



我们需要 正则表达式+re模块 对字符串进行详细匹配、替换等操作。
正则表达式:

re模块中常用语法:
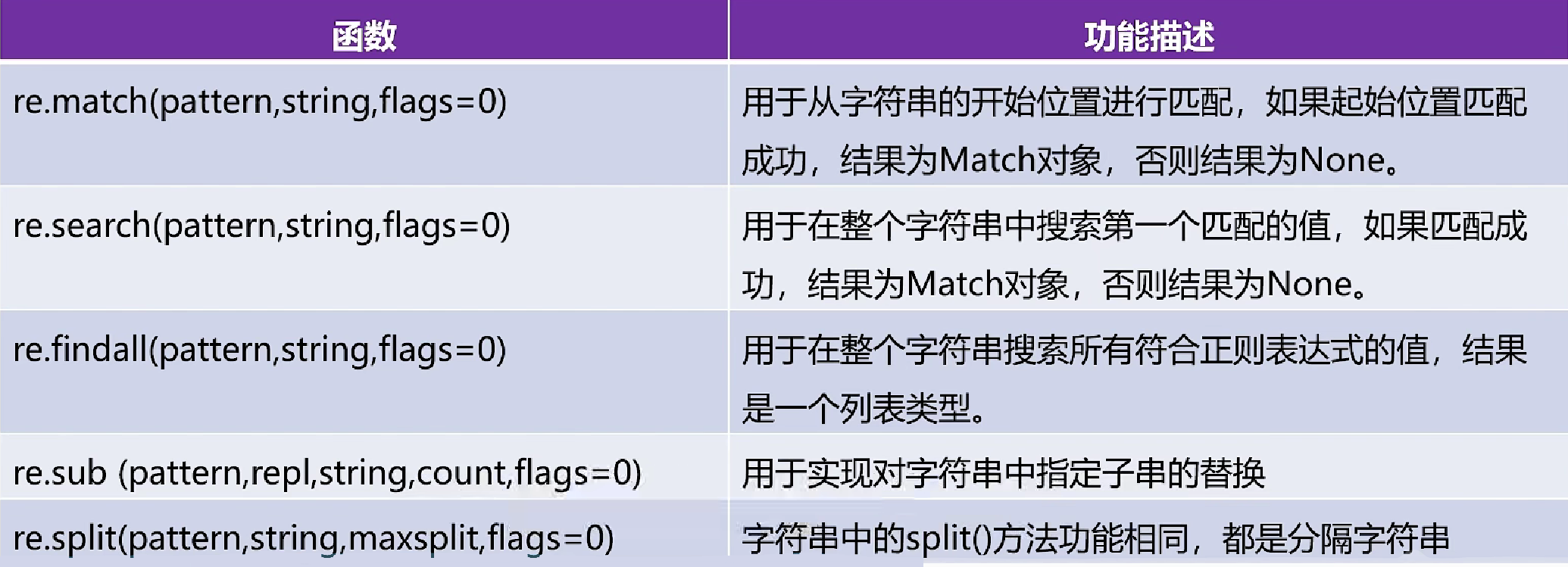
(1)匹配 re.match ( )
import re
pattern ='\d\.\d+' # '\d'表示单个数字 ; '\.'用于匹配'.'其中'\'为转译字符 ; '\d+'表示匹配一次或多次数字
str1 = 'I study python2.7 and python3.11 every day'
match1 = re.match(pattern,str1,re.I) # re.I 表示ignore,忽略大小写进行匹配
print(match1) # None ,因为re.match()从开始位置匹配
str2 = '2.7python and 3.11python I study every day'
match2 = re.match(pattern,str2,re.I)
print(match2) # <re.Match object; span=(0, 3), match='2.7'>,返回了一个match对象
# 输出match对象的各个部分
print('匹配值的起始位置:',match2.start()) # 匹配值的起始位置: 0
print('匹配值的结束位置:',match2.end()) # 匹配值的结束位置: 3
print('匹配区间:',match2.span()) # 匹配区间: (0, 3)
print('匹配值:',match2.group()) # 匹配值: 2.7
print('所匹配的原字符串:',match2.string) # 所匹配的原字符串: 2.7python and 3.11python I study every day- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
(2)单个搜索 re.search ( ) 和 全部搜索 re.findall ( )
import re
pattern ='\d\.\d+'
str1 = 'I study python2.7 and python3.11 every day'
# 单个搜索 re.search( )仅仅能搜索到第一个匹配的值
match1 = re.search(pattern,str1)
print(match1) # <re.Match object; span=(14, 17), match='2.7'>,只有2.7
print(match1.group()) # 2.7, re.search( )返回的同样是match对象,也可以用.group()
# 全部搜索 re.findall ( )返回的是列表类型
lst1 = re.findall(pattern,str1)
print(lst1) # ['2.7', '3.11']- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
(3)替换 re.sub ( )
(4)分隔 re.split ( )

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









