



 文章介绍了一个Python脚本,用于在Windows环境中批量替换文本文件中的特定内容,解决了在Linux上可用的sed命令在Windows上不适用的问题。脚本包含data_preprocess()、backup()和sed()三个主要函数,分别处理参数、文件备份和实际的文本替换操作。该脚本提高了在Windows系统中批量修改配置文件的效率,并提供了安全的文件备份机制。
文章介绍了一个Python脚本,用于在Windows环境中批量替换文本文件中的特定内容,解决了在Linux上可用的sed命令在Windows上不适用的问题。脚本包含data_preprocess()、backup()和sed()三个主要函数,分别处理参数、文件备份和实际的文本替换操作。该脚本提高了在Windows系统中批量修改配置文件的效率,并提供了安全的文件备份机制。
哈喽大家好,今天给大家分享一个能够提升运维效率的 python 脚本
平常在工作当中通常会接触到下面类似的场景:
- 容灾切换的时候批量对机器上的配置文件内容进行修改替换
- 对机器批量替换某个文件中的字段
对于 Linux 机器,可以写个 shell 脚本或者直接批量使用 sed 命令就能很好的解决
但对于 Windows 机器,上面的方法就不管用了,我们就需要想其他的办法
这里给大家分享一个由 python 编写的脚本,这个脚本能够去替换指定文本文件中的指定内容,而且还能一次替换多个内容
我们先看效果,目标文件:name.txt
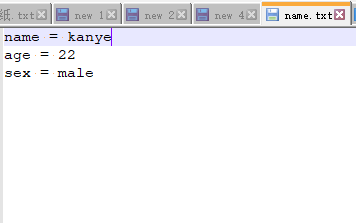
- 修改一个内容
python sed.py c:\name.txt Kanye Edison
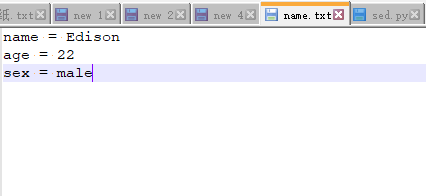
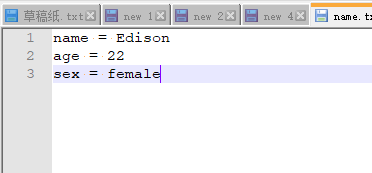
- 修改多个内容
python sed.py c:\name.txt Kanye,male Edison,female
源码在文末哦
首先我们导入模块
import sys
import os
import time
from shutil import copy
然后我们来看一下脚本中的第一个函数——data_preprocess()
def data_preprocess():
file_name, old_str, new_str = sys.argv[1:4] #接收输入的参数:目标文件名,旧内容、新内容、字符编码
try: # 传入字符编码参数
encoding = sys.argv[4]
except IndexError: # 没有传入字符编码参数的话就默认使用 'utf-8' 字符编码
encoding = 'utf-8'
old_str_list = [i.encode(encoding) for i in old_str.split(',')] # 将旧内容转换成列表形式
new_str_list = [i.encode(encoding) for i in new_str.split(',')] # 将新内容转换成列表形式
assert len(old_str_list) == len(new_str_list) # 判断用户输入的 old_str 和 new_str 是不是一一对应
trans_tabs = list(zip(old_str_list, new_str_list)) # 将要旧内容列表(old_str_list)和新内容列表( new_str_list)中的元素一一对应
return file_name, trans_tabs # 返回目标文件名,以及一个旧内容元素和新内容元素一一对应的列表
这个函数实现的功能是接收输入的参数(目标文件名、要替换的内容,替换的内容、字符编码格式),然后将要替换的内容与替换的内容分别转换成列表形式
注意:替换多个内容时在多个内容之间用逗号隔开
例如我们敲如下命令替换一个内容:
python sed.py c:\test.txt Edison Kanye
这个函数就会返回下面内容(由于命令里没有传入字符编码参数,采取默认的 UTF-8)
file_name = c:\test.txt
trans_tabs = [(Edsion, Kanye)]
如果我们需要替换多个内容(例如将首字母改成大写)
python sed.py c:\test.txt edsion,kanye,fish Edsion,Kanye,Fish utf-8
这个函数就会返回下面内容(命令传入了字符编码参数)
file_name = c:\test.txt
trans_tabs = [(edsion, Edsion), (kanye,Kanye), (fish,Fish)]
接下来我们来看第二个函数—— backup()
def backup(file_name):
time_mark = time.strftime('%Y%m%d_%H%M%S') #时间戳
bak_dir = r'C:\Users\Administrator\Desktop' #备份路径
basename = os.path.basename(file_name)
os.makedirs(bak_dir) if not os.path.isdir(bak_dir) else True
copy(file_name, os.path.join(bak_dir, basename + '_' + time_mark))
