




1、服务导出
主要依赖两个监听器来完成:
DubboConfigApplicationListener — 初始化
DubboDeployApplicationListener —服务导出
DubboConfigApplicationListener会根据回调事件通知执行DefaultApplicationDeployer#initialize来进行初始化。
public class DefaultApplicationDeployer extends AbstractDeployer<ApplicationModel> implements ApplicationDeployer {
@Override
public void initialize() {
if (initialized) {
return;
}
// Ensure that the initialization is completed when concurrent calls
synchronized (startLock) {
if (initialized) {
return;
}
// 注册关闭钩子,优雅下线
registerShutdownHook();
// 获取应用名,设置ApplicationModel.modelName
// 加载配置中心,如果没有配置,用注册中心作为配置中心
// 比如:configManager.getConfigCenter("config-center-zookeeper-127.0.0.1-2181").get()
// 同时去配置中心获取配置,进行载人。Fetch config from remote config center
startConfigCenter();
// 加载各类配置文件,生成ApplicationConfig,RegistryConfig,ProtocolConfig等
loadApplicationConfigs();
// 主要调用DefaultModuleDeployer.initialize 初始化默认模块,dubbo3新增scope模块隔离,使得一个jvm可以发多个dubbo应用,且可以根据环境隔离
initModuleDeployers();
// @since 2.7.8
// 如果没有指定metadata元数据中心,用注册中心地址作为元数据中心地址
// 将获取的元数据中心,利用lock线程安全的方式创建对应的实例,可能是为了避免并行创建了多个。
// 比如用zk做元数据中心,new ZookeeperMetadataReport(url, zookeeperTransporter)
startMetadataCenter();
// 初始化完毕
initialized = true;
if (logger.isInfoEnabled()) {
logger.info(getIdentifier() + " has been initialized!");
}
}
}
}
DubboDeployApplicationListener会根据回调事件通知,开始服务的导出工作,不过主要的导出工作,是由DefaultModuleDeployer来完成的。
关于应用级注册:
如果配置了dubbo.application.registry-mode=instance,默认all,会把原来的registry//127.0.0.1:2181前缀改为service-discovery-registry,同时创建ZookeeperServiceDiscovery作为注册中心的实现。如果是配置的interface,则修改为zookeeper//127.0.0.1:2181,同时创建ZookeeperRegistry作为注册中心的实现。
这里最大的差异在于,onModuleStarted方法在执行时,会校验是否registry instanceof ServiceDiscoveryRegistry,满足才会走应用级注册导出,也就是在注册中心上配置应用实例。/services/dubbo-provider-application/ip:20881
public class DefaultModuleDeployer extends AbstractDeployer<ModuleModel> implements ModuleDeployer {
@Override
public synchronized Future start() throws IllegalStateException {
if (isStopping() || isStopped() || isFailed()) {
throw new IllegalStateException(getIdentifier() + " is stopping or stopped, can not start again");
}
try {
if (isStarting() || isStarted()) {
return startFuture;
}
// 给DeployListener监听器,统一触发onStarting事件,传入当前scopeModel
// 然后用当前的moduleModel(初始化时创建的),设置启动状态
onModuleStarting();
// initialize
// 判断是否有进行初始化,其实上一步已经做了,这里下面两行都会跳过
applicationDeployer.initialize();
initialize();
// 服务导出,调用ServiceConfig->export()方法,根据配置的协议(可能有多个)进行,也可以根据
// @DubboService指定的协议,开始拼凑出多个URL,比如tri//ip:20880, dubbo//ip:20881等。
// 接着开始启动各个协议依赖的底层通信框架,比如triple跟dubbo都是用的netty,reset协议用的jetty。
// (注:启动通信框架肯定要在注册之前,不然注册上去了,通信框架没好,调用不了)
// 如果metadata-type=local创建MetadataService,这里不过多阐述,主要是需要绑定一个端口问题,可见下方小结
exportServices();
// prepare application instance
// exclude internal module to avoid wait itself
if (moduleModel != moduleModel.getApplicationModel().getInternalModule()) {
applicationDeployer.prepareInternalModule();
}
// 服务导入
referServices();
// if no async export/refer services, just set started
if (asyncExportingFutures.isEmpty() && asyncReferringFutures.isEmpty()) {
// 应用级注册
// ExporterDeployListener.onModuleStarted ---> metadataServiceExporter.export()
onModuleStarted();
} else {
frameworkExecutorRepository.getSharedExecutor().submit(() -> {
try {
// wait for export finish
waitExportFinish();
// wait for refer finish
waitReferFinish();
} catch (Throwable e) {
logger.warn("wait for export/refer services occurred an exception", e);
} finally {
onModuleStarted();
}
});
}
} catch (Throwable e) {
onModuleFailed(getIdentifier() + " start failed: " + e, e);
throw e;
}
return startFuture;
}
}
应用+服务关系开始注册:MetadataServiceNameMapping#map, 核心代码:succeeded = metadataReport.registerServiceAppMapping(serviceInterface, DEFAULT_MAPPING_GROUP, newConfigContent, configItem.getTicket()); 将mapping/应用的关系,注册上。
如果dubbo.application.metadata-type=remote,会在DefaultApplicationDeployer#registerServiceInstance中开启应用级别注册,也就是会在dubbo.metadata.应用名.revision进行注册。
举例应用实例节点报文:/dubbo/metadata/dubbo-provider-application/b6e89e057ae61a1d2c9939d68def7ead
{
"app" : "dubbo-provider-application",
"revision" : "b6e89e057ae61a1d2c9939d68def7ead",
"services" : {
"com.abc.service.DouyinService:tri" : {
"name" : "com.abc.service.DouService",
"protocol" : "tri",
"path" : "com.abc.service.DouService",
"params" : {
"side" : "provider",
"release" : "3.0.7",
"methods" : "getRoomInfo",
"deprecated" : "false",
"dubbo" : "2.0.2",
"interface" : "com.abc.service.DouService",
"service-name-mapping" : "true",
"register-mode" : "instance",
"generic" : "false",
"metadata-type" : "remote",
"application" : "dubbo-provider-application",
"background" : "false",
"dynamic" : "true",
"anyhost" : "true"
}
},
"com.abc.service.HelloService:tri" : {
"name" : "com.abc.service.HelloService",
"protocol" : "tri",
"path" : "com.abc.service.HelloService",
"params" : {
"side" : "provider",
"release" : "3.0.7",
"methods" : "hello",
"deprecated" : "false",
"dubbo" : "2.0.2",
"interface" : "com.abc.service.HelloService",
"service-name-mapping" : "true",
"register-mode" : "instance",
"generic" : "false",
"metadata-type" : "remote",
"application" : "dubbo-provider-application",
"background" : "false",
"dynamic" : "true",
"anyhost" : "true"
}
}
}
}
举例应用实例:/services/dubbo-provider-application/192.168.0.1:20880
{
"name" : "dubbo-provider-application",
"id" : "192.168.0.1:20880",
"address" : "192.168.0.1",
"port" : 20880,
"sslPort" : null,
"payload" : {
"@class" : "org.apache.dubbo.registry.zookeeper.ZookeeperInstance",
"id" : "192.168.0.1:20880",
"name" : "dubbo-provider-application",
"metadata" : {
"dubbo.endpoints" : "[{\"port\":20880,\"protocol\":\"tri\"}]",
"dubbo.metadata.revision" : "b6e89e057ae61a1d2c9939d68def7ead",
"dubbo.metadata.storage-type" : "remote"
}
},
"registrationTimeUTC" : 1727689676226,
"serviceType" : "DYNAMIC",
"uriSpec" : null
}
上述是常见的元数据应用实例,得到一共暴露了哪些服务,以及通过什么协议进行的调用。不过这里有个注意点,虽然/services目录下配置了实例的ip:host(优先展示dubbo端口)。因此如果配置了多协议,比如dubbo,triple,要真正调用协议不能用service目录下实例的host,得用dubbo.endpoints属性对应的protocol才行,比如tri对应20880。
public class ServiceInstanceMetadataUtils {
......
