





大语言模型也只是将用户提供的大规模数据集训练而来,也并非万能的什么都知道,特别是一些小众知识、内部数据或私密的个人数据等,此时ChatGLM肯定会胡乱回答,就是ChatGPT4也不一定能给出满意回答;不少公司、个人都有自己的知识库或日志等。此时如有可将这些数据以某种方式挂在大模型上,此时在知识库存在的知识可从中作答,不属于知识库中的内容还是按照大模型原来方式生成,精准度会高不少;知识库的内容包括文本、PDF、图片、视频、网页等等;
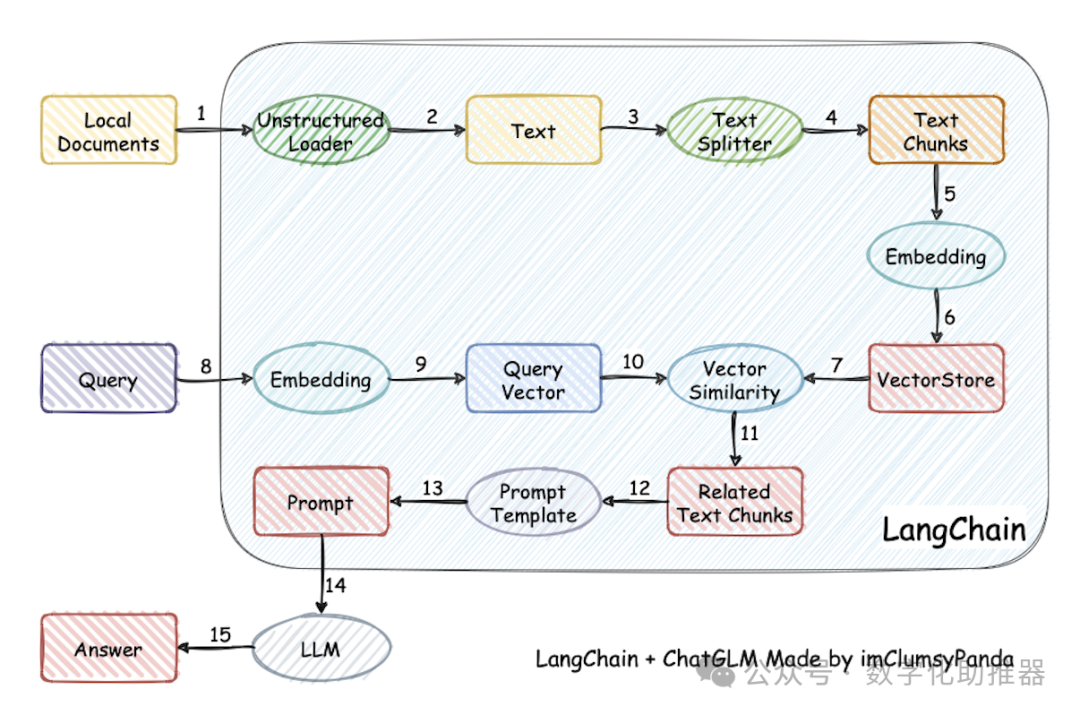
基于LLM的本地私有化知识库实现主要分为两种:
**1、模型训练微调:**将知识库的内容整理成训练数据集,拿这些整理好的数据集来训练该模型,最终让模型“学会”该知识库的内容,至于效果如何很大程度取决于该数据集的质量和训练的调参,这种方式较复杂、门槛高;
**2、外挂知识库:**在向模型提问时提供一些知识库中的内容让它在其中找到正确的答案,外挂的形式门槛相对低一点大部分的工作主要是文档的处理:加载、切分、向量化、持久化、相识度对比等以及Prompt编写。

知识库预处理相关概念
加载文件: 加载知识库中的文本**;
**
文本分割(TextSplitter): 按一定规则将文本分割,具体参数有: separator:分隔符、chunk_size: 文本块长度、chunk_overlap: 文本块之间重叠的长度、length_function:计算长度的方法; 文本块长度选择可能会对文本分割效果右较大的影响;
文本向量化: 将文本转换为向量,文本向量化后用于后续存储、计算相识度、检索相关文本等;
文本内嵌(Embedding): 将离散的符号或对象表示为连续的向量空间中的点;文本嵌入可用于以下功能:搜索、聚类、推荐、异常检测、多样本测量、分类;此处主要是用于查询的嵌入向量(问题向量化后)与每个文档的嵌入向量之间的余弦相似度,并返回得分最高的文档。Embedding开源模型模型有:Text2vec、Ernie-3.0、M3E等
持久化: 将向量化的数值存储到向量数据库方便后续直接使用,向量数据库有Chroma、Qdrant等;
随着人工智能技术的迅猛发展,问答机器人在多个领域中展示了广泛的应用潜力。在这个信息爆炸的时代,许多领域都面临着海量的知识和信息,人们往往需要耗费大量的时间和精力来搜索和获取他们所需的信息。
在这种情况下,垂直领域的 AI 问答机器人应运而生。OpenAI 的 GPT3.5 和 GPT4 无疑是目前最好的 LLM(大语言模型),借助 OpenAI 的 GPT 确实可以快速地打造出一个高质量的 AI 问答机器人,但是 GPT 在实际应用上存在着不少限制。比如 ChatGPT 的知识库是通用领域的,对于垂直领域的知识理解有限,而且对于不熟悉的知识还会存在幻觉的问题。因此,构建专业领域大模型应运而生。
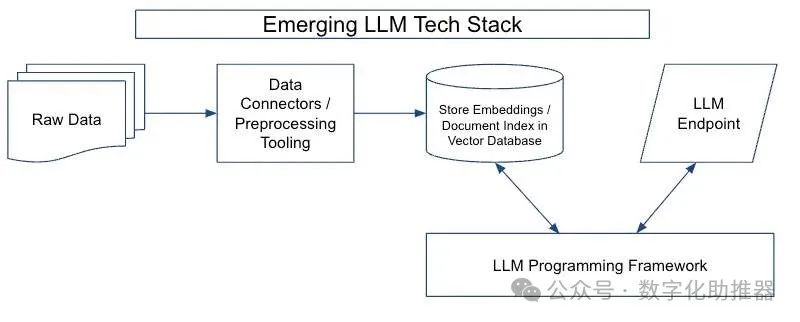
 新兴 LLM 技术栈
新兴 LLM 技术栈
大语言模型技术栈由四个主要部分组成:
-
数据预处理流程(data preprocessing pipeline)
-
嵌入端点(embeddings endpoint )+向量存储(vector store)
-
LLM 终端(LLM endpoints)
-
LLM 编程框架(LLM programming framework
如果想要在机器上跑自己部署的LLM,那么你至少需要一台配置不错的 GPU 服务器,否则
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









