



前言
在学习WebUI和ComfyUI起步前,SD各种模型的类别区分及它们的关系、用法总是令我迷惑。最近尝试不同版本的ComfyUI整合包——官方版、LibLibAI版、秋葉版——又遇到了明明是同类模型但配置路径完全不同的情况。
而且,LibLibAI桌面版模型目录密密麻麻的文件夹,以及部署ComfyUI的extra_model_paths.yaml时又会发现有checkpoint/ vae/ upscale/ embedding/ hypernetwork/ controlnet/ lora等等“乱花渐欲迷人眼”,搞不清它们之间的区别、关系、安装路径。就本人学习习惯,搞不清核心原理,就很难对ComfyUI做到快速上手和熟练掌握,更多只是照猫画虎。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~

题外话:
三个版本的整合包主要区别在于:
官方版:原汁原味,源文件比较小,只有100+MB;安装之后需要自行解决网络问题,并且缺少常用的插件和模型都需要额外下载。
LibLibAI版:和WebUI一并整合,不需要发愁网络问题和重复模型的配置问题,从LibLib上下载模型或者工作流(LibLib上的原图貌似不包含workflow,建议下载.json脚本)也会变得简单;自带图库可以方便查询两个UI的输出,统一管理。但是我的版本始终出现丢失节点在Manager里修复失败的问题,还有很多报错不明所以。很多模型也都是收费会员才能下载,自己找来配置也是一遍麻烦。再者,很多教程也都是以秋葉版为基准讲解,虽然整体差别不大。
秋葉版:整合了Manager管理器和常用插件,内嵌了git镜像网络,即使不用steam++也能快速下载更新模型。之前出现的丢失节点修复失败问题,这里可以得到解决(可能是因为我还不会配置 )。缺点是,下载之后需要手动修改模型部署路径(很简单的),有两个长得一样的客户端需要注意区分,输出结果不能统一管理。
)。缺点是,下载之后需要手动修改模型部署路径(很简单的),有两个长得一样的客户端需要注意区分,输出结果不能统一管理。
如需要相关文件,可点击阅读原文。更多的区别留待后续挖掘。

所以,最近看了很多相关的视频、文章学习其中的逻辑关系,现将其整理如下。这部分将分为两个部分进行梳理,今天先进行底层逻辑的梳理。
注意:这里的梳理只是知晓原理而非搞懂算法,只是为了后半部分区分模型类别做铺垫的,内容虽然枯燥晦涩,但是感觉还是挺重要的。
核心原理推荐学习秋葉大佬的《深入理解Stable Diffusion!从原理到模型训练》。视频前半部分主要讲SD模型基础架构原理及快速解析,后半部分是生图的流程。个人觉得这对后续总结SD模型类别、功能、相互作用机理很有帮助。结合搜索引擎,可以大致梳理出Stable diffusion的核心知识点。
- Latent Diffusion Models(LDM)
首先,Latent Diffusion Models(LDM,潜在扩散模型)是SD的前身,它提出了机器学习模型基础结构。这是一类基于深度学习的生成模型,结合了扩散模型(Diffusion Models)和潜变量模型(Latent Variable Models)的优点。LDM的主要特点是通过在低维潜空间中执行扩散过程来生成数据,而不是直接在高维观测空间(如原始图像像素空间)中操作。这种方法不仅提高了计算效率,还增强了模型的表现力。