public static void registerMetadataAndInstance(ApplicationModel applicationModel) {
LOGGER.info("Start registering instance address to registry.");
RegistryManager registryManager = applicationModel.getBeanFactory().getBean(RegistryManager.class);
// register service instance
// 获取当前注册中心,如zookeeper,将所有的应用+提供的服务,注册上去
// 注册的目录是:/dubbo/metadata/应用名/实例编号
// 因为可能存在应用A跟应用B,都有ServiceA跟ServieB,但是前者只注册了一个,后者注册了全部,此时不同的实例能提供的服务是不一样的,而且各自有各自的属性。
registryManager.getServiceDiscoveries().forEach(ServiceDiscovery::register);
}
}
因此一个服务导出的大致流程是:
-
生成mapping节点:
/dubbo/mapping/com.abc.service.DouyinService 内容:dubbo-provider-application -
生成metadata节点:
/dubbo/metadata/com.abc.service.DouService/provider/dubbo-provider-application 内容:上述示例。 -
如果元数据注册配置为remote:
直接把元数据都存储在zookeeper上,例如创建/dubbo/metadata/dubbo-provider-application/b6e89e057ae61a1d2c9939d68def7ead和/services/dubbo-provider-application/192.168.0.1:20880。 -
如果元数据注册配置为local:
本地会开启一个默认用当前第一个dubbo协议的端口,比如:dubbo://192.168.0.1:20881/org.apache.dubbo.metadata.MetadataService?anyhost=true&xxx来暴露metadataservice服务。
因为dubbo3之前都是根据配置端口来进行暴露的,但dubbo3需要自动创建新服务,因此需要获取适合的端口进行发布,默认情况会优先获取已有的Dubbo端口进行发布,如果没有的话ServerSocket ignored = new ServerSocket(i)的方式,每次i从20880+1,只要能创建成功,改变端口可用,即将改端口发布为dubbo:新端口。
比如triple使用了20880,就会创建dubbo:20881使用。如果当前配置了dubbo:20xxx,则会直接使用。
2、服务导入
2.1、 从ReferenceConfig.get -> RegistryProtocol.refer -> doRefer
方法开始,生成一个MigrationInvoker对象。
相关配置:
dubbo.application.parameters.migration.step: APPLICATION_FIRST 默认,其它FORCE_APPLICATION,FORCE_INTERFACE
dubbo.application.parameters.migration.threshold: 2 默认0
dubbo.application.parameters.migration.promotion: 50 默认100
doRefer执行服务导入:
public class RegistryProtocol implements Protocol, ScopeModelAware {
protected <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url, Map<String, String> parameters) {
......
url = url.putAttribute(CONSUMER_URL_KEY, consumerUrl);
// 统一外层创建MigrationInvoker
ClusterInvoker<T> migrationInvoker = getMigrationInvoker(this, cluster, registry, type, url, consumerUrl);
return interceptInvoker(migrationInvoker, url, consumerUrl);
}
}
getMigrationInvoker实现逻辑:
public class InterfaceCompatibleRegistryProtocol extends RegistryProtocol {
@Override
protected <T> ClusterInvoker<T> getMigrationInvoker(RegistryProtocol registryProtocol, Cluster cluster, Registry registry, Class<T> type, URL url, URL consumerUrl) {
// ClusterInvoker<T> invoker = getInvoker(cluster, registry, type, url);
return new MigrationInvoker<T>(registryProtocol, cluster, registry, type, url, consumerUrl);
}
}
接着开始扫描服务,选择到底用接口还是应用的:
public class MigrationInvoker<T> implements MigrationClusterInvoker<T> {
@Override
public void migrateToApplicationFirstInvoker(MigrationRule newRule) {
// 搞一个0的技术 countdownlatch 感觉没啥用,这里没看懂到底多出来干啥
CountDownLatch latch = new CountDownLatch(0);
// 开始根据3.0之前老版本,接口形式,扫一遍,有哪些服务
refreshInterfaceInvoker(latch);
// 3.0 之后的应用级注册,会涉及到dubbo.metadata.storage-type配置,来决定获取装配元数据内容
refreshServiceDiscoveryInvoker(latch);
// directly calculate preferred invoker, will not wait until address notify
// calculation will re-occurred when address notify later
// 假设应用跟接口都加载了,这里要决策出到底用那个渠道的
calcPreferredInvoker(newRule);
}
}
2.2、获取元数据配置
RegistryProtocol#doCreateInvoker 拼凑出消费者urlToRegistry,同时注册到zk。
2.3、接口服务导入(如配置是)
在directory.subscribe(toSubscribeUrl(urlToRegistry));进行服务的发现跟导入。
public class ZookeeperRegistry extends CacheableFailbackRegistry {
@Override
public void doSubscribe(final URL url, final NotifyListener listener) {
try {
checkDestroyed();
// 如果是订阅*,才走,默认不走
if (ANY_VALUE.equals(url.getServiceInterface())) {
......
} else {
CountDownLatch latch = new CountDownLatch(1);
try {
List<URL> urls = new ArrayList<>();
// path有几种类型
// 第一种:/dubbo/com.abc.service.DouService/providers
// 第二种:/dubbo/com.abc.service.DouService/configurators
// 第三种:/dubbo/com.abc.service.DouService/routers
// 老一套的接口加载方式,跟之前获取的一样,从zk上拿下来,放到注册列表中
for (String path : toCategoriesPath(url)) {
ConcurrentMap<NotifyListener, ChildListener> listeners = zkListeners.computeIfAbsent(url, k -> new ConcurrentHashMap<>());
ChildListener zkListener = listeners.computeIfAbsent(listener, k -> new RegistryChildListenerImpl(url, path, k, latch));
if (zkListener instanceof RegistryChildListenerImpl) {
((RegistryChildListenerImpl) zkListener).setLatch(latch);
}
zkClient.create(path, false);
// 获取path下面的所有子节点信息,并且注册上订阅
List<String> children = zkClient.addChildListener(path, zkListener);
if (children != null) {
urls.addAll(toUrlsWithEmpty(url, path, children));
}
}
notify(url, listener, urls);
} finally {
// tells the listener to run only after the sync notification of main thread finishes.
