




Graph Transformer是一种将Transformer架构应用于图结构数据的特殊神经网络模型。该模型通过融合图神经网络(GNNs)的基本原理与Transformer的自注意力机制,实现了对图中节点间关系信息的处理与长程依赖关系的有效捕获。
Graph Transformer的技术优势
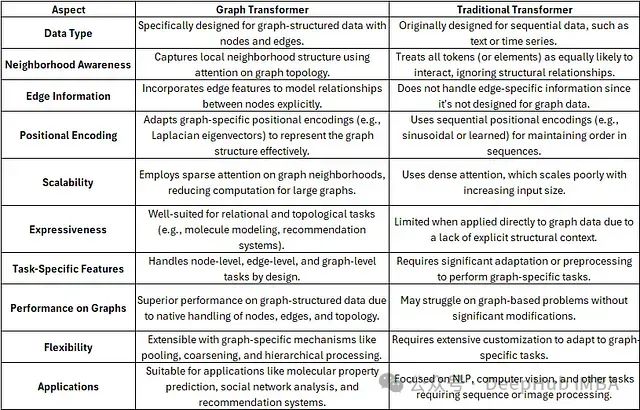
在处理图结构数据任务时,Graph Transformer相比传统Transformer具有显著优势。其原生集成的图特定特征处理能力、拓扑信息保持机制以及在图相关任务上的扩展性和性能表现,都使其成为更优的技术选择。虽然传统Transformer模型具有广泛的应用场景,但在处理图数据时往往需要进行大量架构调整才能达到相似的效果。
核心技术组件
图数据表示方法
图输入数据通过节点、边及其对应特征进行表示,这些特征随后被转换为嵌入向量作为模型输入。具体包括:
- 节点特征表示- 社交网络:用户的人口统计学特征、兴趣偏好、活动频率等量化指标- 分子图:原子的基本特性,包括原子序数、原子质量、价电子数等物理量- 定义:节点特征是对图中各个节点属性的数学表示,用于捕获节点的本质特性- 应用实例:
- 边特征表示- 社交网络:社交关系类型(如好友关系、关注关系、工作关系等)- 分子图:化学键类型(单键、双键、三键)、键长等化学特性- 定义:边特征描述了图中相连节点间的关系属性,为图结构提供上下文信息- 应用实例:
技术要点: 节点特征与边特征构成了Graph Transformer的基础数据表示,这种表示方法从根本上改变了关系型数据的建模范式。
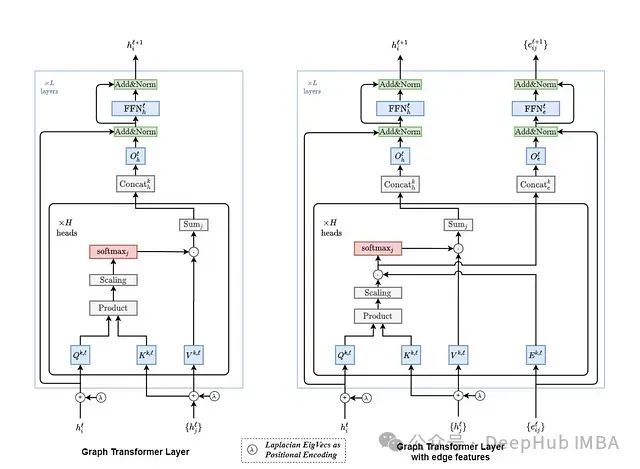
自注意力机制的技术实现
自注意力机制通过计算输入的加权组合来实现节点间的关联性分析。在图结构环境下,该机制具有以下关键技术要素:
数学表示
- 节点特征向量: 每个节点i对应一个d维特征向量h_i
- 边特征向量: 边特征e_ij表征连接节点i和j之间的关系属性
注意力计算过程
注意力分数计算注意力分数评估节点间的相关性强度,综合考虑节点特征和边属性,计算公式如下:
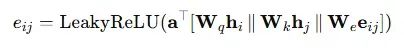
其中:
- W_q, W_k, W_e:分别为查询向量、键向量和边特征的可训练权重矩阵
- a:可训练的注意力向量
- ∥:向量拼接运算符
注意力权重归一化原始注意力分数通过SoftMax函数在节点的邻域内进行归一化处理:
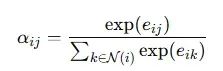
N(i)表示节点i的邻接节点集合。
信息聚合机制每个节点通过加权聚合来自邻域节点的信息:
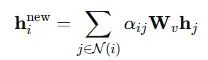
W_v表示值投影的可训练权重矩阵。
Graph Transformer中自注意力机制的技术优势

自注意力机制在Graph Transformer中的应用实现了节点间的动态信息交互,显著提升了模型对图结构数据的处理能力。
拉普拉斯位置编码技术
拉普拉斯位置编码利用图拉普拉斯矩阵的特征向量来实现节点位置的数学表示。这种编码方法可以有效捕获图的结构特征,实现连通性和空间关系的编码。通过这种技术Graph Transformer能够基于节点的结构特性进行区分,从而在非结构化或不规则图数据上实现高效学习。
消息传递与聚合机制
消息传递和聚合机制是图神经网络的核心技术组件,在Graph Transformer中具有重要应用:
- 消息传递实现节点与邻接节点间的信息交换
- 聚合操作将获取的信息整合为有效的特征表示
这两个技术组件的协同作用使图神经网络,特别是Graph Transformer能够学习到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









