




无监督学习:让机器从“混沌”中自我觉醒 🧠🌌

🧭 摘要:无监督学习(Unsupervised Learning)是机器学习的重要分支,它不依赖于人工标签,通过自身“感知”数据结构来发现潜在模式。本文系统梳理了其核心概念、典型算法、实际应用与代码实战,既适合入门学习,也适用于工程实践与技术面试准备。
1️⃣ 无监督学习是什么?没有“答案”的学习也能开悟!
设想你刚进一家图书馆,看到一大堆没有标签的书籍——没有作者分类、没有题材标识。你会怎么办?大多数人会根据封面、厚度、插图和目录,自行把这些书大致分为“小说”“工具书”“传记”等类型。
这正是无监督学习的核心思想:不需要标签,仅根据样本间的结构关系,让模型自我发现数据分布中的规律。
📌 无监督学习适用于无法获取标注或人工标注成本过高的场景,是AI领域“自动发现知识”的关键支撑。
2️⃣ 无监督 VS 监督学习:核心差异一图看懂 📊
| 特征对比 | 监督学习(Supervised) | 无监督学习(Unsupervised) |
|---|---|---|
| 是否需标签 | ✅ 需要 | ❌ 不需要 |
| 学习目标 | 学习 X ➜ Y 的映射关系 | 挖掘 X 内部的分布和结构 |
| 代表任务 | 分类(Classification)、回归(Regression) | 聚类(Clustering)、降维(Dimensionality Reduction) |
| 示例应用 | 识别猫狗图像、预测房价 | 客户分群、异常检测、推荐系统 |
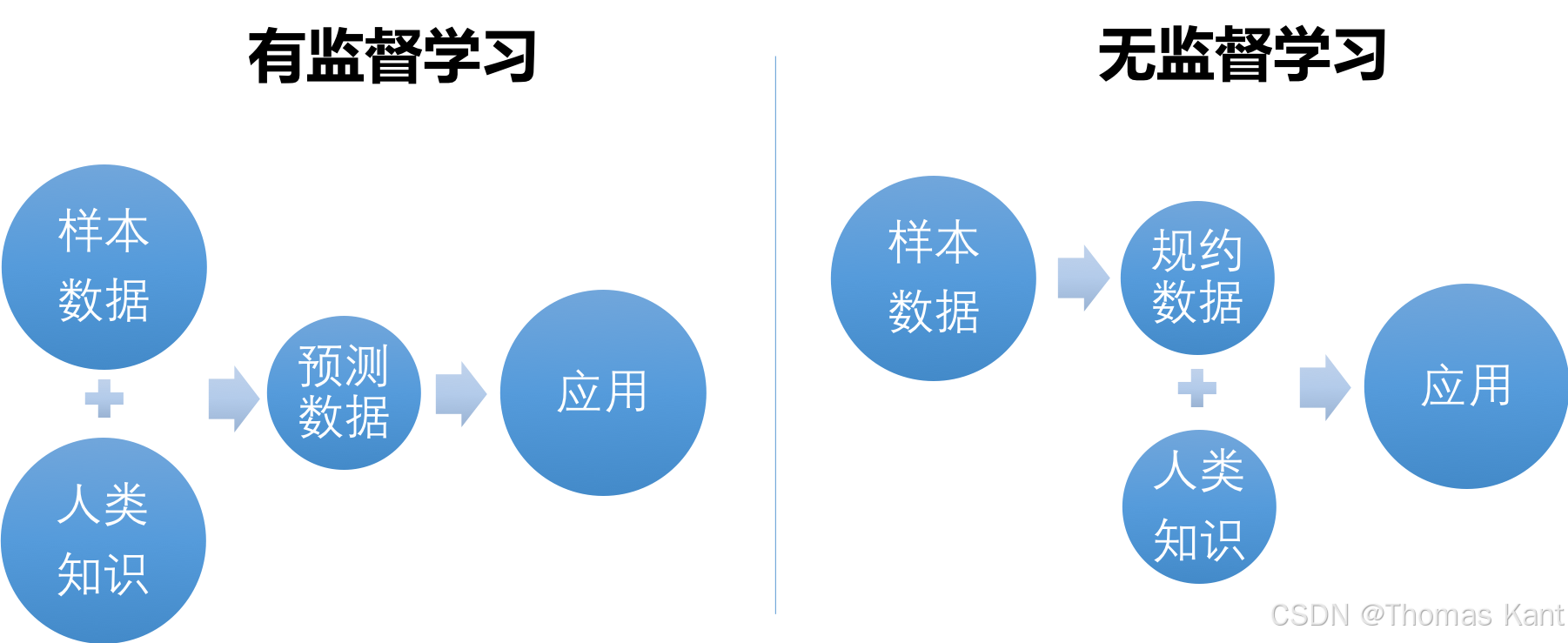
🎯 简而言之:监督学习是“有老师教你考试”,而无监督学习是“自己琢磨出题规律”。
3️⃣ 无监督学习四大核心任务 ✨
3.1 聚类(Clustering):物以类聚,人以群分 👥
📌 目标:将相似样本自动划分到同一类中。
⭐ 代表算法:
- K-Means:基于中心点的迭代聚类,速度快,适用于结构清晰的数据集。
- DBSCAN:基于密度聚类,能识别任意形状簇,抗噪强,适用于复杂数据分布。
- 层次聚类(Hierarchical Clustering):构建聚类树(Dendrogram)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