latch.countDown();
}
}
} catch (Throwable e) {
throw new RpcException("Failed to subscribe " + url + " to zookeeper " + getUrl() + ", cause: " + e.getMessage(), e);
}
}
}
2.4、应用服务导入(如配置是)
public class ServiceDiscoveryRegistry extends FailbackRegistry {
protected void subscribeURLs(URL url, NotifyListener listener, Set<String> serviceNames) {
// dubbo-provider-application
serviceNames = toTreeSet(serviceNames);
// dubbo-provider-application
String serviceNamesKey = toStringKeys(serviceNames);
// com.abc.service.DouService
String protocolServiceKey = url.getProtocolServiceKey();
logger.info(String.format("Trying to subscribe from apps %s for service key %s, ", serviceNamesKey, protocolServiceKey));
// register ServiceInstancesChangedListener
// 同服务上锁等待
Lock appSubscriptionLock = getAppSubscription(serviceNamesKey);
try {
appSubscriptionLock.lock();
ServiceInstancesChangedListener serviceInstancesChangedListener = serviceListeners.get(serviceNamesKey);
// 默认第一次都是null,
if (serviceInstancesChangedListener == null) {
serviceInstancesChangedListener = serviceDiscovery.createListener(serviceNames);
serviceInstancesChangedListener.setUrl(url);
for (String serviceName : serviceNames) {
// 通过服务名,拿到所有的服务提供者列表 如:/services/dubbo-provider-application
// 例如:DefaultServiceInstance{serviceName='dubbo-provider-application', host='192.168.0.1', port=20880, enabled=true, healthy=true, metadata={dubbo.endpoints=[{"port":20880,"protocol":"tri"}], dubbo.metadata.revision=3cb7fba90f3ede1573bf4497a7e67ax1, dubbo.metadata.storage-type=remote}}
List<ServiceInstance> serviceInstances = serviceDiscovery.getInstances(serviceName);
if (CollectionUtils.isNotEmpty(serviceInstances)) {
// 开始获取注册中心数据
serviceInstancesChangedListener.onEvent(new ServiceInstancesChangedEvent(serviceName, serviceInstances));
}
}
serviceListeners.put(serviceNamesKey, serviceInstancesChangedListener);
}
if (!serviceInstancesChangedListener.isDestroyed()) {
serviceInstancesChangedListener.setUrl(url);
listener.addServiceListener(serviceInstancesChangedListener);
// 把默认SUPPORTED_PROTOCOLS协议全匹配一遍{"dubbo", "tri", "rest"}
// 匹配成功代表就是有配置,拼凑出所有的服务URI,在AbstractDirectory#refreshInvokerInternal中赋值给validInvokers
// 该validInvokers会在AbstractDirectory#list负载均衡时直接validInvokers.clone拿来使用
serviceInstancesChangedListener.addListenerAndNotify(protocolServiceKey, listener);
serviceDiscovery.addServiceInstancesChangedListener(serviceInstancesChangedListener);
} else {
logger.info(String.format("Listener of %s has been destroyed by another thread.", serviceNamesKey));
serviceListeners.remove(serviceNamesKey);
}
} finally {
appSubscriptionLock.unlock();
}
}
}
serviceInstancesChangedListener.onEvent 的执行逻辑:
public class ServiceInstancesChangedListener {
private synchronized void doOnEvent(ServiceInstancesChangedEvent event) {
if (destroyed.get() || !accept(event) || isRetryAndExpired(event)) {
return;
}
// 拿到所有实例,放到allInstances中
refreshInstance(event);
if (logger.isDebugEnabled()) {
logger.debug(event.getServiceInstances().toString());
}
// 存放每个应用对应的实例
// "3cb7fba90f3ede1573bf4497a7e67dx1" -> {LinkedList@8643} size = 1
// "fe322d67d8b797909c8481e8471deex1" -> {LinkedList@8664} size = 1
Map<String, List<ServiceInstance>> revisionToInstances = new HashMap<>();
Map<String, Map<String, Set<String>>> localServiceToRevisions = new HashMap<>();
// grouping all instances of this app(service name) by revision
for (Map.Entry<String, List<ServiceInstance>> entry : allInstances.entrySet()) {
List<ServiceInstance> instances = entry.getValue();
for (ServiceInstance instance : instances) {
// 这一步比较关键,需要通过revision:3cb7fba90f3ede1573bf4497a7e67ax1去找对应的应用元数据
// 才能具体知道,一个应用到底提供了哪些服务接口,以及什么协议等
String revision = getExportedServicesRevision(instance);
if (revision == null || EMPTY_REVISION.equals(revision)) {
if (logger.isDebugEnabled()) {
logger.debug("Find instance without valid service metadata: " + instance.getAddress());
}
continue;
}
List<ServiceInstance> subInstances = revisionToInstances.computeIfAbsent(revision, r -> new LinkedList<>());
subInstances.add(instance);
}
}
// get MetadataInfo with revision
for (Map.Entry<String, List<ServiceInstance>> entry : revisionToInstances.entrySet()) {
String revision = entry.getKey();
List<ServiceInstance> subInstances = entry.getValue();
// 根据dubbo.metadata.storage-type配置的不同获取元数据实现
// remote:调用核心方法:MetadataUtils#getRemoteMetadata
// 从zk上找并json序列化后返回,如路径:/dubbo/metadata/dubbo-provider-application/3cb7fba90f3ede1573bf4497a7e67dx1
// local:获取dubbo.metadata-service.url-params元数据参数,拼凑出具体的服务URI
// 然后根据URI,创建出MetadataInfo。默认实现用的是DubboInvoker,最后创建出元数据的Proxy对象
MetadataInfo metadata = serviceDiscovery.getRemoteMetadata(revision, subInstances);
parseMetadata(revision, metadata, localServiceToRevisions);
// update metadata into each instance, in case new instance created.
for (ServiceInstance tmpInstance : subInstances) {
MetadataInfo originMetadata = tmpInstance.getServiceMetadata();
if (originMetadata == null || !Objects.equals(originMetadata.getRevision(), metadata.getRevision())) {
tmpInstance.setServiceMetadata(metadata);
}
}
}
int emptyNum = hasEmptyMetadata(revisionToInstances);
if (emptyNum != 0) {// retry every 10 seconds
hasEmptyMetadata = true;
if (retryPermission.tryAcquire()) {
if (retryFuture != null && !retryFuture.isDone()) {
// cancel last retryFuture because only one retryFuture will be canceled at destroy().
retryFuture.cancel(true);
}
retryFuture = scheduler.schedule(new AddressRefreshRetryTask(retryPermission, event.getServiceName()), 10_000L, TimeUnit.MILLISECONDS);
logger.warn("Address refresh try task submitted");
}
// return if all metadata is empty, this notification will not take effect.
if (emptyNum == revisionToInstances.size()) {
logger.error("Address refresh failed because of Metadata Server failure, wait for retry or new address refresh event.");
return;
}
}
hasEmptyMetadata = false;
Map<String, Map<Set<String>, Object>> protocolRevisionsToUrls = new HashMap<>();
Map<String, Object> newServiceUrls = new HashMap<>();
// 遍历所有找到的服务列表
// "dubbo" -> {HashMap@8915} size = 1 "tri" -> {HashMap@8485} size = 2
for (Map.Entry<String, Map<String, Set<String>>> entry : localServiceToRevisions.entrySet()) {
String protocol = entry.getKey();
entry.getValue().forEach((protocolServiceKey, revisions) -> {
Map<Set<String>, Object> revisionsToUrls = protocolRevisionsToUrls.computeIfAbsent(protocol, k -> new HashMap<>());
Object urls = revisionsToUrls.get(revisions);
// 假设dubbo有一个服务,tri有三个,这里只有每个协议第一次的时候会进入,处理完之后会缓存,避免多次查找同一个协议的信息
if (urls == null) {
// 获取配置的dubbo.endpoints,如:[{\"port\":20881,\"protocol\":\"dubbo\"},{\"port\":20880,\"protocol\":\"tri\"}]",
urls = getServiceUrlsCache(revisionToInstances, revisions, protocol);
revisionsToUrls.put(revisions, urls);
}
newServiceUrls.put(protocolServiceKey, urls);
});
}
// "dubbo-provider-application/org.apache.dubbo.metadata.MetadataService:1.0.0:dubbo" -> {ArrayList@9457} size = 1
//"com.zhouyu.service.DouService:tri" -> {ArrayList@9605} size = 2
//"com.zhouyu.service.HelloService:tri" -> {ArrayList@9605} size = 2
this.serviceUrls = newServiceUrls;
this.notifyAddressChanged();
}
}
2.5、migration.step=APPLICATION_FIRST时选取策略
当接口跟应用服务导入时调用:MigrationInvoker#calcPreferredInvoker,开始选取。
① 如果只有接口服务,没有应用服务,直接选接口服务
② 如果没有应用服务,只有接口服务,直接选应用服务
③ 如果既有接口服务,也有应用服务的话,获取配置dubbo.application.migration.threshold默认是0
用 应用服务数 / 接口服务数 >= threshold 时返回float类型,满足则取应用服务,否则取接口服务。
还有一个例外条件,当就是假设第6步已经确定了要用哪个服务,但是在MigrationInvoker#invoke时
判断如果step == APPLICATION_FIRST类型,获取配置:dubbo.application.parameters.migration.promotion默认100
再用0-100 取一个随机数判断是否 大于 promotion,如果大于,还是走老版本的接口服务调用,否则走应用服务调用。
(方便灰度测试?)
