




 本文详细介绍了PostgreSQL中的窗口函数,包括其定义、使用OVER子句中的分区、排序和窗口选项,以及举例说明了聚合函数、排名和累计销量的计算。
本文详细介绍了PostgreSQL中的窗口函数,包括其定义、使用OVER子句中的分区、排序和窗口选项,以及举例说明了聚合函数、排名和累计销量的计算。
窗口函数简介
包括 AVG、COUNT、MAX、MIN、SUM 以及
STRING_AGG。聚合函数的作用是针对一组数据行进行运算,并且返回一条汇总结果
分析的窗口函数(Window Function)。
不过,窗口函数不是将一组数据汇总为单个结果,而是针对每一行数据,基于和它相关的一组数
据计算出一个结果。下图演示了聚合函数和窗口函数的区别
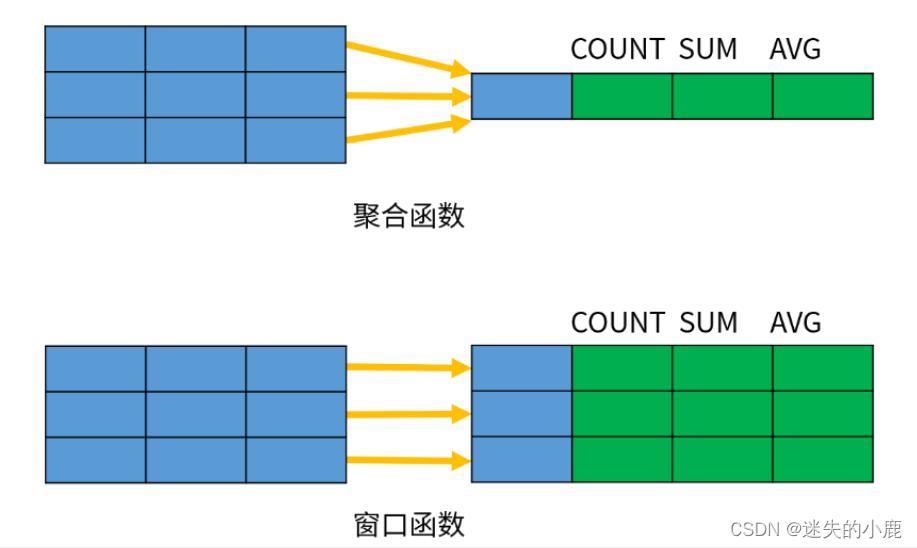
区别在于后者包含了 OVER 关键字;空括号表示将所有数据作为整体进行分析,所以得到的数值和聚合函数一样
窗口函数的定义
window_function ( expression, ... ) OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)
window_function 是窗口函数的名称;expression 是函数参数,有些函数不需要参数;
over 子句包含三个选项:分区(partition by)、排序(order by)以及窗口大小
(frame_clause)
分区
-- 计算员工的部门平均薪水
-- partition by分组统计,和group by 类似
select
e.employee_id ,
e.first_name ,
e.last_name ,
e.salary ,
e.department_id ,
round(avg(e.salary) over(partition by e.department_id),2) as avg_sal
from employees e;
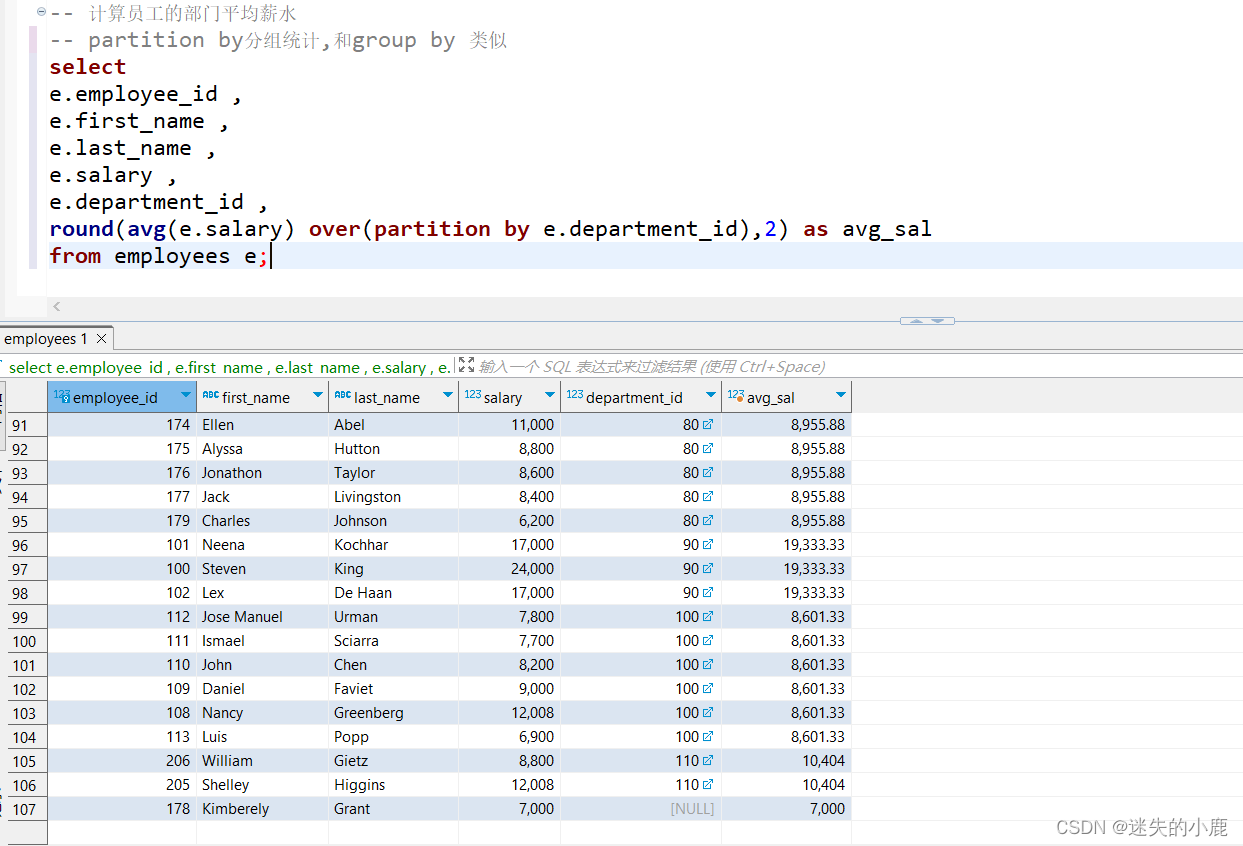
partition by 选项用于定义分区,作用类似于 group by 的分组。如果指定了分区选项,
