



一:目标站点信息
彼岸桌面 网址为:http://www.netbian.com/
二:目标站点分析
(1):构造页面的URL列表
我们需要做的是爬取网站上给定页数的图片,所以,我们首先需要的就是观察各个页面链接之间的关系,进而构造出需要爬取页面的url列表。
第一页的链接:http://www.netbian.com/
第二页的链接:http://www.netbian.com/index\_2.htm
可以看出,从第二页开始之后的页面链接只是后面的数字不同,我们可以写个简单的代码,获取页面的url列表
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
#获取爬取的页数和页面链接
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)
请输入你想爬取的页数:5
['http://www.netbian.com/', 'http://www.netbian.com/index\_2.htm',
'http://www.netbian.com/index\_3.htm', 'http://www.netbian.com/index\_4.htm',
'http://www.netbian.com/index\_5.htm'\]
(2):获取一个页面中所有的图片的链接
我们已经获取了所有页面的链接,但是没有获取每张图片的链接,所以,接下来我们需要做的就是获取一个页面中的所有图片的链接。在这里,我们以第一页为例,获取每张图片的链接,其他页面类似。
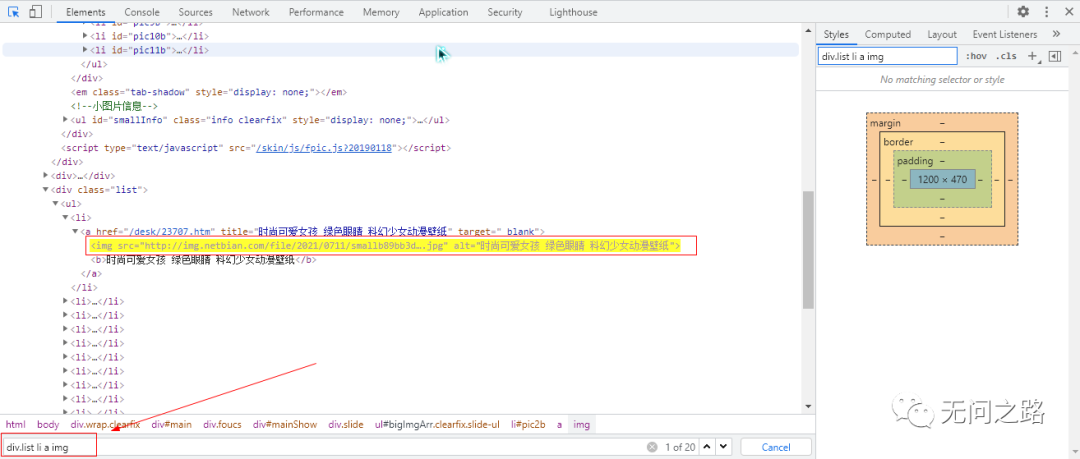
首先在页面中右键->查看元素,然后点击查看器左边的那个小光标,再把鼠标放在随意一个图片上,这样就定位到这个图片所在的代码位置了;我们可以知道,每个页面有18张图片,接下来,我们需要采用标签去定位页面中的图片的具体位置,如下图所示,我们使用 div.list li a img 刚好定位到了18个img标签。img标签中就包含了我们需要的图片链接。
接下来,我们以第一个页面为例,获取每个图片的链接。
import requests
from bs4 import BeautifulSoup
# 页面链接的初始化列表
url='http://www.netbian.com/'
# 图片链接列表
img_links_list = []
#获取img标签,在获取图片链接
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))
['http://img.netbian.com/file/2019/0817/smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg',
'http://img.netbian.com/file/2019/0817/small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg',
'http://img.netbian.com/file/2018/1225/604a688cd6f79161236e6250189bc25b.jpg',
'http://img.netbian.com/file/2019/0817/smallab7249d18e67c9336109e3bedc094f381566034907.jpg',
'http://img.netbian.com/file/2019/0817/small5816e940e6957f7db5e499de9978bda41566031298.jpg',
'http://img.netbian.com/file/2019/0817/smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg',
'http://img.netbian.com/file/2019/0817/small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg',
'http://img.netbian.com/file/2019/0817/smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg',
'http://img.netbian.com/file/2019/0817/smalld1f07e215f0da059b44d27623ec6fa8f1566029835.jpg',
'http://img.netbian.com/file/2019/0817/small1674b7b97714672be3165bd31de418eb1566014363.jpg',
'http://img.netbian.com/file/2019/0814/small1a5c2fe49dec02929f219d0bdb680e9c1565786931.jpg',
'http://img.netbian.com/file/2019/0814/smalle333c0a8e9fe18324d793ce7258abbbf1565786718.jpg',
'http://img.netbian.com/file/2019/0814/smallb0c9494b4042ac9c9d25b6e4243facfd1565786402.jpg',
'http://img.netbian.com/file/2019/0814/small19dfd078dd820bb1598129bbe4542eff1565786204.jpg',
'http://img.netbian.com/file/2019/0808/smallea41cb48c796ffd3020514994fc3e8391565274057.jpg',
'http://img.netbian.com/file/2019/0808/small3998c40805ea6811d81b7c57d8d235fc1565273792.jpg',
'http://img.netbian.com/file/2019/0808/smallb505448b1318dbb2820dcb212eb39e191565273639.jpg',
'http://img.netbian.com/file/2019/0808/small0f04af422502a40b6c8dc19d53d1f3481565273554.jpg'\]
18
(3):将图片下载到本地
有了图片链接后,我们需要将图片下载到本地,在这里我们以第一张图片为例进行下载
url:http://img.netbian.com/file/2019/0817/smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
import urllib.request
url='http://img.netbian.com/file/2019/0817/smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg'
urllib.request.urlretrieve(url, filename='test.jpg')
(4):获取图片的简单爬虫
结合以上三个部分,构造页面的url列表、获取一个页面中的所有图片链接和将图片下载到本地。构造一个完整但效率不高的爬虫。
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#获取图片并下载到本地
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img\['src'\]
display=link.split('/')\[-1\]
print('正在下载:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#获取爬取的页数,返回链接数
def GetUrls(page\_links\_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index\_' + str(page) + '.htm'
page\_links\_list.append(url)
else:
page\_links\_list=page\_links\_list
if \_\_name\_\_ == '\_\_main\_\_':
page\_links\_list=\['http://www.netbian.com/'\]
GetUrls(page\_links\_list)
os.mkdir('./images')
print("开始下载图片!!!")
start = time.time()
for url in page\_links\_list:
GetImages(url)
print('图片下载成功!!!')
end = time.time() - start
print('消耗时间为:', end)
请输入你想爬取的页数:5