2.6、应用级服务导入时-同协议覆盖BUG
官方也打了日志提示了,但为什么说是BUG?因为多个端口都会在服务提供者进行暴露,即都会生成netty服务。
应用级在构造元数据dubbo.endpoints时,如果发现协议有同名端口不一样,测试时发现20880覆盖20881。
核心代码位置:ProtocolPortsMetadataCustomizer#customize。(至最新版3.2.15依旧存在,加了日志提示)。
解决方案:将应用级导入,改为接口级导入,即migration.step=FORCE_INTERFACE
dubbo.protocols.p1.name=dubbo
dubbo.protocols.p1.port=20880
dubbo.protocols.p2.name=dubbo
dubbo.protocols.p2.port=20881
2.7、接口级服务导入时-triple协议BUG
注意跟上一个BUG的区别,这里是接口级,且只有triple协议会存在BUG。现象是20881会覆盖20880,后者接收不到请求。
dubbo.protocols.p1.name=tri
dubbo.protocols.p1.port=20880
dubbo.protocols.p2.name=tri
dubbo.protocols.p2.port=20881
triple协议,端口会覆盖,原因分析:
TirpleProtocol#export,在pathResolver.add(url.getServiceKey(), invoker);处理时
得到的url.getServiceKey()为com.abc.service.HelloService,没有携带上端口,所以当两个服务者只有端口区别时,这里是没法区分的,最终执行path2Invoker.put(path, invoker); path即服务名,因此会出现后者覆盖前者端口的现象。
dubbo协议,端口不会覆盖,原因分析:
DubboProtocol#export—>DubboProtocol#serviceKey—>serviceKey(port, url.getPath(), url.getVersion(), url.getGroup());
可以很明显的看出,dubbo协议时,port会加入拼凑逻辑,如:com.abc.service.HelloService:20880。
解决方案:暂时没有解决办法,如配置dubbo->20880,tri->20881不同协议不同端口来规避。
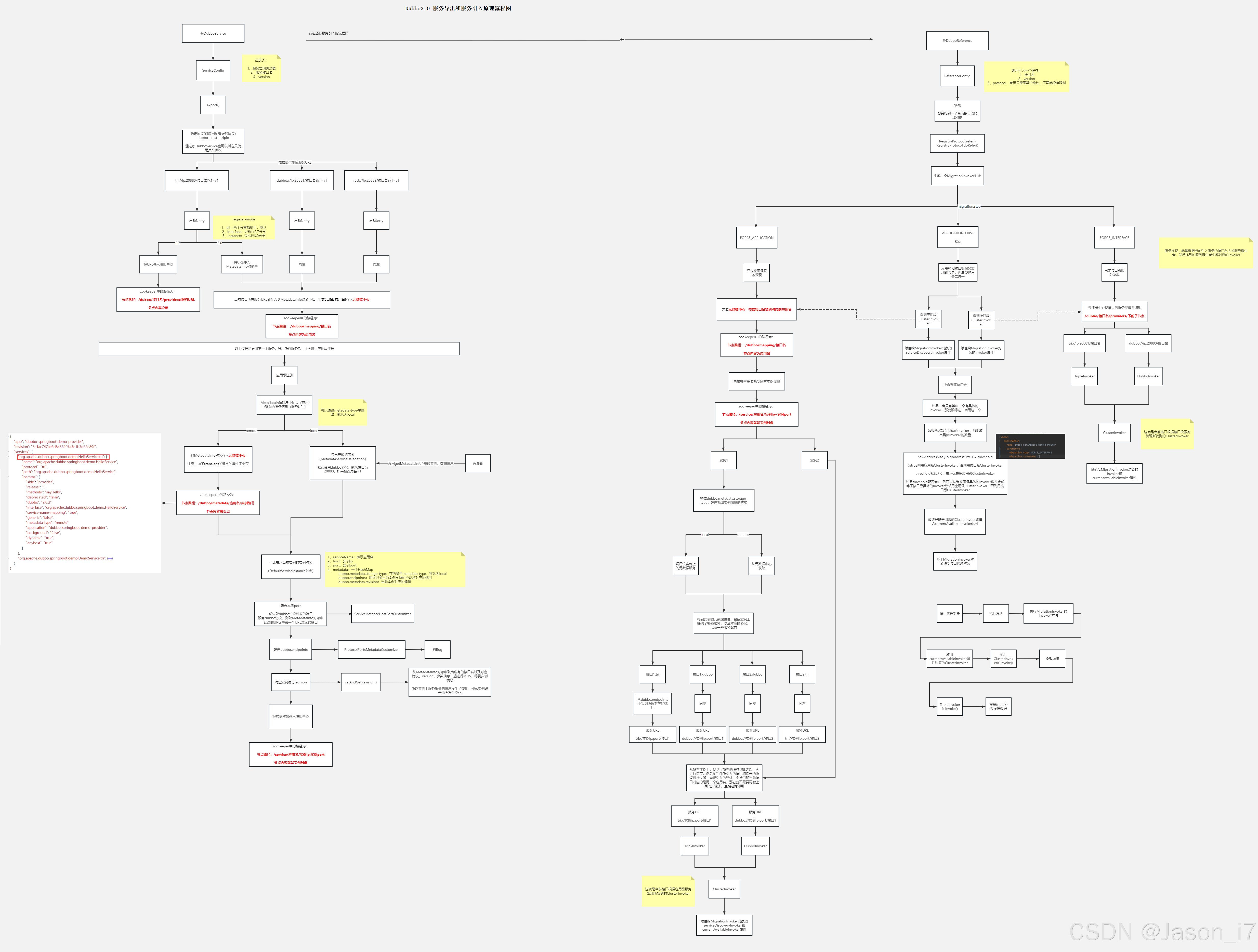
3、服务导出和服务引入原理流程图
4、Triple协议服务调用过程
4.1、Triple协议是什么?
