




深夜,生产环境告警疯狂轰炸,Redis 集群数据不一致,交易系统瘫痪。这样的噩梦,相信不少开发者都曾经历过。查日志、排问题,结果发现是 Redis 集群脑裂作祟。这个看似神秘的"脑裂"问题,究竟是怎么回事?今天就带大家深入了解这个 Redis 集群中的棘手问题。
什么是 Redis 集群脑裂?
脑裂(Split-Brain),简单来说就是集群中的节点因为网络问题等原因,分裂成了多个小集群,各自"独立"工作,导致数据不一致。
脑裂产生的原因
Redis 集群脑裂主要由以下几个原因引起:
- 网络分区:机房之间的网络故障导致节点间通信中断
- 节点负载过高:主节点 CPU 或内存压力大,响应变慢
- 心跳超时配置不合理:心跳检测间隔太短或超时时间设置不当
- 意外重启:主节点服务器突然重启
实际案例分析
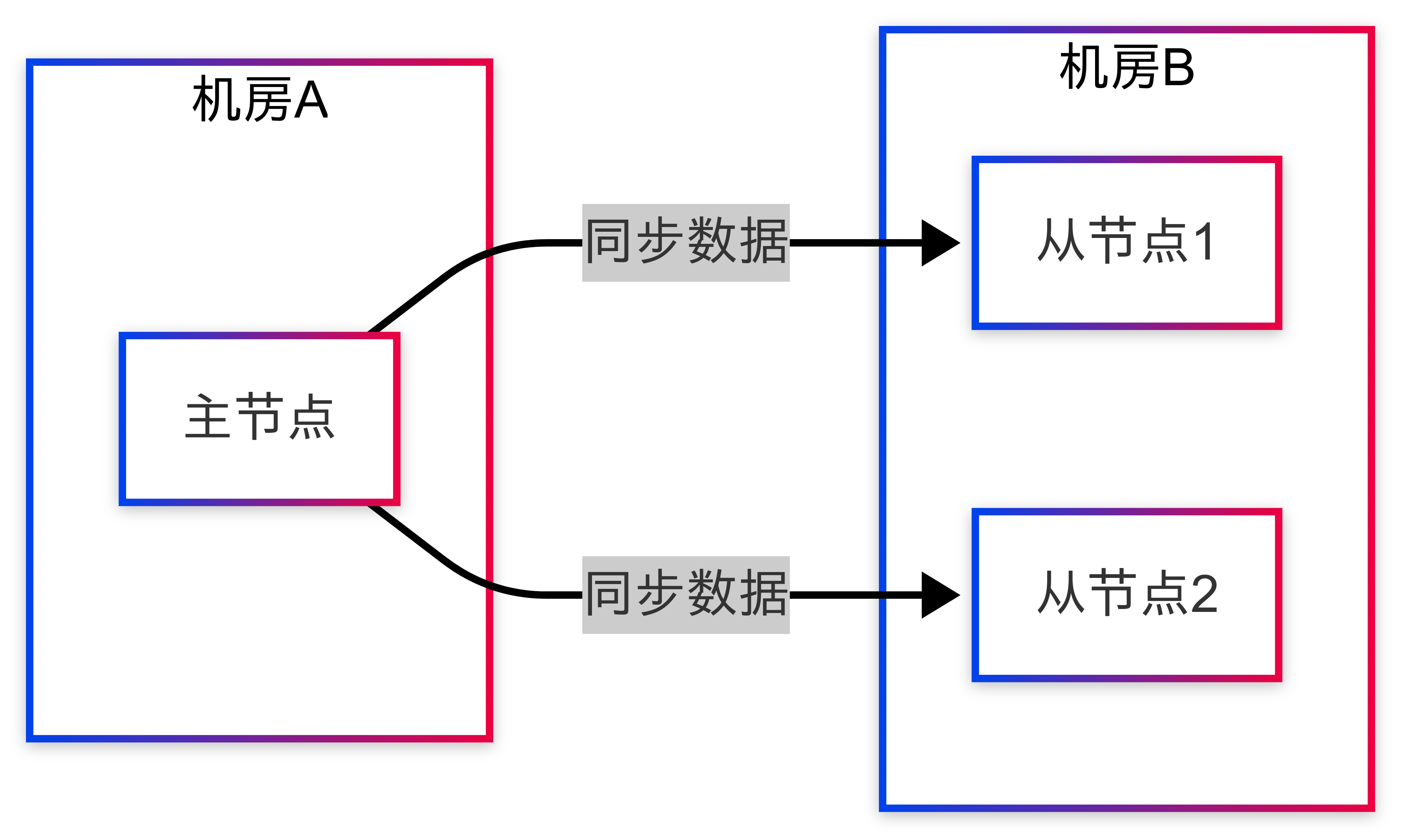
某金融支付平台在月底结算高峰期遇到了典型的脑裂问题。系统架构如下:
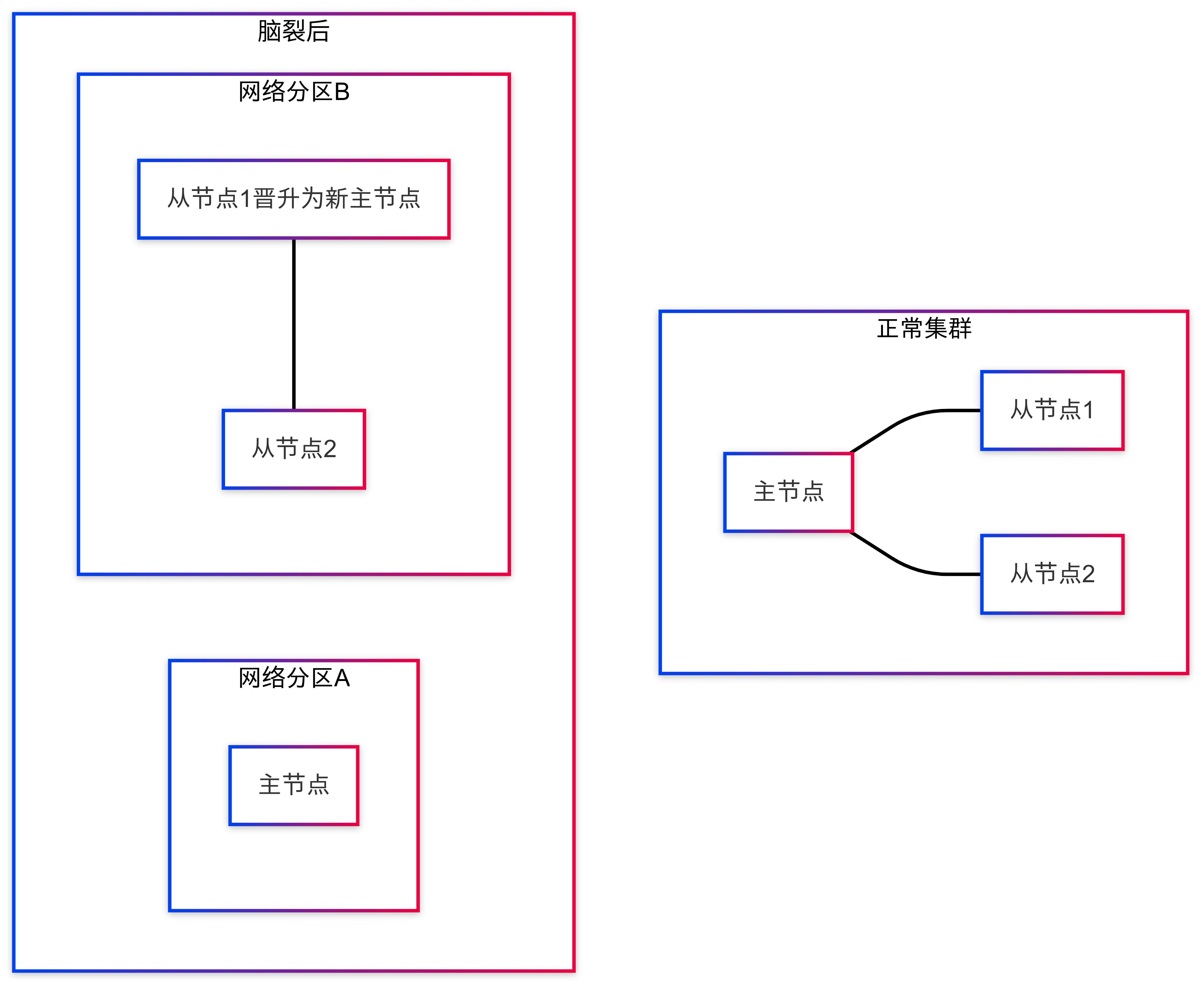
当机房间网络出现短暂抖动时,从节点们无法接收到主节点的心跳包。此时,哨兵(Sentinel)机制判断主节点已经下线,从从节点中选举了一个新的主节点。但实际上,主节点还在运行!
