



一、应用程序
基本概念:

pod存在的意义:
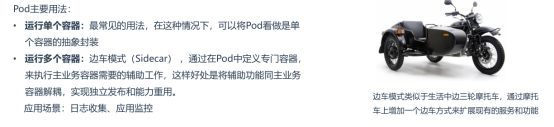
1、容器之间资源共享实现:
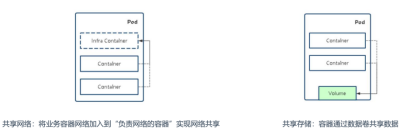
演示共享网络:
[root@k8s-master ~]# vim pod-network.yaml
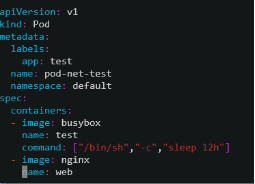
[root@k8s-master ~]# kubectl apply -f pod-network.yaml #加载配置文件

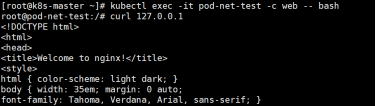
进入busybox,访问nginx

进入nginx:
查看新建的pod分配到node2上:

查看到nginx,busybox。还有负责网络的pause

演示存储共享:
[root@k8s-master ~]# cat pod-volume.yaml
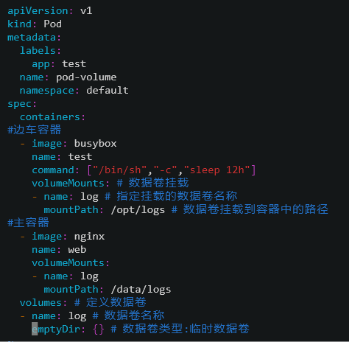
[root@k8s-master ~]# kubectl apply -f pod-volume.yaml

在边车容器里面创建一个文件
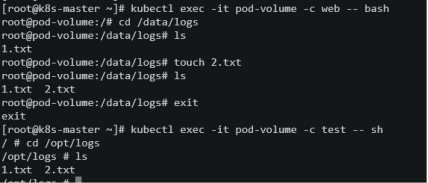
[root@k8s-master ~]# kubectl exec -it pod-volume -c test -- sh

在主容器里面查看可以看到在边车容器中创建的文件1.txt,同时在主容器里面创建文件2.txt,在边车容器中也可以看到2.txt
2、pod常用命令
创建Pod:
kubectl apply -f pod.yaml
或者使用命令:kubectl run nginx --image=nginx
查看Pod:
kubectl get pods
kubectl describe pod <Pod名称>
查看容器日志:
kubectl logs <Pod名称> [-c CONTAINER]
kubectl logs <Pod名称> [-c CONTAINER] -f实时查看日志
进入容器终端:
kubectl exec -it <Pod名称> [-c CONTAINER] -- bash
删除Pod:
kubectl delete pod <Pod名称>
kubectl delete pod <Pod名称> --grace-period=0 --force强制删除
3、容器的健康检查


