




 本文讲述了神州专车订单系统从单数据库架构到分库分表的演进过程,涉及SQL优化、读写分离、业务领域分库、缓存和MQ的使用,以及从SQLServer到MySQL的迁移和自研分库分表组件SDDL的应用。文章详细描述了每个阶段的问题、解决方案及实施步骤,展示了系统架构如何应对业务增长的挑战。
本文讲述了神州专车订单系统从单数据库架构到分库分表的演进过程,涉及SQL优化、读写分离、业务领域分库、缓存和MQ的使用,以及从SQLServer到MySQL的迁移和自研分库分表组件SDDL的应用。文章详细描述了每个阶段的问题、解决方案及实施步骤,展示了系统架构如何应对业务增长的挑战。
神州专车订单研发团队,亲历了专车数据层「架构进化」的过程。这次工作经历对我而言非常有启发性,也让我经常感慨:“好的架构果然是一点点进化来的”。
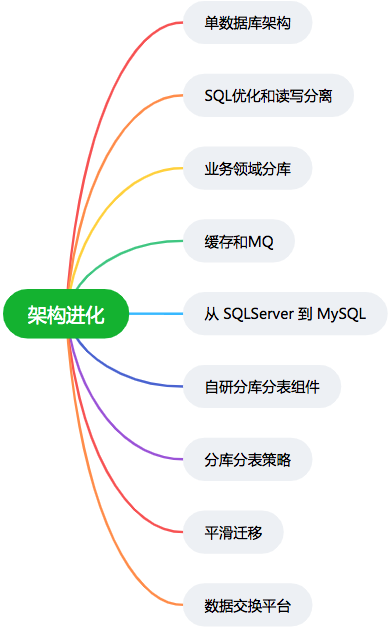
1 单数据库架构
产品初期,技术团队的核心目标是: “快速实现产品需求,尽早对外提供服务” 。
彼时的专车服务都连同一个 SQLServer 数据库,服务层已经按照业务领域做了一定程度的拆分。
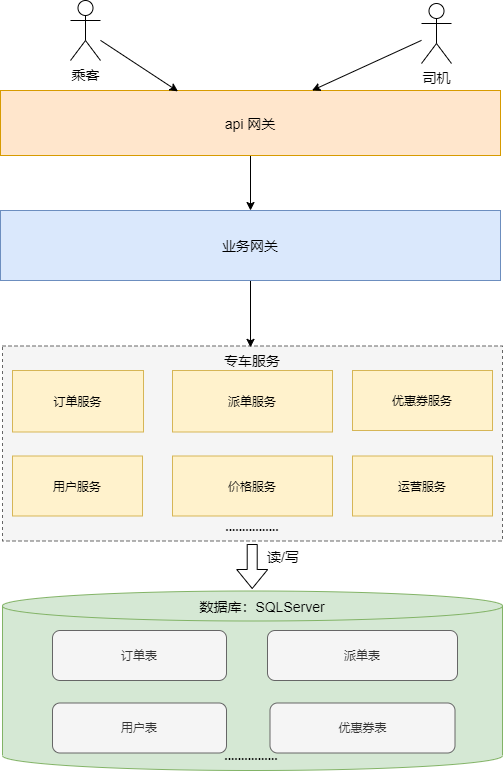
这种架构非常简单,团队可以分开协作,效率也极高。随着专车订单量的不断增长,早晚高峰期,用户需要打车的时候,点击下单后经常无响应。
系统层面来看:
-
数据库瓶颈显现。频繁的磁盘操作导致数据库服务器 IO 消耗增加,同时多表关联,排序,分组,非索引字段条件查询也会让 cpu 飙升,最终都会导致数据库连接数激增;
-
网关大规模超时。在高并发场景下,大量请求直接操作数据库,数据库连接资源不够用,大量请求处于阻塞状态。
2 SQL优化和读写分离
为了缓解主数据库的压力,很容易就想到的策略: SQL优化 。通过性能监控平台和 DBA 同学协作分析出业务慢 SQL ,整理出优化方案:
-
合理添加索引;
-
减少多表 JOIN 关联,通过程序组装,减少数据库读压力;
-
减少大事务,尽快释放数据库连接。
另外一个策略是: 读写分离 。
读写分离的基本原理是让主数据库处理事务性增、改、删操作( INSERT、UPDATE、DELETE),而从数据库处理 SELECT 查询操作。
专车架构团队提供的 框架 中,支持读写分离,于是数据层架构进化为如下图:
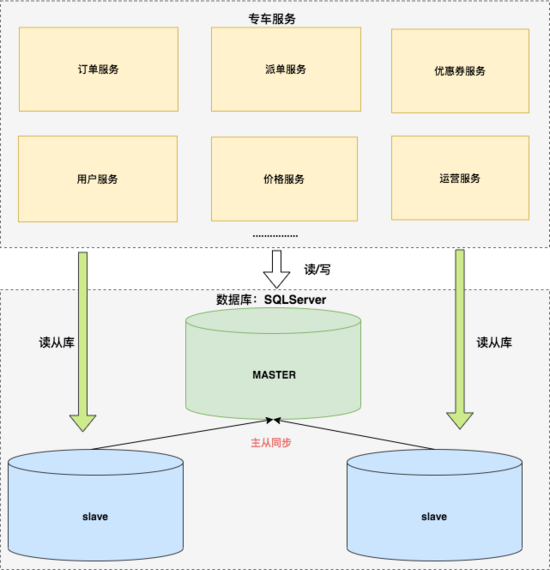
读写分离可以减少主库写压力,同时读从库可水平扩展。当然,读写分离依然有局限性:
-
读写分离可能面临主从延迟的问题,订单服务载客流程中对实时性要求较高,因为担心延迟问题,大量操作依然使用主库查询;
-
读写分离可以缓解读压力,但是写操作的压力随着业务爆发式的增长并没有很有效的缓解。
3 业务领域分库
虽然应用层面做了优化,数据层也做了读写分离,但主库的压力依然很大。接下来,大家不约而同的想到了 业务领域分库 ,也就是:将数据库按业务领域拆分成不同的业务数据库,每个系统仅访问对应业务的数据库。
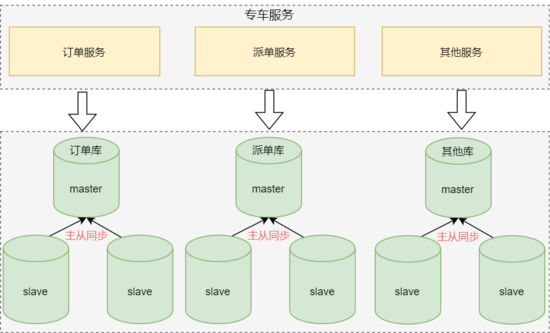
业务领域分库可以缓解核心订单库的性能压力,同时也减少系统间的相互影响,提升了系统整体稳定性。
随之而来的问题是:原来单一数据库时,简单的使用 JOIN 就可以满足需求,但拆分后的业务数据库在不同的实例上,就不能跨库使用 JOIN了,因此需要对 系统边界重新梳理,业务系统也需要重构 。
重构重点包含两个部分:
-
原来需要
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3605
3605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