脑裂后的核心矛盾:主节点并不知道自己已被"废黜",仍然认为自己是主节点并继续接收写请求。同时,哨兵已选出的新主节点也开始接收写请求。这就导致了两个不同的"主节点"同时存在,各自维护不同的数据版本。
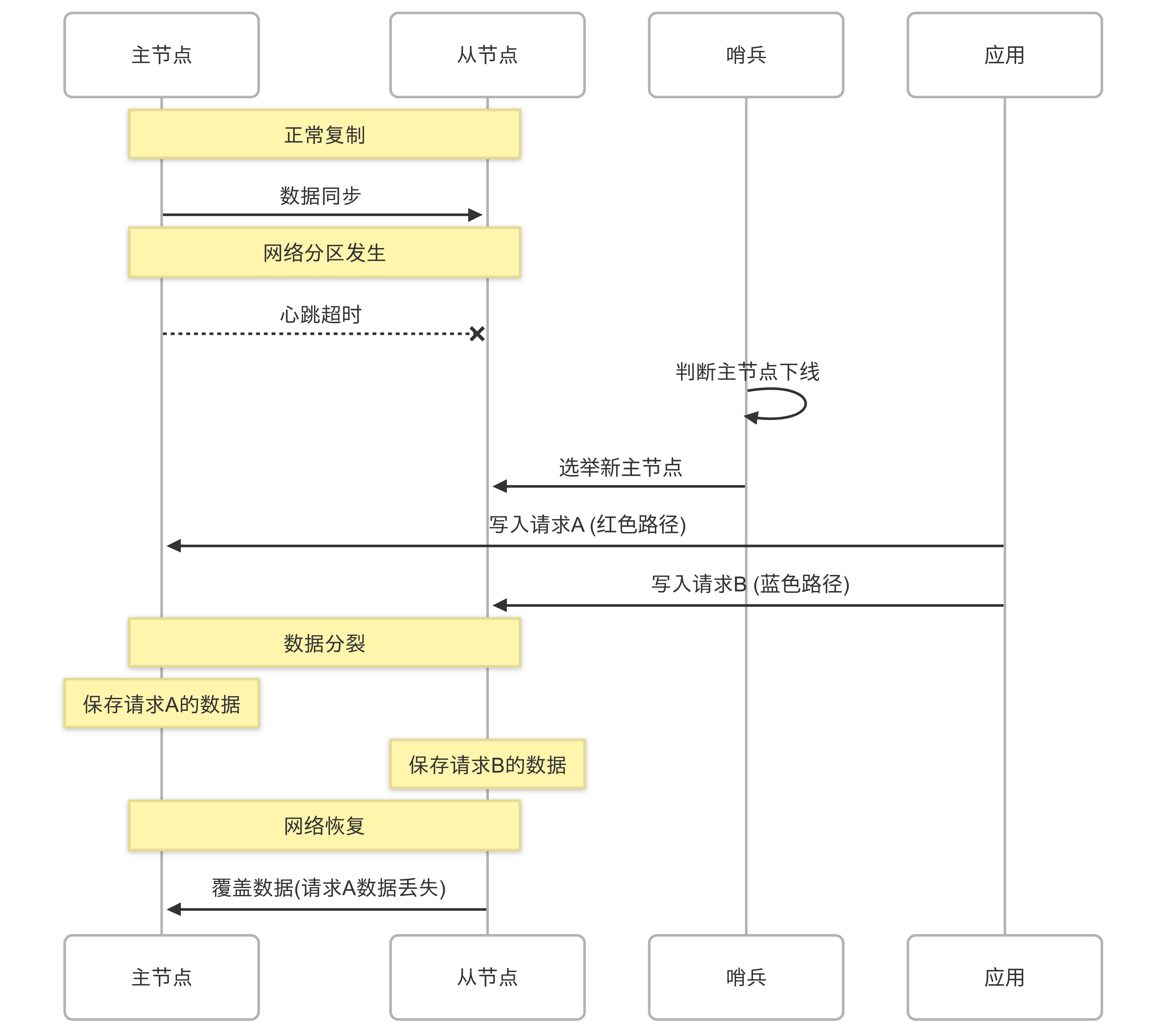
实际影响:
- 约 8%的交易记录被丢弃(主节点接收的交易未同步到新主节点)
- 数据不一致导致对账失败,账务系统出现差异
- 故障恢复耗时 45 分钟,期间部分支付渠道完全不可用
- 交易对账差异处理耗费了运维团队整整一周时间
如何检测 Redis 集群是否发生脑裂?