LDM架构组成
包括:Pixel Space(像素空间)、Latent Space(潜空间)、Conditioning(条件)。
包括常用语义图谱(Semantic Map)、文本(Text)、数据表示(Representations)、图像(Images)等类型。
其中,Semantic Map(语义图) 是一种表示空间布局和其中物体或区域语义信息的数据结构,广泛应用于计算机视觉、机器人学、自动驾驶等领域。它不仅仅是对环境的几何描述,更重要的是包含了环境中每个部分的功能或类别标签,从而为理解场景提供了更深层次的信息。
数据表示(Representations)指编码器产生的潜空间内的数据表示,即从高维原始数据(如图像)经过编码器压缩后得到的低维潜变量。这些潜变量构成了所谓的“潜空间”,其中每个点对应于一个可能的数据实例(如一张特定的图像)。这种表示方式不仅减少了维度,还使得数据结构更加紧凑,并且保留了重要的语义信息,便于后续任务如生成、分类等。
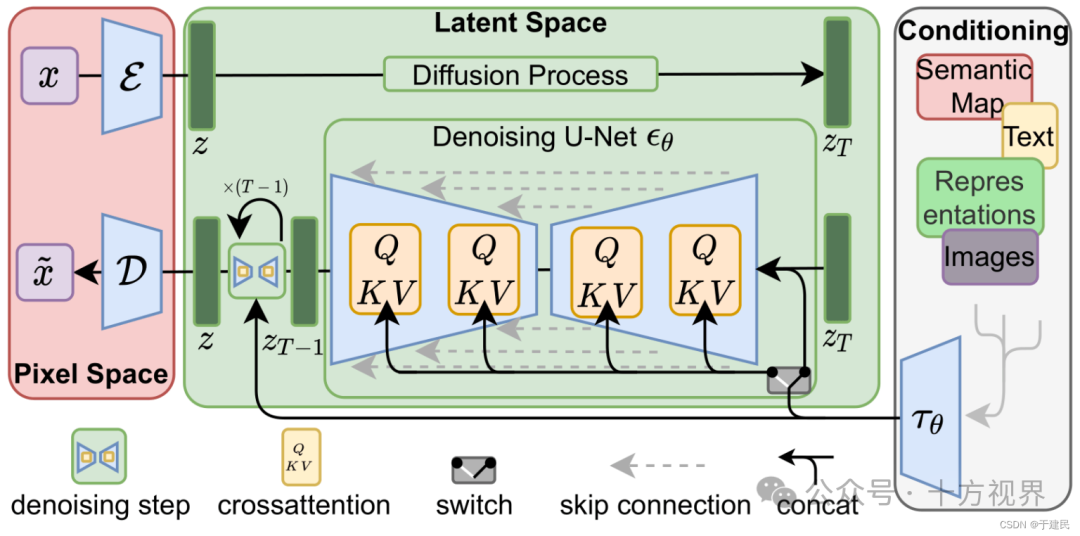
是一个数学构造的空间,其中每个点代表一个可能的数据实例的紧凑表示。在LDM中,这个空间是通过变分自编码器(VAE)或其他类似的编码解码架构构建的。当一个图像被输入到LDM时,它首先被编码成这个潜空间中的一个点(即一个向量),然后所有后续的操作(比如去噪过程)都在这个较低维度的潜空间中进行。
Latent Variables(潜变量)
是指那些不直接观察到但被认为是影响观测数据生成的因素。在LDM上下文中,它们是通过编码器将高维图像转换得到的低维向量。这些潜变量捕捉了输入图像的关键特征和结构信息,但以一种更紧凑、更易于处理的形式存在。
Denoising U-Net(U-Net架构去噪网络)
是指以U-Net为架构的去噪网络,用于从噪声中恢复图像。更多细节可以检索超分放大相关内容。
QKV(Query查询向量、Key键向量、Value值向量)
Q:表示当前位置需要关注的信息。每个注意力头都会根据输入序列生成自己的查询向量。Q向量用于与K向量进行相似度计算,已确定哪些值(V)应该被关注。
K:代表输入序列中每个元素的特征。每一个输入元素都有一个对应的K向量,Q与K的相似度决定了该元素对当前查询的重要性。
V:表示其他位置的实际内容。值向量用于生成最终的输出,根据查询向量和键向量的相似度加权求和V向量得到的,其中权重由Q和K的相似度决定。
Corss-Attention(交叉注意力层)
是一种注意力机制,用于处理两个不同序列之间的依赖关系。它允许一个序列通过注意力机制关注另一个序列,从而捕获两个序列之间的关系。这种机制在多模态任务(如图像和文本匹配)或序列到序列任务(如机器翻译)中应用广泛。
是指图像或视频中每个像素点所构成的空间,它是数字图像处理和计算机视觉中最基础且直观的数据表示形式。在这个空间里,每个像素都对应于图像中的一个特定位置,并携带有关该位置颜色和亮度的信息。理解像素空间对于从事图像处理、分析和生成任务至关重要。
对于高清图像,像素空间的维度非常高(例如,1080p图像有大约2百万个像素),这使得直接在像素空间中进行复杂的变换或生成运算难度较高。直接在像素空间中进行插值、属性编辑等操作,往往还会导致不自然的结果,因为这些操作没有考虑到图像内部的结构和关系。
- LDM生图过程
文本编码(Text Encoding)
