







 本文介绍了Java并发编程的基础知识,包括原子性、可见性、有序性,以及内存模型JMM,通过实例解析了volatile、synchronized和内存屏障的作用,帮助理解多线程中的数据一致性问题。
本文介绍了Java并发编程的基础知识,包括原子性、可见性、有序性,以及内存模型JMM,通过实例解析了volatile、synchronized和内存屏障的作用,帮助理解多线程中的数据一致性问题。
“三妹啊,既然放假了,我们就一起来深入学习一下 Java 并发编程吧。”
“并发编程太难了,想想都头大。”三妹很不情愿地说。
“没关系,我们一步步来。”我说,“今天我们先来学习一下Java 并发编程的基础知识,包括原子性、可见性、有序性,以及内存模型 JMM。”
并发编程基本概念
原子性
一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
原子性是拒绝多线程操作的,不论是多核还是单核,具有原子性的量,同一时刻只能有一个线程来对它进行操作。简而言之,在整个操作过程中不会被线程调度器中断的操作,都可认为是原子性。
例如 a=1 是原子性操作,但是 a++和 a +=1 就不是原子性操作。Java 中的原子性操作包括:
-
基本类型的读取和赋值操作,且赋值必须是值赋给变量,变量之间的相互赋值不是原子性操作;
-
所有引用 reference 的赋值操作;
-
java.concurrent.Atomic.* 包中所有类的一切操作。
可见性
指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
在多线程环境下,一个线程对共享变量的操作对其他线程是不可见的。
Java 提供了 volatile 来保证可见性,当一个变量被 volatile 修饰后,表示着线程本地内存无效,当一个线程修改共享变量后他会立即被更新到主内存中,其他线程读取共享变量时,会直接从主内存中读取。
当然,synchronized 和 Lock 都可以保证可见性。synchronized 和 Lock 能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
有序性
即程序执行的顺序按照代码的先后顺序执行。
Java 内存模型中的有序性可以总结为:如果在本线程内观察,所有操作都是有序的;如果在一个线程中观察另一个线程,所有操作都是无序的。前半句是指“线程内表现为串行语义”,后半句是指“指令重排序”现象和“工作内存主主内存同步延迟”现象。
在 Java 内存模型中,为了效率是允许编译器和处理器对指令进行重排序,当然重排序不会影响单线程的运行结果,但是对多线程会有影响。
Java 提供 volatile 来保证一定的有序性。最著名的例子就是单例模式里面的 DCL(双重检查锁)。另外,可以通过 synchronized 和 Lock 来保证有序性,synchronized 和 Lock 保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。
“二哥,感觉理解不是很清楚啊?????”
“为了让你更好理解地可见性和有序性,就不得不了解“内存模型”、“重排序”和“内存屏障”,因为这三个概念和他们关系非常密切。”我说。
内存模型
JMM 决定一个线程对共享变量的写入何时对另一个线程可见,JMM 定义了线程和主内存之间的抽象关系:共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存保存了被该线程使用到的主内存的副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存中的变量。