窗口函数将会分别针对每个分区单独进行分析;如果省略分区选项,所有的数据作为一个整体进
行分析
排序选项
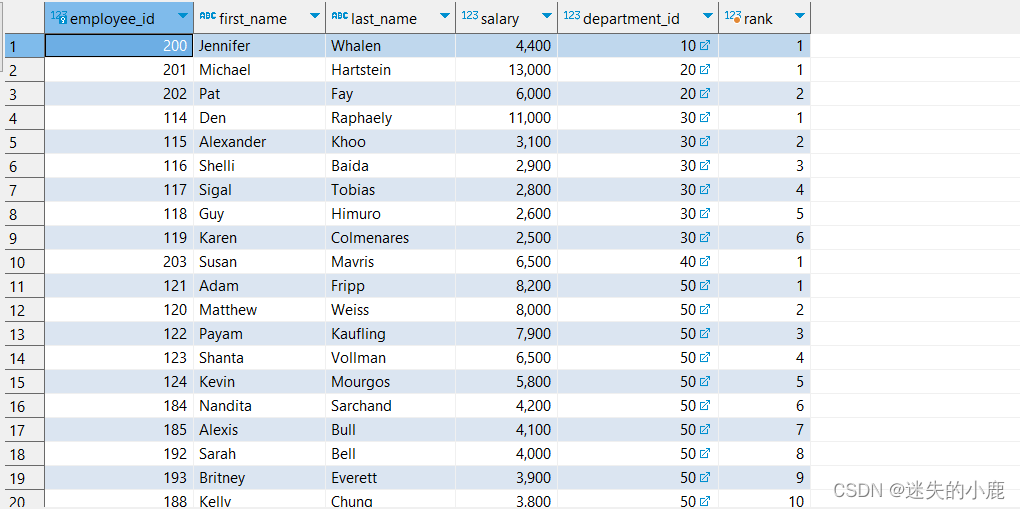
order by 选项用于指定分区内的排序方式,通常用于数据的排名分析
-- 员工在部门内薪水排名
select
e.employee_id ,
e.first_name ,
e.last_name,
e.salary ,
e.department_id ,
rank() over(partition by e.department_id order by e.salary desc)
from employees e;
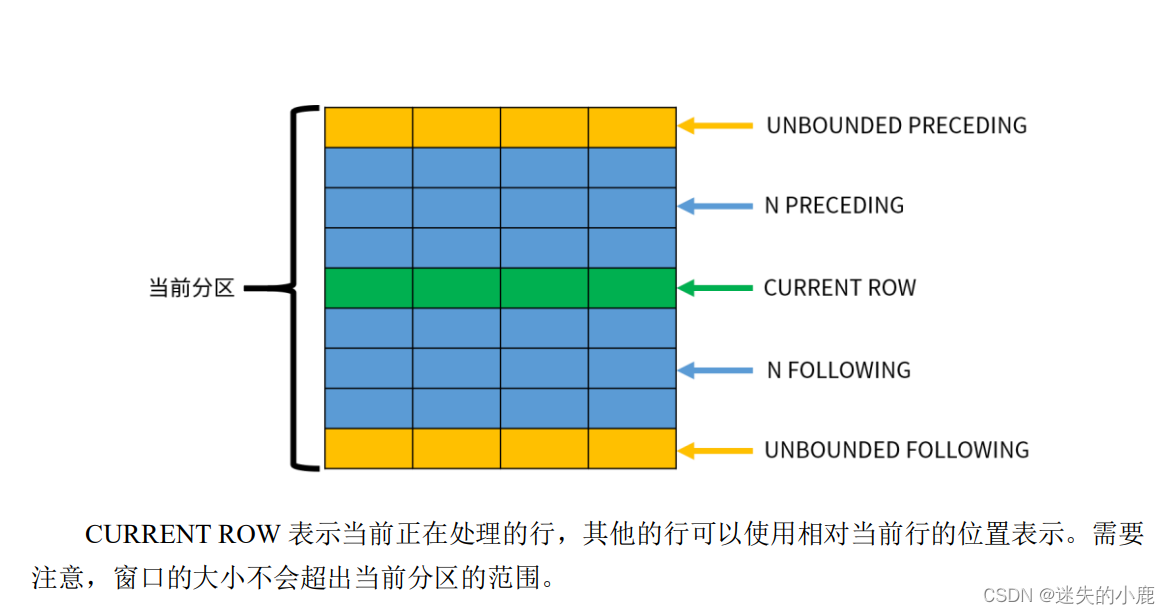
窗口选项
frame_clause 选项用于在当前分区内指定一个计算窗口。指定了窗口之后,分析函数不再基
于分区进行计算,而是基于窗口内的数据进行计算
-- public.sales_monthly definition
-- Drop table
-- DROP TABLE public.sales_monthly;
CREATE TABLE public.sales_monthly (
product varchar(20) NULL,
ym varchar(10) NULL,
amount numeric(10, 2) NULL
);
INSERT INTO public.sales_monthly (product,ym,amount) VALUES
('苹果','201801',10159.00),
('苹果','201802',10211.00),
('苹果','201803',10247.00),
('苹果','201804',10376.00),
('苹果','201805',10400.00),
('苹果','201806',10565.00),
('苹果','201807',10613.00),
('苹果','201808',10696.00),
('苹果','201809',10751.00),