用户提供一个文本提示,如“一只蓝色的猫坐在红色沙发上”。
使用预训练的语言模型(例如CLIP中的文本编码器)将文本转换为高维向量表示。这个向量捕捉了文本描述的关键特征,并作为后续生成过程的条件输入。
噪声初始化(Noise Initialization)
在潜空间中随机生成一个噪声向量。这个噪声向量是生成过程的起点,代表了完全随机的状态。
扩散过程(Diffusion Process, 前向过程)
扩散模型通过一系列步骤逐步向噪声中添加更多结构化信息。这个过程可以理解为从纯噪声逐渐演化到与目标分布相似的过程。
每一步都使用UNet架构的神经网络来预测当前状态下的噪声成分,并根据这些预测调整潜变量。这一系列的去噪步骤被称为反向扩散过程或生成过程。
条件引导(Conditional Guidance)
在每个去噪步骤中,利用文本编码的结果作为条件,指导UNet更好地理解应该生成什么样的图像。这确保了生成的图像不仅符合一般的统计特性,还能具体反映给定的文本描述。
解码回像素空间(Decoding to Pixel Space)
当扩散过程完成,得到一个在潜空间中的表示后,使用变分自编码器(VAE)的解码部分将这个低维表示映射回高维的像素空间。
VAE的解码器负责将紧凑的潜变量扩展成完整的图像,恢复出所有细节和颜色信息。
Decoder 解码模型只会运行一次,将潜空间的图(4*64*64)转化为人眼能够欣赏的 RGB 图像(512*512)(这里默认生成一张512*512大小的图)。
扩展:
扩散模型的计算量较大,原因之一就在于图像本身过大。比如一张 512*512 的图片,访问一遍完整的图片(包括 RGB)需要约78万的计算/访问次数,SD 模型可以将图像压缩在潜空间(latent space)中(4*64*64),相比于原空间,小了48倍,所以 SD 模型的计算速度可以提升许多。
最终输出(Final Output)
经过解码后的图像即为根据用户提供的文本提示生成的新图像。该图像应该尽量贴近原始文本描述的内容,同时具有自然、逼真的视觉效果。
3.LDM模型关键组件
3.1 Diffusion Model(扩散模型)
这是SD的核心,负责图像的实际生成。扩散模型通过一个前向过程将输入图像逐渐添加噪声,然后训练一个逆过程来学习去除这些噪声,最终可以从纯噪声中生成新的图像。
3.2 U-Net网络
核心网络架构,用于执行反向扩散过程中每一步的去噪任务。它接收带有噪声的图像和时间步长作为输入,并输出预测的噪声成分。这个预测随后被用来重建更清晰的图像。
Noise Predictor(噪声预测器)
主要任务是在生成过程中估计每个时间步长的噪声成分。具体来说,在反向扩散(去噪)过程中,噪声预测器接收带有噪声的数据点,并尝试预测出这个数据点中添加了多少噪声。这一预测随后被用来逐步减少噪声,最终恢复出原始的、清晰的数据表示。
噪声预测器的工作原理
前向扩散(Forward diffusion)
前向扩散就是将高斯噪声加入到用来训练的图像中,让它的图像特征逐渐减弱,分布更加符合高斯分布。图像的有序性和规律性会随着噪声的不断增加而越来越弱。
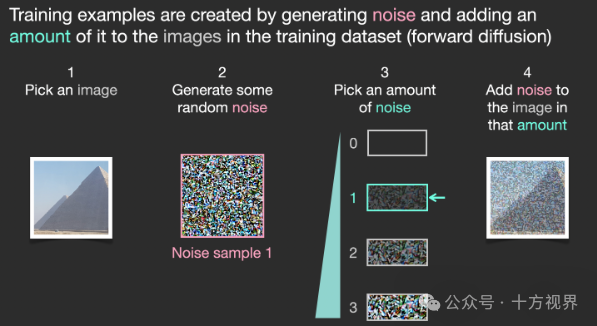
u在训练阶段,模型首先执行一个前向扩散过程,该过程逐渐向数据(例如图像)中添加噪声,直到它变得几乎完全随机。这个过程可以看作是将数据分布转换为简单的先验分布(如高斯分布)。