定义容器yaml:(deployment ,service,pod和健康检查)
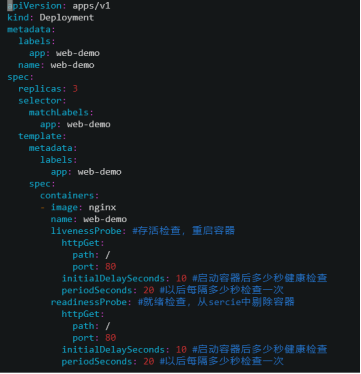
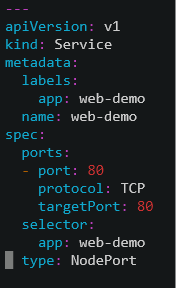
查看新建的deployment ,service,pod的状态
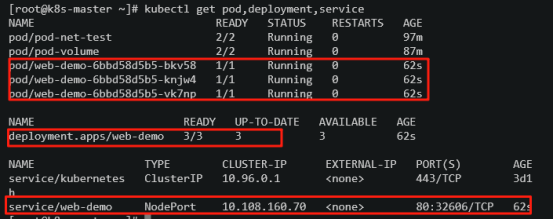
查看一个容器的日志,发现容器访问的网页回复200,状态是正常的
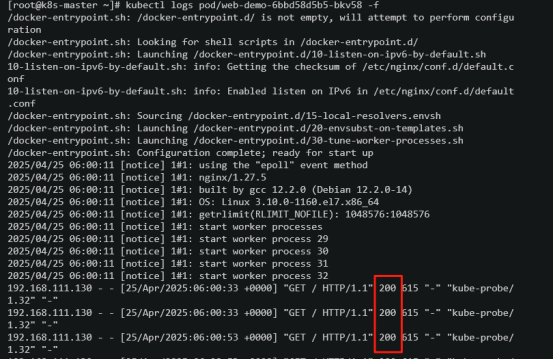
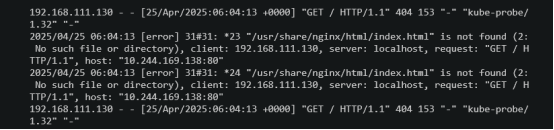
模拟容器访问页面失败(将页面文件注释掉)

查看日志访问页面变成403
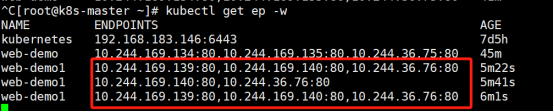
查看pod被重新拉起一次:(刚才测试两次,pod被拉起两次)

查看容器日志,容器被重启

容器重新生成,但是容器的IP和名字没有变
登陆容器发现访问页面又恢复了

说明:容器有故障的时k8s会删除这个容器,再用原来的镜像重新拉起一台容器,重新运行。
4、容器环境变量

[root@k8s-master ~]# vim pod-envs.yaml
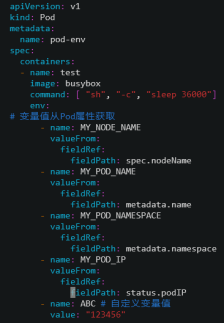
[root@k8s-master ~]# kubectl apply -f pod-envs.yaml

验证:
[root@k8s-master ~]# kubectl exec -it pod-envars -- sh
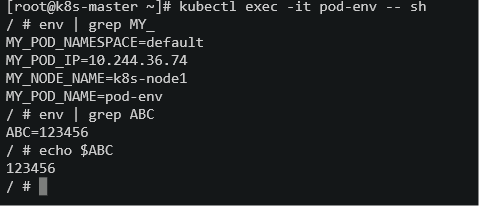
5、初始化容器



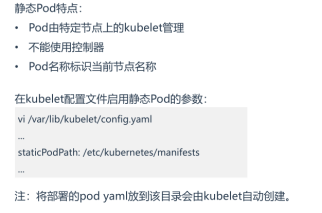
二、Kubernetes调度
1、创建一个Pod的工作流程
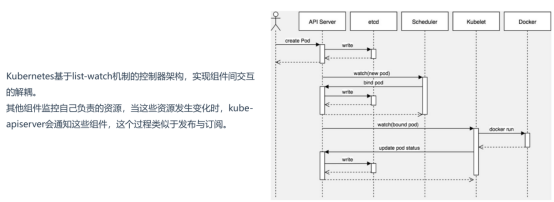
具体过程:
kubectl run pod666 --image=nginx:1.23
1、kubectl向apiserver发起创建Pod请求,apiserver收到请求将其配置存储到Etcd中
2、apiserver会通知scheduler将该Pod分配到一个合适的节点上,scheduler根据自身调度算法分配到某个节点,再响应给apiserver。
3、apiserver会通知kubelet创建pod,kubelet再调用容器运行时根据配置创建相关容器,并将容器状态汇报给apiserver。
kubectl get pods
这个过程中,有两个组件没有涉及:
controller-manager:负责控制器相关资源创建的,例如deployment
kube-proxy:负责Service资源创建的
2、资源限制与资源请求对调度的影响