4.1.1、HTTP1的缺陷
- 不能并行请求
HTTP1 发送消息为请求->响应模型,客户端请求服务端,必须等服务端发送响应后,才能继续发起新请求。不这样做的话,一次性发多个请求,收到多个响应,都不知道怎么把对应的请求->响应关联上。 - “大头儿子”
HTTP1每次发送请求都会携带很多的请求头,并且有很多请求头是无用的,或可以减少的。在请求量大时尤为突出,降低了传输效率。
4.1.2、HTTP2简单介绍
HTTP/2 是 HTTP 协议的第二个主要版本,它在 HTTP/1.1 的基础上进行了多项重要改进,主要目标是通过支持完整的请求和响应多路复用,最小化协议开销,添加了对请求优先级和服务器推送的支持等,来改进网络通信的性能。以下是 HTTP/2 的主要特性:
- 多路复用:HTTP/2 允许在单个连接中同时处理多个请求和响应消息,这可以减少网络延迟和整体加载时间。
- 二进制协议:与 HTTP/1.1 的文本格式不同,HTTP/2 是一个二进制协议,这使得它更易于解析,更高效,更小的错误可能性。
- 头部压缩:HTTP/2 引入了 HPACK 算法对头部信息进行压缩,以减少网络传输的数据量。
- 服务器推送:HTTP/2 可以让服务器在客户端需要之前就主动发送数据,这可以进一步提高网页加载速度。
- 流优先级:HTTP/2 支持为请求设置优先级。这意味着如果有多个请求正在进行,浏览器和服务器知道哪些请求应该优先处理。
- 安全性:虽然 HTTP/2 协议本身并不强制使用 HTTPS,但是大多数现代浏览器只在 HTTPS 下支持 HTTP/2。
同时HTTP2设计了帧的概念,如下图所示:

- 帧长度,用三个字节来存一个数字,这个数字表示当前帧的实际传输的数据的大小,3个字节表示的最大数字是2的24次方(16M),所以一个帧最大为9字节+16M。
- 帧类型,占一个字节,可以分为数据帧和控制帧。
a. 数据帧又分为:HEADERS 帧和 DATA 帧,用来传输请求头、请求体的。
b. 控制帧又分为:SETTINGS、PING、PRIORITY,用来进行管理的。 - 标志位,占一个字节,可以用来表示当前帧是整个请求里的最后一帧,方便服务端解析。
- 流标识符,占4个字节,在Java中也就是一个int,不过最高位保留不用,表示Stream ID,这也是HTTP2的一个重要设计。
- 实际传输的数据Payload,如果帧类型是HEADERS,那么这里存的就是请求头,如果帧类型是DATA ,那么这里存的就是请求体。
通过这种设计,我们可以发现,我们就可以来压缩请求头了,比如如果帧的类型是HEADERS ,那就进行压缩,当然压缩算法是固定的HPACK算法,不能更换。
如果仅仅是新增了能压缩请求头,那还不至于说HTTP2性能高,HTTP2最优秀的地方在于支持Stream。
上面可以看到每个帧里有一个流标识符,表示Stream ID,这是HTTP2的新特性,表示一个“虚拟流”,达到的效果是,我们可以在一个TCP连接中,同时维护多个Stream,每一个帧都是属于某一个Stream。
也就是说客户端在一个TCP连接上,可以并发的给服务端同时发送多个帧,比如同时发送多个HEADERS帧(请求头),多个DATA 帧(请求体),这是HTTP1不支持,对于HTTP1而言,如果你先发了一个HTTP1请求,还没有收到响应结果的情况下,你又发了一个HTTP1请求,然后你收到了一个响应结果,此时你怎么知道这个响应结果对应的到底是哪一个HTTP1请求呢?你可能会想到在请求头和响应头中做一个标记,但这是属于HTTP1的扩展,HTTP1原生是不支持的,所以HTTP2就做了这个扩展,也就是Stream ID。
比如,现在有一个客户端,想向服务端发送三个请求,如果你只建了一个Stream,那么你仍然只能:
发送请求1–>接收响应1–>发送请求2–>接收响应2–>发送请求2–>接收响应2。
但是如果你建了三个Stream,那么你就可以开三个线程,同时把这三个请求分别发送到不同的Stream中去,这样服务端那么也会分别从三个Stream中获取到不同的请求进行处理,然后把响应结果也发送到对应的Stream中被客户端接收到,这样就极大的提高了并发。
所以我们在利用HTTP2发送一个请求时,首先:
- 新建一个TCP连接(三次握手)。
- 新建一个Stream,生成一个新的StreamID,生成一个控制帧,帧里记录了前面生成出来的StreamID,通过TCP连接发送出去
- 生成一个要发送的请求对应的HEADERS 帧,用来发送请求头,也是key:value的格式,先利用ascii进行编码,然后利用HPACK算法进行压缩,最终把压缩之后的字节存在帧中的Payload区域,记录好StreamID,最后通过TCP连接把这个HEADERS 帧发送出去。
- 最后把要发送的请求体数据按指定的压缩算法(请求中所指定的压缩算法,比如gzip)进行压缩,把压缩之后的字节生成DATA 帧,记录好StreamID,通过TCP连接把DATA 帧发送出去。
对于服务端而言:
- 会不断的从TCP连接接收到某些帧。
- 当接收到一个控制帧时,表示客户端要和服务端新建一个Stream,在服务端记录一下StreamID,比如在Dubbo3.0的源码中会生成一个ServerStreamObserver的对象。
- 当接收到一个HEADERS 帧,取出StreamID,找到对应的ServerStreamObserver对象,并解压得到请求头,把请求头信息保存在ServerStreamObserver对象中。
- 当接收到一个DATA 帧时,取出StreamID,找到对应的ServerStreamObserver对象,根据请求头的信息看如何解压请求体,解压之后就得到了原生了请求体数据,然后按业务逻辑处理请求体。
- 处理完了之后,就把结果也生成HEADERS 帧和DATA 帧时发送客户端,客户端此时就变成了服务端,来处理响应结果。
- 客户端接收到响应结果的HEADERS 帧,是也先解压得到响应头,记录响应体的解压方式。
- 然后继续接收到响应结果的DATA 帧,解压响应体,得到原生的响应体,处理响应体。
对于Triple协议而言,我们主要理解HTTP2中的Stream、HEADERS 帧、DATA 帧就可以了。
4.1.3、Triple协议
Triple 协议是一种新的通信协议,它基于 gRPC 和 HTTP/2 协议,旨在提供更高效、更强大的远程过程调用(RPC)能力。Triple 协议是 Dubbo 3.0 中的一个新特性。
Triple 协议与 HTTP/2 的主要区别在于它们的目标和用途:
- HTTP/2 是一个通用的、无状态的、应用层协议,用于提供更高效的 Web 通信。它支持多路复用、服务器推送、头部压缩等特性,以提高 Web 应用的性能。
- Triple 协议 是一个专为 Dubbo 设计的、基于 gRPC 和 HTTP/2 的 RPC 协议。它提供了更高效的序列化和反序列化、更强大的服务发现和路由能力、更好的跨语言调用支持等特性,以提高 Dubbo 应用的性能和功能。
- 总的来说,Triple 协议是在 HTTP/2 的基础上,加入了 Dubbo 的一些特性和优化,以更好地支持 Dubbo 的 RPC 调用。
4.2、服务端-启动Triple服务
TripleProtocol#export中的PortUnificationExchanger.bind(invoker.getUrl());进行Triple服务器的启动,默认用的是Netty。
public class PortUnificationServerHandler extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
// Will use the first five bytes to detect a protocol.