print("备份 %s 成功" %file_name)
这个函数的功能就是在修改文件之前先把文件备份,防止后期我们需要回滚复原
最后我们来看最后一个函数—— sed()
这个函数便是整个脚本的核心,它负责去执行修改替换文件内容的操作
def sed(file_name, trans_tabs):
with open(file_name + '.swap', 'wb') as swap_fs, open(file_name, 'rb') as file_names: #打开一个临时文件和目标文件
for line in file_names: # 逐行读取
for tab in trans_tabs:
line = line.replace(tab[0], tab[1]) if tab[0] in line else line # 修改替换操作
swap_fs.write(line) # 将修改后的内容写入到临时文件当中
os.remove(file_name) # 删除旧目标文件
os.rename(file_name + '.swap', file_name) # 将临时文件重命名,就变成了新的目标文件
首先先打开一个临时文件(file_name.swap)和目标文件(file_name)
然后对目标文件(file_name)进行逐行读取到内存上,再去对内容进行修改,最后将修改后的内容写入到这个临时文件(file_name.swap)中
修改完毕之后,把临时文件重命名一下、把旧目标文件删掉,这个临时文件就变成了修改内容后的目标文件了
import sys
import os
import time
from shutil import copy
def data_preprocess():
file_name, old_str, new_str = sys.argv[1:4]
try:
encoding = sys.argv[4]
except IndexError:
encoding = 'utf-8'
old_str_list = [i.encode(encoding) for i in old_str.split(',')]
new_str_list = [i.encode(encoding) for i in new_str.split(',')]
assert len(old_str_list) == len(new_str_list)
trans_tabs = list(zip(old_str_list, new_str_list))
return file_name, trans_tabs
def backup(file_name):
time_mark = time.strftime('%Y%m%d_%H%M%S')
bak_dir = r'C:\Users\Administrator\Desktop'
basename = os.path.basename(file_name)
os.makedirs(bak_dir) if not os.path.isdir(bak_dir) else True
copy(file_name, os.path.join(bak_dir, basename + '_' + time_mark))
print("备份 %s" %file_name)
def sed(file_name, trans_tabs):
with open(file_name + '.swap', 'wb') as swap_fs, open(file_name, 'rb') as file_names:
for line in file_names:
for tab in trans_tabs:
line = line.replace(tab[0], tab[1]) if tab[0] in line else line
swap_fs.write(line)
os.remove(file_name)
os.rename(file_name + '.swap', file_name)
file_name, trans_tabs = data_preprocess()
backup(file_name)
sed(file_name, trans_tabs)
好了,今天的分享就到这里!如果你对Python感兴趣,想要学习pyhton,这里给大家分享一份Python全套学习资料,里面的内容都是适合零基础小白的笔记和资料,超多实战案例,不懂编程也能听懂、看懂。
如果你也喜欢编程,想通过学习Python获取更高薪资,这里给大家分享一份Python学习资料。
优快云大礼包:全网最全《全套Python学习资料》免费分享🎁
如果你也喜欢编程,想通过学习Python获取更高薪资,这里给大家分享一份Python学习资料。
😝朋友们如果有需要的话,可以V扫描下方二维码免费领取🆓
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!

一、Python学习路线


二、Python基础学习
1. 开发工具

2. 学习笔记

3. 学习视频

三、Python小白必备手册

四、数据分析全套资源

五、Python面试集锦
1. 面试资料


2. 简历模板

因篇幅有限,仅展示部分资料,添加上方即可获取

















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









