
list.set(1,"name");
System.out.println("ArrayList当前内容:"+list.toString());
//获取功能:
String element = list.get(0);
System.out.println(element);
//迭代器遍历集合:(ArrayList实际的跌倒器是Itr对象)
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String next = iterator.next();
System.out.println(next);
}
//for循环迭代集合:
for(String str:list){
System.out.println(str);
}
//判断功能:
boolean isEmpty = list.isEmpty();
boolean isContain = list.contains("my");
//长度功能:
int size = list.size();
//把集合转换成数组:
String[] strArray = list.toArray(new String[]{});
//删除功能:
list.remove(0);
list.remove("world");
list.clear();
System.out.println("ArrayList当前容量:"+list.size());
}
}
1.2、LinkedList:
LinkedList是一个双向链表,基于链表来实现集合的功能,每一个节点都拥有指向前后节点的引用。相比于ArrayList来说,LinkedList的随机访问效率更低。
它继承AbstractSequentialList,实现了List, Deque, Cloneable, Serializable接口。
- LinkedList实现List,得到了List集合框架基础功能;
- LinkedList实现Deque,Deque 是一个双向队列,也就是既可以先入先出,又可以先入后出,说简单些就是既可以在头部添加元素,也可以在尾部添加元素;
- LinkedList实现Cloneable,得到了clone()方法,可以实现克隆功能;
- LinkedList实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
LinkedList基本操作
public class LinkedListTest {
public static void main(String[] agrs){
List<String> linkedList = new LinkedList<String>();
System.out.println("LinkedList初始容量:"+linkedList.size());
//添加功能:
linkedList.add("my");
linkedList.add("name");
linkedList.add("is");
linkedList.add("jiaboyan");
System.out.println("LinkedList当前容量:"+ linkedList.size());
//修改功能:
linkedList.set(0,"hello");
linkedList.set(1,"world");
System.out.println("LinkedList当前内容:"+ linkedList.toString());
//获取功能:
String element = linkedList.get(0);
System.out.println(element);
//遍历集合:(LinkedList实际的跌倒器是ListItr对象)
Iterator<String> iterator = linkedList.iterator();
while(iterator.hasNext()){
String next = iterator.next();
System.out.println(next);
}
//for循环迭代集合:
for(String str:linkedList){
System.out.println(str);
}
//判断功能:
boolean isEmpty = linkedList.isEmpty();
boolean isContains = linkedList.contains("jiaboyan");
//长度功能:
int size = linkedList.size();
//删除功能:
linkedList.remove(0);
linkedList.remove("jiaboyan");
linkedList.clear();
System.out.println("LinkedList当前容量:" + linkedList.size());
}
}
2. Set类集合
Set 接口继承Collection,用于存储不含重复元素的集合。几乎所有的Set实现都是基于同类型Map的,简单地说,Set是阉割版的Map。每一个Set内都有一个同类型的Map实例
Set的选择
| 底层实现 | 特性 | 适用场合 | |
|---|---|---|---|
| HashSet | 查询速度快;元素必须定义hashCode()方法 | 默认选择 | |
| LinkedHashSet | 链表 | 具有HashSet的查询速度;内部使用链表维护元素插入的次序;元素必须定义hashCode()方法 | |
| TreeSet | 树结构 | 可以从Set中提取有序的序列‘元素必须实现Comparable借口 |
2.1、 HashSet
HashSet是Set接口的典型实现,HashSet使用HASH算法来存储集合中的元素,因此具有良好的存取和查找性能。当向HashSet集合中存入一个元素时,HashSet会调用该对象的