生成一个yaml文件:
[root@k8s-master ~]# kubectl run nginx-pod --image=nginx --dry-run=client -o yaml > pod-resources.yaml
查看并更改yaml文件,限制cpu和内存的使用量

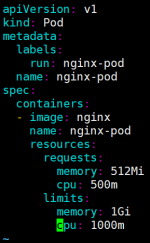
[root@k8s-master ~]# kubectl apply -f pod-resources.yaml


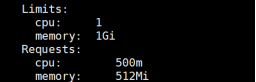
查看node节点的资源使用情况:
[root@k8s-master ~]# kubectl describe node k8s-node2
看最下面:
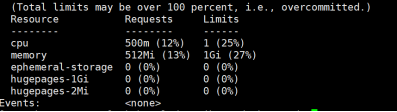
说明:
1、requests的值必须小于limits的值
2、requests的值小于limits的30%左右,是一个良性参考值
3、limits的值不要设置超过节点硬件配置,建议至少低于节点硬件配置的20%
4、k8s层面有一个资源管理的概念,主要是根据request实现的
5、requests的值并不是是实际占用的。
影响:
如果集群中Pod的requests值设置比较大,会有什么影响?
节点运行pod少,实际资源空闲。
如果集群中Pod的requests值设置比较小,会有什么影响?
节点运行Pod多,可能会导致资源利用率高。
3、基于节点标签调度(nodeSelector)



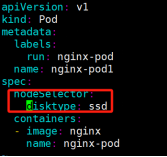
运行:

查看分配到node1节点上

删除节点标签:

4、基于节点标签调度(nodeAffinity)

5、Taint(污点)与Tolerations(污点容忍)
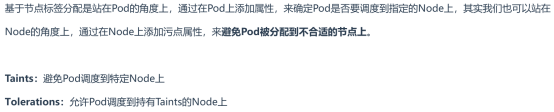

再node1上创建一个污点,创建3个容器,查看到容器都再node2上:
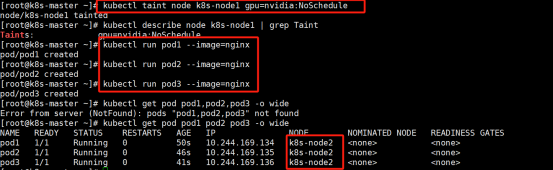
希望分配到污点节点
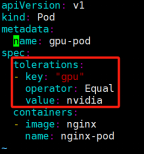

一定要让Pod分配到某一个带有污点的节点上:污点容忍+节点标签选择器
补充:
master 节点本身也是一个污点节点,为了让master节点方便管理,也更安全。

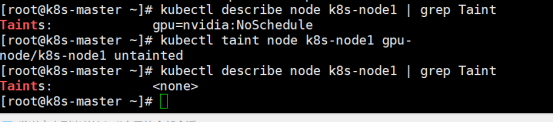
取消污点:
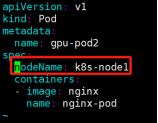
6、nodeName:


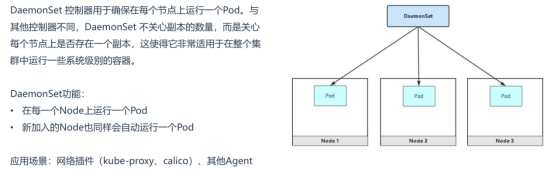
7、DaemonSet控制器
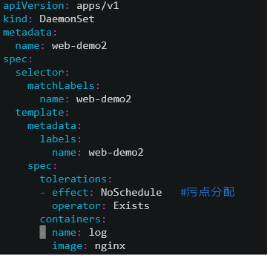
示例:部署一个日志采集程序:
[root@k8s-master ~]# vim daemonset.yaml
每个几点都会运行一个pod

8、pod调度失败的原因:
查看调度结果:
kubectl get pod <NAME> -o wide
查看调度失败原因:kubectl describe pod <NAME>
• 节点CPU/内存不足
• 有污点,没容忍
• 没有匹配到节点标签

















 1543
1543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