// http2请求头字节至少5个长度
if (in.readableBytes() < 5) {
return;
}
for (final WireProtocol protocol : protocols) {
in.markReaderIndex();
// 主要目的:判断是否是HTTP2的请求
// 比如HTTP2会有固定的请求前沿:PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n (一段字符串)
final ProtocolDetector.Result result = protocol.detector().detect(ctx, in);
in.resetReaderIndex();
switch (result) {
case UNRECOGNIZED:
continue;
case RECOGNIZED:
// 如果是HTTP2格式,给Netty新增一系列处理器来进行支持
// 这里protocol默认实现是:TripleHttp2Protocol#configServerPipeline
// 初始化时新增了两个handler,比如:TripleServerConnectionHandler,TripleTailHandler等
// TripleTailHandler的主要作用是:接收到是HTTP2请求时,构造HTTP2Stream格式的channel(构造头帧,内容体对象)
// TripleHttp2FrameServerHandler的主要作用是判断接收到的请求到底是请求头帧还是请求体帧
// msg instanceof Http2HeadersFrame or msg instanceof Http2DataFrame
protocol.configServerPipeline(url, ctx.pipeline(), sslCtx);
ctx.pipeline().remove(this);
case NEED_MORE_DATA:
return;
default:
return;
}
}
// Unknown protocol; discard everything and close the connection.
in.clear();
ctx.close();
}
}
4.3、消费端-服务导入,创建TripleInvoker
在TripleInvoker的构造方法中,会执行connectionManager.connect(url);去创建一个Netty Bootstrap,但是不启动,等到后续第一次有请求invoke时才启动(懒加载),才回去创建Socket连接。
// !!!其实都是双端流
// UNARY格式----new UnaryClientCallListener
// StreamObserver.onNext("xxx") ---> requestObserver.onCompleted()
String hello(String name);
// SERVER_STREAM 服务端流---> new ObserverToClientCallListenerAdapter
// 注意只拿了第一个参数发送,也就是不支持多参数,requestObserver.onNext(invocation.getArguments()[0])
// requestObserver.onCompleted();
void sayHelloServerStream(String request, StreamObserver<String> response);
// CLIENT_STREAM 双端流 new ObserverToClientCallListenerAdapter
// onNext业务自己调用
StreamObserver<String> sayHelloStream(StreamObserver<String> response);
在TripleInvoker的invoker调用中,主要分三种请求格式:
- UNARY:普通请求,参数可以随便填,参数跟返回都没有StreamObserver类型对象。
- SERVER_STREAM:服务端流,请求参数只有一个(业务参),后面跟一个StreamObserver对象,返回void。
- CLIENT_STREAM:双端流,一个参数跟返回值都是StreamObserver类型。
public class TripleInvoker<T> extends AbstractInvoker<T> {
@Override
protected Result doInvoke(final Invocation invocation) {
......
ConsumerModel consumerModel = (ConsumerModel) (invocation.getServiceModel() != null
? invocation.getServiceModel() : getUrl().getServiceModel());
// 拿到服务接口信息和当前调用的方法信息
ServiceDescriptor serviceDescriptor = consumerModel.getServiceModel();
// 获取当前调用的方式是哪种,即根据参数类型和个数来判断
final MethodDescriptor methodDescriptor = serviceDescriptor.getMethod(
invocation.getMethodName(),
invocation.getParameterTypes());
// HTTP2请求发起者
ClientCall call = new ClientCall(connection, streamExecutor,
getUrl().getOrDefaultFrameworkModel());
AsyncRpcResult result;
try {
switch (methodDescriptor.getRpcType()) {
case UNARY:
result = invokeUnary(methodDescriptor, invocation, call);
break;
case SERVER_STREAM:
result = invokeServerStream(methodDescriptor, invocation, call);
break;
case CLIENT_STREAM:
case BI_STREAM:
result = invokeBiOrClientStream(methodDescriptor, invocation, call);
break;
default:
throw new IllegalStateException("Can not reach here");
}
return result;
} catch (Throwable t) {
......
}
}
// 假设请求是双断流(其实本质都是双端,只不过其它两内底层进行了逻辑实现,上层看省略了而已)
AsyncRpcResult invokeBiOrClientStream(MethodDescriptor methodDescriptor, Invocation invocation,
ClientCall call) {
final AsyncRpcResult result;
// 为了拼凑请求头,无非就是把URL后面的隐含参数,timeout,group,version,service,method等进行赋值
// 注意这里如果没有配置超时时间,这里会默认指定timeout为3秒。
// 其次compressor压缩字段是TODO,主要作用是用来压缩请求体,当前暂未实现。
RequestMetadata request = createRequest(methodDescriptor, invocation, null);
// 拿到我们的请求参数,StreamObserver对象,这个对象主要是为了接收服务端的事件响应
StreamObserver<Object> responseObserver = (StreamObserver<Object>) invocation.getArguments()[0];
// 创建一个真正请求的StreamObserver对象
final StreamObserver<Object> requestObserver = streamCall(call, request, responseObserver);
result = new AsyncRpcResult(
CompletableFuture.completedFuture(new AppResponse(requestObserver)), invocation);
return result;
}
StreamObserver<Object> streamCall(ClientCall call,
RequestMetadata metadata,
StreamObserver<Object> responseObserver) {
if (responseObserver instanceof CancelableStreamObserver) {
final CancellationContext context = new CancellationContext();
((CancelableStreamObserver<Object>) responseObserver).setCancellationContext(context);
context.addListener(context1 -> call.cancel("Canceled by app", null));
}
// 把请求参数的StreamObserver放到监听器中,用于做事件回调(通知)从而达到触发StreamObserver方法的作用
ObserverToClientCallListenerAdapter listener = new ObserverToClientCallListenerAdapter(
responseObserver);
// 开始创建socket
return call.start(metadata, listener);
}
}
创建HTTP2的socket通道—ClientStream
public class ClientStream extends AbstractStream implements Stream {
private WriteQueue createWriteQueue(Channel parent) {
// 创建一个HTTP2的channel
final Http2StreamChannelBootstrap bootstrap = new Http2StreamChannelBootstrap(parent);
// 打开通道
final Future<Http2StreamChannel> future = bootstrap.open().syncUninterruptibly();
if (!future.isSuccess()) {
throw new IllegalStateException("Create remote stream failed. channel:" + parent);
}
final Http2StreamChannel channel = future.getNow();
// 给该channel绑定handler,其中TripleHttp2ClientResponseHandler主要用于处理响应
channel.pipeline()
.addLast(new TripleCommandOutBoundHandler())
.addLast(new TripleHttp2ClientResponseHandler(createTransportListener()));
// 初始化写数据队列,(每次写不是实时,都是放到这个队列里面,在合适的时候进行flush才会真正发送)
return new WriteQueue(channel);
}
}
消费端的onNext实现—ClientCall
public class ClientCall {
// 连接管道,发送&接收数据
private ClientStream stream;
// 监听事件器
private ClientCall.Listener listener;
......