HashSet有以下特点:
- 不能保证元素的排列顺序
- HashSet不是同步的,多个线程访问时,如果有多线程同时修改,需要代码来保证同步。
- 集合元素值可以是null
- 向HashSet 添加元素时,会调用该对象的 hashCode()得到该对象的hashCode值,根据hashCode值决定
HashSet的存储位置。 - 判断两个元素相等的标准是 通过 equals()方法比较相等,并且hashCode()返回的值也相等。
2.2、LinkedHashSet
LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但和HashSet不同的是,它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。
当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。
LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时(遍历)将有很好的性能(链表很适合进行遍历)
2.3、TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。SortedSet 是 Set的子接口。
TreeSet增加了以下方法:
- comparator(): 返回定制排序的Comparator;
- first(): 返回第一个元素
- last(): 最后一个元素
- lower(): 指定元素之前的元素
- higher(): 指定元素之后的元素
- subSet():返回子集
- headSet(): 小于指定元素的子集
- tailSet():大于等于指定元素的子集
3. Map类集合
Map的选择
| 底层实现 | 特性 | 适用场合 | |
|---|---|---|---|
| HashMap | 散列表 | 插入和查询的开销是固定的;可以通过构造方法设置容量和负载因子,调整性能 | 默认选择 |
| LinkedHashMap | 链表 | 取得元素的顺序是其插入顺序,或者最近使用次序;插入时比HashMap略慢,但迭代是更快 | HashMap是无序的,当我们希望有顺序地去存储key-value时 |
| TreeMap | 红黑树 | 总能保证有序;可以通过subMap()方法返回一个子树 | |
| WeakHashMap | 弱键映射,允许释放映射所指向的对象 | ||
| ConcurrentHashMap | 线程安全,不涉及同步加锁 | ||
| IdentityhashMap | 用==代替equals()进行比较;插入操作不会随着Map尺寸变大而明显变慢 |
3.1、HashMap
HashMap特点:
- HashMap是一个散列桶(数组和链表),它存储的内容是键值对(key-value)映射
- HashMap采用了数组和链表的数据结构,能在查询和修改方便继承了数组的线性查找和链表的寻址修改
- HashMap是非synchronized,所以HashMap很快
- HashMap可以接受null键和值,而Hashtable则不能(原因就是equlas()方法需要对象,因为HashMap是后出的API经过处理才可以)
HashMap 必知
以下是 HashMap 源码里面的一些关键成员变量以及知识点。在后面的源码解析中会遇到,所以我们有必要先了解下。
- initialCapacity:初始容量。指的是 HashMap集合初始化的时候自身的容量。可以在构造方法中指定;如果不指定的话,总容量默认值是 16 。需要注意的是初始容量必须是 2 的幂次方。
- size:当前 HashMap 中已经存储着的键值对数量,即 HashMap.size() 。
- loadFactor:加载因子。所谓的加载因子就是 HashMap (当前的容量/总容量) 到达一定值的时候,HashMap 会实施扩容。加载因子也可以通过构造方法中指定,默认的值是 0.75 。举个例子,假设有一个 HashMap 的初始容量为 16 ,那么扩容的阀值就是 0.75 * 16 = 12 。也就是说,在你打算存入第 13 个值的时候,HashMap 会先执行扩容。
- threshold:扩容阀值。即 扩容阀值 = HashMap 总容量 * 加载因子。当前 HashMap的容量大于或等于扩容阀值的时候就会去执行扩容。扩容的容量为当前 HashMap 总容量的两倍。比如,当前 HashMap 的总容量为16 ,那么扩容之后为 32 。
- table:Entry 数组。我们都知道 HashMap 内部存储 key/value 是通过 Entry 这个介质来实现的。而table 就是 Entry 数组
HashMap的工作原理:
HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,计算并返回的hashCode是用于找到Map数组的bucket位置来储存Node 对象。这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Node 。
以下是具体的put过程(JDK1.8版)
1、对Key求Hash值,然后再计算下标
2、如果没有碰撞,直接放入桶中(碰撞的意思是计算得到的Hash值相同,需要放到同一个bucket中)
3、如果碰撞了,以链表的方式链接到后面
4、如果链表长度超过阀值( TREEIFY THRESHOLD==8),就把链表转成红黑树,链表长度低于6,就把红黑树转回链表
5、如果节点已经存在就替换旧值
6、如果桶满了(容量16*加载因子0.75),就需要 resize(扩容2倍后重排)
以下是具体get过程(考虑特殊情况如果两个键的hashcode相同,你如何获取值对象?)