('苹果','201810',10842.00);
INSERT INTO public.sales_monthly (product,ym,amount) VALUES
('苹果','201811',10900.00),
('苹果','201812',10972.00),
('苹果','201901',11155.00),
('苹果','201902',11202.00),
('苹果','201903',11260.00),
('苹果','201904',11341.00),
('苹果','201905',11459.00),
('苹果','201906',11560.00),
('香蕉','201801',10138.00),
('香蕉','201802',10194.00);
INSERT INTO public.sales_monthly (product,ym,amount) VALUES
('香蕉','201803',10328.00),
('香蕉','201804',10322.00),
('香蕉','201805',10481.00),
('香蕉','201806',10502.00),
('香蕉','201807',10589.00),
('香蕉','201808',10681.00),
('香蕉','201809',10798.00),
('香蕉','201810',10829.00),
('香蕉','201811',10913.00),
('香蕉','201812',11056.00);
INSERT INTO public.sales_monthly (product,ym,amount) VALUES
('香蕉','201901',11161.00),
('香蕉','201902',11173.00),
('香蕉','201903',11288.00),
('香蕉','201904',11408.00),
('香蕉','201905',11469.00),
('香蕉','201906',11528.00),
('桔子','201801',10154.00),
('桔子','201802',10183.00),
('桔子','201803',10245.00),
('桔子','201804',10325.00);
INSERT INTO public.sales_monthly (product,ym,amount) VALUES
('桔子','201805',10465.00),
('桔子','201806',10505.00),
('桔子','201807',10578.00),
('桔子','201808',10680.00),
('桔子','201809',10788.00),
('桔子','201810',10838.00),
('桔子','201811',10942.00),
('桔子','201812',10988.00),
('桔子','201901',11099.00),
('桔子','201902',11181.00);
INSERT INTO public.sales_monthly (product,ym,amount) VALUES
('桔子','201903',11302.00),
('桔子','201904',11327.00),
('桔子','201905',11423.00),
('桔子','201906',11524.00);
/*
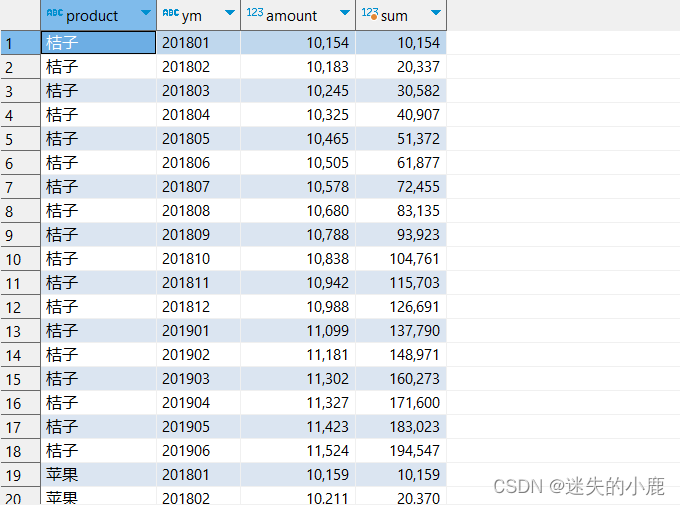
* 计算每个产品当当前月份的累计销量
*/
select
m.product ,
m.ym ,
m.amount,
sum(m.amount) over(partition by m.product
order by m.ym rows between unbounded preceding and current row)
from
sales_monthly m
order by m.product,m.ym;

常见的窗口函数可以分为以下几类:聚合窗口函数、排名窗口函数以及取值窗口函数。
更多的复杂选项可以参考官方文档


















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