public void sendMessage(Object message) {
if (canceled) {
throw new IllegalStateException("Call already canceled");
}
// 判断是否发送过请求头了
if (!headerSent) {
headerSent = true;
// 没有发送过,组装请求头,进行发送,构建逻辑见下方
stream.sendHeader(requestMetadata.toHeaders());
}
final byte[] data;
try {
// 拿到onNext里面的内容,采用默认hessian4
data = requestMetadata.packableMethod.packRequest(message);
// 表示是否进行了压缩,默认0
int compressed =
Identity.MESSAGE_ENCODING.equals(requestMetadata.compressor.getMessageEncoding())
? 0 : 1;
final byte[] compress = requestMetadata.compressor.compress(data);
// 创建请求内容体实例,DataQueueCommand#doSend,最终发送消息到WriteQueue
// 第一个字节记录请求体是否被压缩
// buf.writeByte(compressFlag);
// 后四个字节记录请求头的长度
// buf.writeInt(data.length);
// 真实的数据
// buf.writeBytes(data);
// 发送
// ctx.write(new DefaultHttp2DataFrame(buf, endStream), promise);
stream.writeMessage(compress, compressed);
} catch (Throwable t) {
LOGGER.error(String.format("Serialize triple request failed, service=%s method=%s",
requestMetadata.service,
requestMetadata.method), t);
cancel("Serialize request failed", t);
listener.onClose(TriRpcStatus.INTERNAL.withDescription("Serialize request failed")
.withCause(t), null);
}
}
}
HTTP2请求头构建的细节(重要:新增了grpc标准请求头,用于兼容了grpc格式请求)
public class RequestMetadata {
public DefaultHttp2Headers toHeaders() {
DefaultHttp2Headers header = new DefaultHttp2Headers(false);
// scheme:HTTP
header.scheme(scheme)
// address:IP和端口
.authority(address)
// 固定POST请求
.method(HttpMethod.POST.asciiName())
// 具体的方法,到这也就意外着,已经知道要调用哪个服务了
.path("/" + service + "/" + method.getMethodName())
// 兼容grpc请求头,“application/grpc+proto”
.set(TripleHeaderEnum.CONTENT_TYPE_KEY.getHeader(), TripleConstant.CONTENT_PROTO)
.set(HttpHeaderNames.TE, HttpHeaderValues.TRAILERS);
// 超时时间设置
setIfNotNull(header, TripleHeaderEnum.TIMEOUT.getHeader(), timeout);
if (!"1.0.0".equals(version)) {
setIfNotNull(header, TripleHeaderEnum.SERVICE_VERSION.getHeader(), version);
}
// 兼容grpc请求头 ......tri-service-group等等
setIfNotNull(header, TripleHeaderEnum.SERVICE_GROUP.getHeader(), group);
setIfNotNull(header, TripleHeaderEnum.CONSUMER_APP_NAME_KEY.getHeader(),
application);
setIfNotNull(header, TripleHeaderEnum.GRPC_ACCEPT_ENCODING.getHeader(),
acceptEncoding);
if (!Identity.MESSAGE_ENCODING.equals(compressor.getMessageEncoding())) {
setIfNotNull(header, TripleHeaderEnum.GRPC_ENCODING.getHeader(),
compressor.getMessageEncoding());
}
StreamUtils.convertAttachment(header, attachments);
return header;
}
}
WriteQueue队列发送消息时,为了提高发送效率,每次最大循环128次再统一发送。
比如发送请求头帧跟数据帧,如果是紧接着的,就进行合并发送。
注意:WriteQueue跟ClientStream绑定,每次创建一个ClientStream就会新创建一个只属于它的WriteQueue消息队列。
public class WriteQueue {
public ChannelPromise enqueue(QueuedCommand command) {
ChannelPromise promise = command.promise();
if (promise == null) {
promise = channel.newPromise();
command.promise(promise);
}
queue.add(command);
// 调用发送逻辑
scheduleFlush();
return promise;
}
public void scheduleFlush() {
if (scheduled.compareAndSet(false, true)) {
// 获取一个线程组的线程,来执行flush,具体发送逻辑
channel.eventLoop().execute(this::flush);
}
}
// 多次循环获取消息,用于合并(批量)发送
private void flush() {
try {
QueuedCommand cmd;
int i = 0;
boolean flushedOnce = false;
// 只要队列中有元素取出来,没有则退出
while ((cmd = queue.poll()) != null) {
// 把数据帧添加到Http2StreamChannel中,添加并不会立马发送,调用了flush才发送
cmd.run(channel);
i++;
// 默认DEQUE_CHUNK_SIZE=128,到了就直接刷一次,即真正发送,然后退出
if (i == DEQUE_CHUNK_SIZE) {
i = 0;
channel.flush();
flushedOnce = true;
}
}
// 如果没有满128,也取不到消息了,也发送一次
if (i != 0 || !flushedOnce) {
channel.flush();
}
} finally {
scheduled.set(false);
if (!queue.isEmpty()) {
scheduleFlush();
}
}
}
}
消费端的onCompleted实现—ClientCall
// onNext发送消息体
DataQueueCommand.createGrpcCommand(message, endStream=false, compressed);
// onCompleted发送结束标识
new DefaultHttp2DataFrame(endStream=true)
这里对比onNext可以很明显知道差异,创建请求体时,endStream=false,onCompleted的endStream=true。
4.4、服务端-请求接收&响应
入口接收处:TripleHttp2FrameServerHandler#channelRead
public class TripleHttp2FrameServerHandler extends ChannelDuplexHandler {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 请求头时,校验
// 1、方法类型时POST 2、path不能为空,必须带/ 3、content-type不能为空且为application/grpc+proto等
// 常见请求头:
// "te" -> "trailers" ,"grpc-accept-encoding" -> "gzip", ":method" -> "POST"
// ":scheme" -> "http",":path" -> "/com.zhouyu.service.HelloService/sayHelloStream"
// "content-type" -> "application/grpc+proto", "tri-consumer-appname" -> "consumer-application"
// ":authority" -> "10.10.6.58:20880"
if (msg instanceof Http2HeadersFrame) {
onHeadersRead(ctx, (Http2HeadersFrame) msg);
} else if (msg instanceof Http2DataFrame) {
onDataRead(ctx, (Http2DataFrame) msg);
} else if (msg instanceof ReferenceCounted) {
// ignored
ReferenceCountUtil.release(msg);
}
}
}
onHeadersRead实现分析,根据请求类型的不同生成对应的监听器来处理。
- UNARY —> new UnaryServerCallListener 同步,invoke在onCompleted时才调用。
- SERVER_STREAM —> new ServerStreamServerCallListener 异步,invoke在onCompleted时才调用。
- CLIENT_STREAM —> new BiStreamServerCallListener 异步,invoke在创建时(接收到请求头时)就调用了。
public abstract class ServerCall {
protected ServerCall.Listener startInternalCall(
......
try {
ServerCall.Listener listener;
switch (methodDescriptor.getRpcType()) {
case UNARY:
listener = new UnaryServerCallListener(invocation, invoker, responseObserver);
requestN(2);
break;
case SERVER_STREAM:
listener = new ServerStreamServerCallListener(invocation, invoker,
responseObserver);
requestN(2);
break;
case BI_STREAM:
case CLIENT_STREAM:
listener = new BiStreamServerCallListener(invocation, invoker,
responseObserver);
requestN(1);
break;
default:
throw new IllegalStateException("Can not reach here");
}
return listener;
} catch (Throwable t) {
LOGGER.error("Create triple stream failed", t);
responseObserver.onError(TriRpcStatus.INTERNAL.withDescription("Create stream failed")
.withCause(t)
.asException());
}
return null;
}
}
UNARY 普通流-UnaryServerCallListener执行逻辑解析
public class UnaryServerCallListener extends AbstractServerCallListener {
public UnaryServerCallListener(RpcInvocation invocation, Invoker<?> invoker,
ServerCallToObserverAdapter<Object> responseObserver) {
super(invocation, invoker, responseObserver);
}
@Override
public void onReturn(Object value) {
// 会被父类回调,将结果发给消费者,同样也是onNext,onCompleted流程,后续在消费者接收到响应时会展开介绍
responseObserver.onNext(value);
responseObserver.onCompleted(TriRpcStatus.OK);
}
......
@Override
public void onMessage(Object message) {
// 根据参数类型的不同,创建好invocation,此时没有调用的
if (message instanceof Object[]) {
invocation.setArguments((Object[]) message);
} else {
invocation.setArguments(new Object[]{message});
}
}
......