我们可以通过以下几种方式检测脑裂:
- 监控 info replication 输出:检查主从状态是否异常
public boolean checkSplitBrain(Jedis jedis) {
try {
String info = jedis.info("replication");
// 一次性解析所有需要的信息,提高效率
Map<String, String> infoMap = new HashMap<>();
for (String line : info.split("\n")) {
String[] parts = line.split(":", 2);
if (parts.length == 2) {
infoMap.put(parts[0].trim(), parts[1].trim());
}
}
// 获取角色和从节点数量
String role = infoMap.get("role");
int connectedSlaves = 0;
try {
if (infoMap.containsKey("connected_slaves")) {
connectedSlaves = Integer.parseInt(infoMap.get("connected_slaves"));
}
} catch (NumberFormatException e) {
// 格式解析异常时记录日志并使用默认值
logger.warn("Failed to parse connected_slaves value", e);
}
// 如果是主节点但没有从节点连接,可能是脑裂
return "master".equals(role) && connectedSlaves == 0;
} catch (Exception e) {
logger.error("Failed to check split brain status", e);
// 检测失败时保守返回,认为可能存在脑裂
return true;
}
}- Redis 哨兵日志分析:检查是否有频繁的主从切换记录
- 监控 master_run_id 变化:每个 Redis 实例都有唯一标识符,比较各节点认知的主节点 ID
public boolean detectMasterIdInconsistency(List<JedisPool> redisPools) {
String masterRunId = null;
try {
for (JedisPool pool : redisPools) {
try (Jedis jedis = pool.getResource()) {
String info = jedis.info("replication");
// 一次性解析信息
Map<String, String> infoMap = new HashMap<>();
for (String line : info.split("\n")) {
String[] parts = line.split(":", 2);
if (parts.length == 2) {
infoMap.put(parts[0].trim(), parts[1].trim());
}
}
// 获取角色和主节点ID
String role = infoMap.get("role");
String currentId = null;
// 根据角色获取相应的ID
if ("master".equals(role)) {
currentId = infoMap.get("run_id");
} else if ("slave".equals(role)) {
currentId = infoMap.get("master_run_id");
}
if (currentId != null) {
if (masterRunId == null) {
masterRunId = currentId;
} else if (!masterRunId.equals(currentId)) {
// 发现不同的master_run_id,表示存在多个主节点
logger.warn("Detected inconsistent master IDs: {} vs {}", masterRunId, currentId);
return true;
}
}
}
}
return false;
} catch (Exception e) {
logger.error("Failed to detect master ID inconsistency", e);
return true; // 检测失败时保守返回
}
}- 监控 master_link_status:从节点中的此值为"down"可能表示脑裂开始
public boolean checkMasterLinkStatus(Jedis slave) {
try {
String info = slave.info("replication");
// 一次性解析
Map<String, String> infoMap = new HashMap<>();
for (String line : info.split("\n")) {
String[] parts = line.split(":", 2);
if (parts.length == 2) {
infoMap.put(parts[0].trim(), parts[1].trim());
}
}
String status = infoMap.get("master_link_status");
return "up".equals(status); // 返回链接是否正常
} catch (Exception e) {
logger.error("Failed to check master link status", e);
return false;
}
}脑裂问题解决方案
配置层面的预防
- 优化 Redis 配置
Redis 提供了三个重要参数来防止脑裂:
min-replicas-to-write 1 # 主节点必须至少有1个从节点连接
min-replicas-max-lag 10 # 数据复制和同步的最大延迟秒数
cluster-node-timeout 15000 # 集群节点超时毫秒数这些配置的作用是:当主节点发现从节点数量不足或者数据同步延迟过高时,拒绝写入请求,防止数据不一致。
重要说明:min-replicas-max-lag的单位是秒,与 Redis INFO 命令返回的lag字段单位一致。这确保了配置与监控的一致性。
- 网络质量保障
确保 Redis 集群节点间的网络稳定:
- 使用内网专线连接
- 避免跨公网部署
- 配置合理的 TCP keepalive 参数
- 多机房部署时:确保跨机房专线有冗余通道,避免单点故障
代码层面的解决方案
使用 Java 实现脑裂监控和自动恢复:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