u每个时间步 t 添加的噪声量由一个预定义的噪声调度函数控制,确保噪声逐渐增加。
训练噪声预测器
u对于每一个时间步 t,从已经添加了噪声的数据中采样,然后训练一个神经网络(通常是UNet架构)来学习预测这个时间步上添加的具体噪声。
u目标是最小化预测噪声与实际添加噪声之间的差异,这通常通过均方误差(MSE)损失函数实现。
反向扩散 (Reverse diffusion)
反向扩散的前提是一张完全随机的高斯噪声,而为了最终能够得到一张我们想要的图片,我们需要知道图像中添加了多少的噪声。这就是扩散模型的关键所在:噪声预测器 noise predictor。科学家和工程师们使用大量的图片和数据来训练这样一个噪声预测器,最终得到一个能够预测噪音的工具。
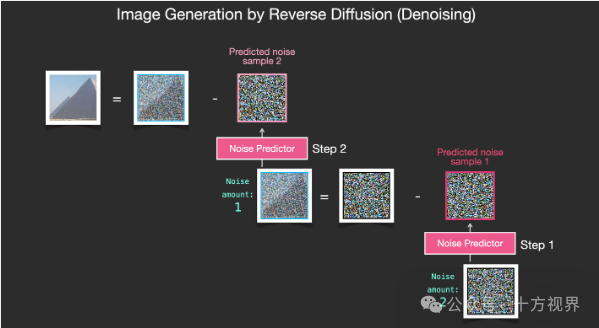
u在生成或推理阶段,从纯噪声开始,使用训练好的噪声预测器逐步去除噪声。在每个时间步 t,噪声预测器接收当前带噪声的数据和时间步信息作为输入,输出预测的噪声。
u然后,根据这个预测调整数据,以减少其中的噪声,逐步逼近原始数据的分布。
迭代去噪
这个去噪过程是迭代进行的,每次迭代都会稍微减少一些噪声,直到最终生成一个接近无噪声的样本。
3.3 VAE(Variantional Autoencoder,变分自编码器)
负责编码和解码图像。编码器将输入图像压缩到较低维度的潜空间表示,而解码器则将潜变量还原为高分辨率图像。VAE 在图像生成时接近“滤镜”的效果,在效果层面作用不如Lora,而在原理上,VAE 就重要的多,它是 SD 可以将模型转化到潜空间的保障。
3.4 CLIP(Contrastive Language-Image Pretraining对比语言-图像预训练)
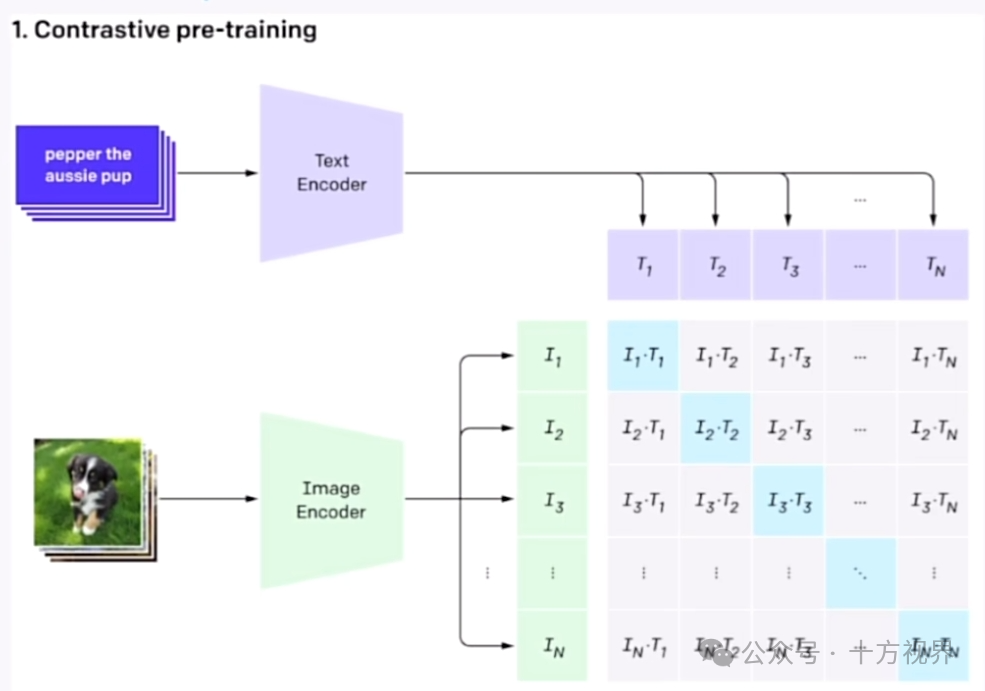
CLIP接受文本提示并与图像进行对比学习,从而可以理解文本和图像之间的关系。简单讲,是将文本提示转换为能够指导生成过程的向量表示,保证生成内容与描述相符。在 Clip 模型中,将每一个提示词固定在一个嵌入向量里。最后在文本转换器(Text transformer)内进一步处理嵌入,最后作为条件影响 noise perdictor(噪声预测器)。
Text Encoder(文本编码器)
通常使用预训练的语言模型(如OpenAI的CLIP文本编码部分或其它相似模型),将文本提示转换为向量形式,使得扩散模型能够理解并依据这些提示来调整图像生成的方向。即把提示词(prompt)转化成计算机能够理解的一种数学表示。输入的提示词最终能够生成图像,肯定离不开AI对提示词的“理解”,而 Clip 就是一种能够支持多模态输入的语言模型。
Clip的机制是先输入一个词语例如1girl,然后这个词会经过Tokenize得到一组数字。
Tokenize(标记化)
Token很好理解就是我们常用的令牌/标记。Tokenize也就是令牌化/标记化,是指将文本数据分割成一个个的令牌/标记(tokens)的过程。这些令牌可以是关键字、变量名、字符串、直接量和大括号等语法标点。Tokenize的过程通常涉及将文本分解为更小的单元,以便于后续的处理和分析。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