当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。
3.2、LinkedHashMap
LinkedHashMap继承了HashMap,所以它们有很多相似的地方。
LinkedHashMap的特点:
- LinkedHashMap的输入和输出顺序一致
- key和value可以同时为空
- key可以重复,但是新的key对应的value值会覆盖掉旧value值(这点和HashMap的哈希桶下元素存放规则相似)
LinkedHashMap 并没有重写任何 put 方法。但是其重写了构建新节点的 newNode() 方法。
newNode() 会在 HashMap 的 putVal() 方法里被调用,putVal() 方法会在批量插入数据 putMapEntries(Map m, boolean evict) 或者插入单个数据 public V put(K key, V value) 时被调用。
LinkedHashMap 重写了 newNode(),在每次构建新节点时,通过 linkNodeLast§; 将新节点链接在内部双向链表的尾部

其中的 linkNodeLast 方法,会将新增的节点。如果,集合之前是空的,指定 head 节点;否则将新节点连接在链表的尾部。
另外 LinkedHashMap 的 afterNodeInsertion 方法也非常的重要,它会在新节点插入之后回调,根据 evict 和 first 判断是否需要删除最老插入的节点。

LinkedHashMap 还重写了 afterNodeRemoval 这个方法。在删除节点 e 时,同步将 e 从双向链表上删除
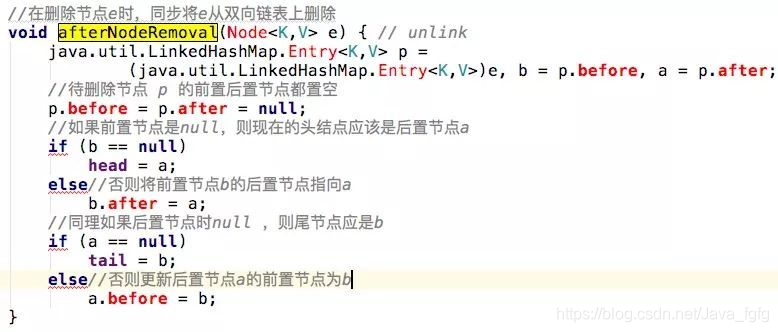
其实 LinkedHashMap 几乎和 HashMap 一样:从技术上来说,不同的是它定义了一个 Entry<K,V> header,这个 header 不是放在 Table 里,它是额外独立出来的。LinkedHashMap 通过继承 hashMap 中的 Entry<K,V>,并添加两个属性 Entry<K,V> before,after,和 header 结合起来组成一个双向链表,来实现按插入顺序或访问顺序排序。如何维护这个双向链表了,就是在get和put的时候用了钩子技术(多态)调用LinkedHashMap重写的方法来维护这个双向链表,然后迭代的时候直接迭代这个双向链表即可
3.3、TreeMap
TreeMap中的元素默认按照keys的自然排序排列。
(对Integer来说,其自然排序就是数字的升序;对String来说,其自然排序就是按照字母表排序)
常用方法
- 增添元素
V put(K key, V value):将指定映射放入该TreeMap中
V putAll(Map map):将指定map放入该TreeMap中 - 删除元素
void clear():清空TreeMap中的所有元素
V remove(Object key):从TreeMap中移除指定key对应的映射 - 修改元素
V replace(K key, V value):替换指定key对应的value值
boolean replace(K key, V oldValue, V newValue):当指定key的对应的value为指定值时,替换该值为新值 - 查找元素
boolean containsKey(Object key):判断该TreeMap中是否包含指定key的映射
boolean containsValue(Object value):判断该TreeMap中是否包含有关指定value的映射
Map.Entry<K, V> firstEntry():返回该TreeMap的第一个(最小的)映射
K firstKey():返回该TreeMap的第一个(最小的)映射的key
Map.Entry<K, V> lastEntry():返回该TreeMap的最后一个(最大的)映射
K lastKey():返回该TreeMap的最后一个(最大的)映射的key
v get(K key):返回指定key对应的value
SortedMap<K, V> headMap(K toKey):返回该TreeMap中严格小于指定key的映射集合
SortedMap<K, V> subMap(K fromKey, K toKey):返回该TreeMap中指定范围的映射集合(大于等于fromKey,小于toKey) - 遍历接口
Set<Map<K, V>> entrySet():返回由该TreeMap中的所有映射组成的Set对象
void forEach(BiConsumer<? super K,? super V> action):对该TreeMap中的每一个映射执行指定操作
Collection values():返回由该TreeMap中所有的values构成的集合 - 其他方法
Object clone():返回TreeMap实例的浅拷贝
Comparator<? super K> comparator():返回给该TreeMap的keys排序的comparator,若为自然排序则返回null
int size():返回该TreepMap中包含的映射的数量
List,Set,Map三者的区别?
-
List(对付顺序的好帮手)
1.可以允许重复的对象。
2.可以插入多个null元素。
3.是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
4.常用的实现类有 ArrayList、LinkedList 和 Vector -
Set(注重独一无二的性质):
1.不允许重复对象
2.无序容器,你无法保证每个元素的存储顺序,TreeSet通过 Comparator 或者 Comparable 维护了一个排序顺序。
3.只允许一个 null 元素
4.Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。 -
Map(用Key来搜索的专家):
1.Map不是collection的子接口或者实现类。Map是一个接口。
2.Map 的 每个 Entry 都持有两个对象,也就是一个键一个值(键值对),Map 可能会持有相同的值对象但键对象必须是唯一的。
3.TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
4.Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
5.Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)

















 250
250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