开始下载图片!!!
正在下载: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
正在下载: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg
正在下载: 604a688cd6f79161236e6250189bc25b.jpg
正在下载: smallab7249d18e67c9336109e3bedc094f381566034907.jpg
正在下载: small5816e940e6957f7db5e499de9978bda41566031298.jpg
正在下载: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg
正在下载: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg
正在下载: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg
。。。。。。
图片下载成功!!!
消耗时间为: 21.575999975204468
以上这部分代码就可以完整的运行了,但是效率不高,因为是下载图片,需要一个个排队进行下载。所以,为了解决这个问题,下面的代码我们就使用了多线程来实现图片的爬取和下载。
(5)用Python多线程爬取图片并下载到本地
多线程我们使用的是Python自带的threading模块。并且我们使用了一种叫做生产者和消费者的模式,生产者专门用来从每个页面中获取图片的下载链接存储到一个全局列表中。而消费者专门从这个全局列表中提取图片链接进行下载。
需要注意的是,在多线程中使用全局变量要用锁来保证数据的一致性。
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
\# 页面链接的初始化列表
page\_links\_list=\['http://www.netbian.com/'\]
\# 图片链接列表
img\_links\_list = \[\]
#获取爬取的页数和页面链接
def GetUrls(page\_links\_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index\_' + str(page) + '.htm'
page\_links\_list.append(url)
else:
page\_links\_list=page\_links\_list
#初始化锁,创建一把锁
gLock=threading.Lock()
#生产者,负责从每个页面中获取图片的链接
class Producer(threading.Thread):
def run(self):
while len(page\_links\_list)>0:
#上锁
gLock.acquire()
#默认取出列表中的最后一个元素
page\_url=page\_links\_list.pop()
#释放锁
gLock.release()
#获取img标签
html = requests.get(page\_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#加锁3
gLock.acquire()
for img in imgs:
img\_link = img\['src'\]
img\_links\_list.append(img\_link)
#释放锁
gLock.release()
#print(len(img\_links\_list))
#消费者,负责从获取的图片链接中下载图片
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current\_thread())
while True:
#print(len(img\_links\_list))
#上锁
gLock.acquire()
if len(img\_links\_list)==0:
#不管什么情况,都要释放锁
gLock.release()
continue
else:
img\_url=img\_links\_list.pop()
#print(img\_links\_list)
gLock.release()
filename=img\_url.split('/')\[-1\]
print('正在下载:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img\_url, filename=path)
if len(img\_links\_list)==0:
end=time.time()
print("消耗的时间为:", (end - start))
exit()
if \_\_name\_\_ == '\_\_main\_\_':
GetUrls(page\_links\_list)
os.mkdir('./images')
start=time.time()
# 5个生产者线程,去从页面中爬取图片链接
for x in range(5):
Producer().start()
# 10个消费者线程,去从中提取下载链接,然后下载
for x in range(10):
Consumer().start()
请输入你想爬取的页数:5
<Consumer(Thread-6, started 5764)> is running
<Consumer(Thread-7, started 9632)> is running
<Consumer(Thread-8, started 9788)> is running
<Consumer(Thread-9, started 5468)> is running
<Consumer(Thread-10, started 9832)> is running
<Consumer(Thread-11, started 3320)> is running
<Consumer(Thread-12, started 6456)> is running
<Consumer(Thread-13, started 10080)> is running
<Consumer(Thread-14, started 3876)> is running
<Consumer(Thread-15, started 9224)> is running
正在下载: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg
正在下载: small02961cac5e02a901b77779eaed43c6f91564156941.jpg
正在下载: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg
正在下载: smallfedb420af6f753512c169021587982621564455847.jpg
正在下载: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg
正在下载: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg
正在下载: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg
。。。。。。
消耗的时间为: 1.635000228881836 #分别是10个进程结束的时间
消耗的时间为: 1.6419999599456787
消耗的时间为: 1.6560001373291016
消耗的时间为: 1.684000015258789
消耗的时间为: 1.7009999752044678
消耗的时间为: 1.7030000686645508
消耗的时间为: 1.7060000896453857
消耗的时间为: 1.7139999866485596
消耗的时间为: 1.7350001335144043
消耗的时间为: 1.748000144958496
参考链接
https://www.yuque.com/u21581529/lsww17/ay480d
如果你也喜欢编程,想通过学习Python获取更高薪资,这里给大家分享一份Python学习资料。
😝朋友们如果有需要的话,可以V扫描下方二维码免费领取🆓
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
 #### **一、Python学习路线**
#### **一、Python学习路线**


二、Python基础学习
1. 开发工具

2. 学习笔记

3. 学习视频

三、Python小白必备手册

四、数据分析全套资源

五、Python面试集锦
1. 面试资料


2. 简历模板

** 因篇幅有限,仅展示部分资料,添加上方即可获取**

















 1657
1657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