对于普通的共享变量来讲,线程 A 将其修改为某个值发生在线程 A 的本地内存中,此时还未同步到主内存中去;而线程 B 已经缓存了该变量的旧值,所以就导致了共享变量值的不一致。
解决这种共享变量在多线程模型中的不可见性问题,可以使用 volatile、synchronized、final 等,此时 A、B 的通信过程如下:
-
首先,线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中去;
-
然后,线程 B 到主内存中去读取线程 A 之前已更新过的共享变量。
JMM 通过控制主内存与每个线程的本地内存之间的交互,来为 java 程序员提供内存可见性保证,需要注意的是,JMM 是个抽象的内存模型,所以所谓的本地内存,主内存都是抽象概念,并不一定就真实的对应 cpu 缓存和物理内存。
总结一句话,内存模型 JMM 控制多线程对共享变量的可见性!!!
重排序
重排序是指编译器和处理器为了优化程序性能而对指令序列进行排序的一种手段。
重排序需要遵守一定规则:
-
重排序操作不会对存在数据依赖关系的操作进行重排序。比如:a=1;b=a; 这个指令序列,由于第二个操作依赖于第一个操作,所以在编译时和处理器运行时这两个操作不会被重排序。
-
重排序是为了优化性能,但是不管怎么重排序,单线程下程序的执行结果不能被改变。比如:a=1;b=2;c=a+b 这三个操作,第一步(a=1)和第二步(b=2)由于不存在数据依赖关系, 所以可能会发生重排序,但是 c=a+b 这个操作是不会被重排序的,因为需要保证最终的结果一定是 c=a+b=3。
重排序在单线程下一定能保证结果的正确性,但是在多线程环境下,可能发生重排序,影响结果,请看下面的示例代码:
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
System.out.println(i);
}
}
}
flag 变量是个标记,用来标识变量 a 是否已被写入。这里假设有两个线程 A 和 B,A 首先执行 writer()方法,随后 B 线程接着执行 reader()方法。线程 B 在执行操作 4 时,输出是多少呢?
答案是:可能是 0,也可能是 1。
由于操作 1 和操作 2 没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作 3 和操作 4 没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。让我们先来看看,当操作 1 和操作 2 重排序时,可能会产生什么效果?请看下面的程序执行时序图:

如上图所示,操作 1 和操作 2 做了重排序。程序执行时,线程 A 首先写标记变量 flag,随后线程 B 读这个变量。由于条件判断为真,线程 B 将读取变量 a。此时,变量 a 还根本没有被线程 A 写入,在这里多线程程序的语义被重排序破坏了!最后输出 i 的结果是 0。
这里理解起来有点绕,比如线程 A 先执行了 writer(),然后线程 B 执行 reader(),对于线程 A,怎么会有这个重排序呢?其实这个重排序,是对线程 B 而言的,不是线程 A 哈!
有了线程 B 这第一视角,我们再理解一下,虽然线程 A 将 writer()执行了,执行顺序是 a=1,flag=true,但是对于线程 B 来说,因为重排序,线程 B 是根据重排序后的结果去执行的,所以才会出现上述异常情况,这么给你解释,是不是就清晰很多呢?
下面再让我们看看,当操作 3 和操作 4 重排序时会产生什么效果(借助这个重排序,可以顺便说明控制依赖性)。下面是操作 3 和操作 4 重排序后,程序的执行时序图:

在程序中,操作 3 和操作 4 存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。
以处理器的猜测执行为例,执行线程 B 的处理器可以提前读取并计算 a*a,此时结果为 0,然后把计算结果临时保存到一个名为重排序缓冲(reorder buffer ROB)的硬件缓存中。当接下来操作 3 的条件判断为真时,就把该计算结果写入变量 i 中。
从图中我们可以看出,猜测执行实质上对操作 3 和 4 做了重排序。重排序在这里破坏了多线程程序的语义!因为 temp 的值为 0,所以最后输出 i 的结果是 0。
“那如何避免重排序对多线程的影响呢?”三妹及时抓住了问题的核心。
答案是“内存屏障”!
内存屏障
为了保证内存可见性,可以通过 volatile、final 等修饰变量,java 编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。内存屏障主要有 3 个功能:
-
它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
-
它会强制将对缓存的修改操作立即写入主存;
-
如果是写操作,它会导致其他 CPU 中对应的缓存行无效。
假如我对上述示例的 falg 变量通过 volatile 修饰:
class ReorderExample {
int a = 0;
boolean volatile flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
System.out.println(i);
}
}
}
这个时候,volatile 禁止指令重排序也有一些规则,比如 happens before 规则,这个过程建立的 happens before 关系可以分为两类:
-
根据程序次序规则,1 happens before 2; 3 happens before 4。
-
根据 volatile 规则,2 happens before 3。
-
根据 happens before 的传递性规则,1 happens before 4。
happens before 规则,其实就是重排序规则建立的代码前后依赖关系。
“1、3 的规则我理解,但是对于 2,为什么‘2 happens before 3’?”三妹问。
因为我们对变量 flag 指定了 volatile,所以当线程 A 执行完后,变量 flag=true 会直接刷到内存中,然后 B 马上可见,所以说 2 一定是在 3 前面,不可能因为重排序,导致 3 在 2 前面执行。
注意,这里执行时有个前提条件,就是线程 A 执行完,才能执行线程 B 里面的逻辑,因为线程 A 不执行完,flag 一直是 false,线程 B 根本就进不到主流程,所以你也可以直接理解为线程 A 执行完后,再执行线程 B,才有这么个先后关系。
上述 happens before 关系的图形化表现形式如下:
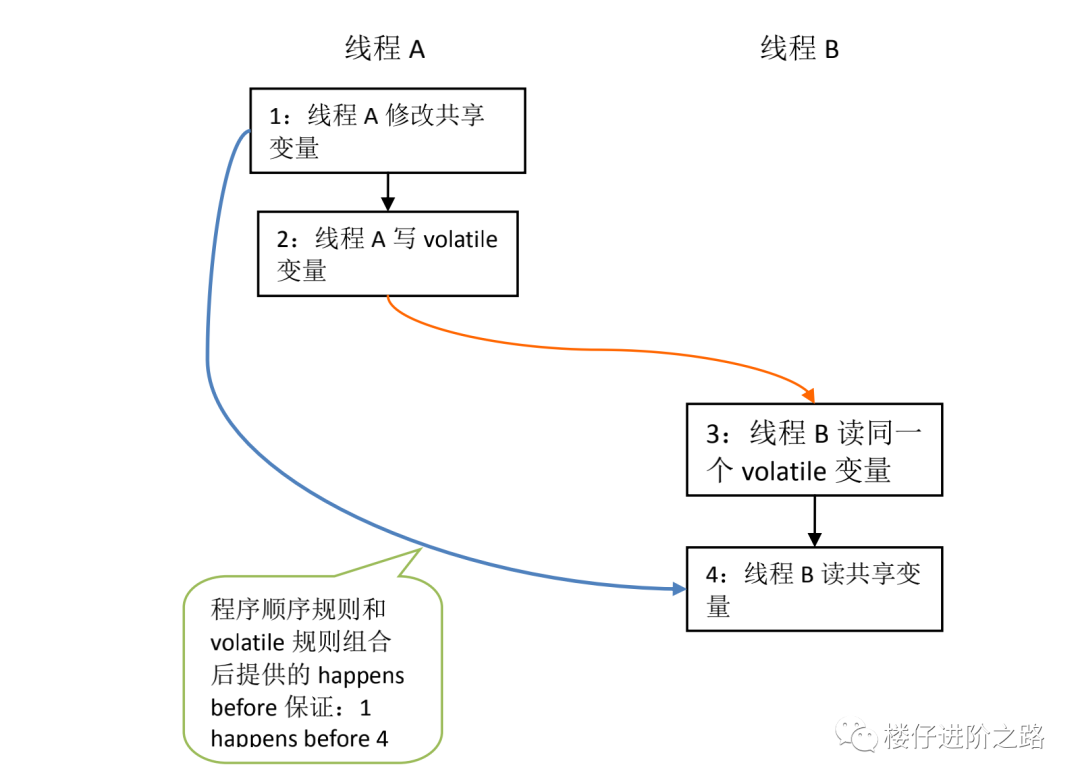
在上图中,每一个箭头链接的两个节点,代表了一个 happens before 关系。黑色箭头表示程序顺序规则;橙色箭头表示 volatile 规则;蓝色箭头表示组合这些规则后提供的 happens before 保证。
这里 A 线程写一个 volatile 变量后,B 线程读同一个 volatile 变量。A 线程在写 volatile 变量之前所有可见的共享变量,在 B 线程读同一个 volatile 变量后,将立即变得对 B 线程可见。
总结
“好了,三妹,今天就先讲到这里吧。”
今天讲解了 Java 并发编程的 3 个特性,然后基于里面的两个特性“可见性”和“有序性”引出几个重要的概念,分别为“内存模型 JMM”、“重排序”和“内存屏障”,这个对后续理解 volatile、synchronized、final,以及避免使用的各种坑,真的是非常非常重要!!!所以这块知识要必须!一定!!要!!!掌握。

















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









