



ReSearch是一种创新性框架,通过强化学习技术训练大语言模型执行"推理搜索",无需依赖推理步骤的监督数据。该方法将搜索操作视为推理链的有机组成部分,其中搜索的时机与方式由基于文本的推理过程决定,而搜索结果进一步引导后续推理。研究分析表明,ReSearch在强化学习训练过程中自然地形成了高级推理能力,包括反思与自我纠正机制。
技术方法
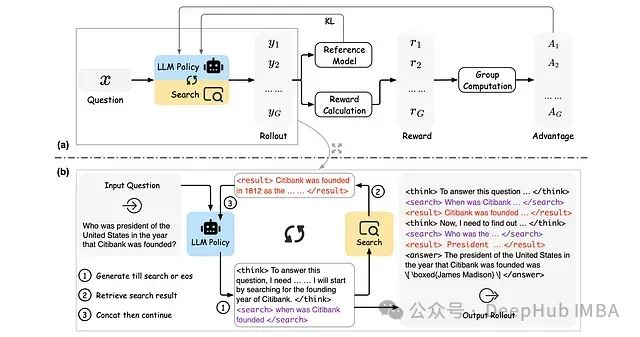
ReSearch的训练架构概述
与传统的仅包含文本推理的推理过程相比,ReSearch框架中的推理过程融合了搜索查询与检索结果。系统采用
和
标签来封装搜索查询,使用
和
标签来封装检索结果,这些格式规范在提示模板中明确定义。整个推理过程构成了基于文本的思考、搜索查询和检索结果之间的迭代循环。具体实现中,当生成过程遇到
标签时,系统会提取最近的
与当前
标签之间的内容作为查询语句,用于检索相关事实信息,检索结果则被
和
标签封装。随后,系统将现有推理与检索结果串联作为下一轮输入,以迭代方式生成后续响应,直至生成过程遇到结束句子(EOS)标记。
基础模型的提示模板:
指令模型的系统提示:
与原始GRPO不同,ReSearch中的损失函数计算经过了特殊处理。由于推理过程中包含的检索结果并非由训练策略生成,而是由搜索环境检索得到,因此在损失计算中对检索结果部分进行了掩码处理,以避免训练策略对检索结果产生不必要的偏好。
ReSearch的奖励函数设计包含两个核心组成部分:答案奖励和格式奖励:
- 答案奖励:通过F1分数计算
\boxed{}中的最终答案与真实答案之间的正确性。 - 格式奖励:验证推理过程是否正确遵循了提示模板中规定的格式规范,重点检查标签的正确使用以及答案中
\boxed{}的存在。
推理过程的最终奖励函数表达式如下:

实验配置
研究团队在Qwen2.5–7B、Qwen2.5–7B-Instruct、Qwen2.5–32B和Qwen2.5–32B-Instruct模型上进行了训练与评估。训练仅使用MuSiQue的训练集(19,938个样本),该数据集包含多种类型的多跳问题,并经过严格的质量控制构建。模型训练周期为2个完整周期。
在知识检索方面,研究采用E5-base-v2作为检索引擎,选用2018年12月的Wikipedia数据作为知识库。
评估采用了四个标准基准测试集来评估多跳问答任务性能:HotpotQA、WikiMultiHopQA、MuSiQue和Bamboogle。其中,HotpotQA、WikiMultiHopQA和MuSiQue通过不同的众包多跳挖掘策略在维基百科或维基数据中构建,而Bamboogle则是一个手动构建的挑战性数据集,包含双跳问题,其难度足以使主流互联网搜索引擎无法提供准确答案。
评估结果
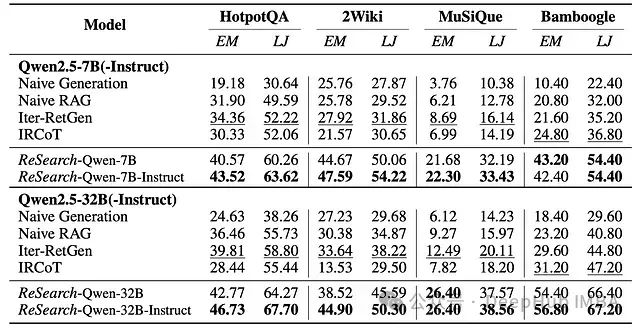
多跳问答基准测试上的精确匹配(EM,%)和LLM-as-a-Judge(LJ,%)评估结果
ReSearch框架在评估中展现了显著的性能优势:
- 显著超越基线模型:在所有基准测试中,ReSearch相比最佳基线模型,7B参数规模模型在精确匹配指标上平均提升了15.81%,在LLM-as-a-Judge指标上提升了17.56%;32B参数规模模型在精确匹配指标上平均提升了14.82%,在LLM-as-a-Judge指标上提升了15.46%。
- 指令微调效果显著:以指令微调过的LLM作为ReSearch的基础模型,相较于使用基础LLM,性能获得进一步提升。这一现象在所有基准测试和不同模型规模上均表现一致。
- 泛化能力强劲:尽管仅在MuSiQue数据集上进行训练,ReSearch仍能有效泛化到其他具有不同问题类型和结构的基准测试中,证明所学习的推理能力具有跨数据集的通用性。
训练过程中的响应长度和搜索操作数量变化
训练动态分析揭示了以下规律:
- 响应长度呈增长趋势:响应长度在训练过程中普遍呈现增长趋势,指令微调模型生成的响应通常长于基础模型。32B规模模型展现了独特的模式,初始阶段响应长度下降,随后再次上升,这可能反映了模型从依赖固有知识到有效利用检索结果的学习过程转变。
- 搜索操作持续增加:搜索操作数量在整个训练过程中稳步增长,表明模型逐渐学习到如何通过迭代搜索解决复杂多跳问题的能力。
训练过程中的训练和验证奖励变化
奖励指标分析表明:
- 奖励增长模式:训练和验证奖励在初始训练阶段呈现急剧上升趋势,随后进入平缓的持续提升阶段。指令微调模型从较高的奖励水平开始训练。7B规模模型最终收敛至相近的奖励水平,而32B指令微调模型始终维持高于其基础对应模型的奖励水平。
作者:Ritvik Rastogi


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