@Override
public void onComplete() {
// 等待该方法被调用,真正发起invoke
invoke();
}
}
SERVER-STREAM 服务端流-ServerStreamServerCallListener执行逻辑,对比UnaryServerCallListener两处不同:
- onMessage 解析参数只拿了第一个
- onReturn没有默认执行onNext,onCompleted,后续由服务端逻辑来确定执行时机
public class ServerStreamServerCallListener extends AbstractServerCallListener {
public ServerStreamServerCallListener(RpcInvocation invocation, Invoker<?> invoker,
ServerCallToObserverAdapter<Object> responseObserver) {
super(invocation, invoker, responseObserver);
}
@Override
public void onReturn(Object value) {
// 啥也没干,等服务端自己调用onNext,onCompleted
}
@Override
public void onMessage(Object message) {
if (message instanceof Object[]) {
message = ((Object[]) message)[0];
}
invocation.setArguments(new Object[]{message, responseObserver});
}
@Override
public void onCancel(String errorInfo) {
responseObserver.cancel(TriRpcStatus.CANCELLED.withDescription(errorInfo).asException());
}
@Override
public void onComplete() {
// 也是掉该方法触发invoke
invoke();
}
}
CLIENT-STREAM 双端流-BiStreamServerCallListener 执行逻辑
invoker提前调用原因:
所谓双端流:更多的使用在于对返回值StreamObserver的利用,即:相互调用。
所以这里的invoke对比前两者有所不同,在构造时就进行了调用。因为不先调用就没法执行retrun StreamObserver对象,客户端就压根没法进行服务交互,进而没法实现双端调用。
public class BiStreamServerCallListener extends AbstractServerCallListener {
private StreamObserver<Object> requestObserver;
public BiStreamServerCallListener(RpcInvocation invocation, Invoker<?> invoker,
ServerCallToObserverAdapter<Object> responseObserver) {
super(invocation, invoker, responseObserver);
invocation.setArguments(new Object[]{responseObserver});
// invoke提前,不然没法完成双向流调用
invoke();
}
@Override
public void onReturn(Object value) {
// 返回服务端new StreamObserver对象
this.requestObserver = (StreamObserver<Object>) value;
}
@Override
public void onMessage(Object message) {
if (message instanceof Object[]) {
message = ((Object[]) message)[0];
}
requestObserver.onNext(message);
if (responseObserver.isAutoRequestN()) {
responseObserver.request(1);
}
}
@Override
public void onCancel(String errorInfo) {
requestObserver.onError(TriRpcStatus.CANCELLED
.withDescription(errorInfo).asException());
responseObserver.cancel(
TriRpcStatus.CANCELLED.withDescription("Cancel by client:" + errorInfo).asException());
}
@Override
public void onComplete() {
requestObserver.onCompleted();
}
}
onDataRead-处理请求体
public class ServerStream extends AbstractStream {
private void doOnData(ByteBuf data, boolean endStream) {
// deframer在处理请求头时,创建的TriDecoder解码器
deframer.deframe(data);
if (endStream) {
// 非双端流调用,关于invoke的执行,还会反序列化处理等
deframer.close();
}
}
}
TriDecoder解码器执行过程
请求响应:
解码完毕,在processBody执行各个监听器的onMessage方法。
此时onMessage会执行服务端的onNext方法,进而完成具体的服务调用,也可以在onNext方法中调用消费端的StreamObserver的逻辑(这取决于业务)。
即:向客户端发送onNext,onComplete也就是双向请求,就又回到到了消费者-服务发起环节。
等待接收到发送完成,endStream=true时,再执行各个监听器的onComplete方法。
监听器中主要也是对requestObserver对象的操作,也代表了将往消费端回写数据。
public class TriDecoder implements Deframer {
private void deliver() {
// We can have reentrancy here when using a direct executor, triggered by calls to
// request more messages. This is safe as we simply loop until pendingDelivers = 0
if (inDelivery) {
return;
}
inDelivery = true;
try {
// Process the uncompressed bytes.
while (pendingDeliveries > 0 && hasEnoughBytes()) {
switch (state) {
case HEADER:
// 请求头已经处理过了,这里不是重复处理,而是把请求体帧的前5个字节获取出来
// 从而得到请求体的真实payload数据 最后将state设置为PAYLOAD。
processHeader();
break;
case PAYLOAD:
// Read the body and deliver the message.
// 判断payload是否是压缩的,是的话解压缩,且把传入参数反序列化为java对象
// 然后执行listener.onRawMessage对应的逻辑,核心代码:ReflectionServerCall#doOnMessage
// 最后将state设置为HEADER。
processBody();
// Since we've delivered a message, decrement the number of pending
// deliveries remaining.
pendingDeliveries--;
break;
default:
throw new AssertionError("Invalid state: " + state);
}
}
// endStream=true,关闭时,才触发
if (closing) {
if (!closed) {
closed = true;
accumulate.clear();
accumulate.release();
// 关闭操作
listener.close();
}
}
} finally {
inDelivery = false;
}
}
}
4.5、消费端-接收响应
响应接收处:TripleHttp2ClientResponseHandler#channelRead0
public final class TripleHttp2ClientResponseHandler extends
SimpleChannelInboundHandler<Http2StreamFrame> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, Http2StreamFrame msg) throws Exception {
// 接收来着服务端的响应,此处响应类型为请求头+结束标识
if (msg instanceof Http2HeadersFrame) {
final Http2HeadersFrame headers = (Http2HeadersFrame) msg;
transportListener.onHeader(headers.headers(), headers.isEndStream());
// 接收来着服务端的消息体
} else if (msg instanceof Http2DataFrame) {
final Http2DataFrame data = (Http2DataFrame) msg;
transportListener.onData(data.content(), data.isEndStream());
} else {
super.channelRead(ctx, msg);
}
}
}
消费者参数的StreamObserver#onNext,#onCompleted回调处:
public class ClientStream extends AbstractStream implements Stream {
@Override
public void onHeader(Http2Headers headers, boolean endStream) {
executor.execute(() -> {
// 判断结束时,结束会走这,不会走onData
if (endStream) {
if (!remoteClosed) {
// 如果接收到了结束,但remoteClosed=false,默认满足。
// 发送new DefaultHttp2ResetFrame(Http2Error.CANCEL)返回
writeQueue.enqueue(CancelQueueCommand.createCommand());
}
// 获取grpc-status的状态,正常为0,执行deframer.close(); --->
// listener.onClose---> 消费端的StreamObserver#onCompleted
onTrailersReceived(headers);
} else {
// 其它非结束,处理请求头
onHeaderReceived(headers);
}
});
}
@Override
public void onData(ByteBuf data, boolean endStream) {
executor.execute(() -> {
if (transportError != null) {
transportError.appendDescription(
"Data:" + data.toString(StandardCharsets.UTF_8));
ReferenceCountUtil.release(data);
if (transportError.description.length() > 512 || endStream) {
handleH2TransportError(transportError);
}
return;
}
if (!headerReceived) {
handleH2TransportError(TriRpcStatus.INTERNAL.withDescription(
"headers not received before payload"));
return;
}
// 还是TriDecoder#deliver拿一套,解析出具体消息内容载体,执行listener#onRawMessage
// ---> listener.onMessage ---> delegate(参数StreanObserver对象).onNext
deframer.deframe(data);
});
}
// 内部类
class ClientTransportListener extends AbstractH2TransportListener implements
H2TransportListener {
void onHeaderReceived(Http2Headers headers) {
// 判断响应状态码是否200,判断是否有异常,校验请求体状态
......
// 创建一个同样的TriDecoder解码器
TriDecoder.Listener listener = new TriDecoder.Listener() {
@Override
public void onRawMessage(byte[] data) {
// 默认实现ObserverToClientCallListenerAdapter#onMessage
// 解析&反序列化,并执行参数流中的消费者自己的StreamObserver#onNext方法。
ClientStream.this.listener.onMessage(data);
}
public void close() {
finishProcess(statusFromTrailers(trailers), trailers);
}
};
deframer = new TriDecoder(decompressor, listener);
ClientStream.this.listener.onStart();
}
}
}
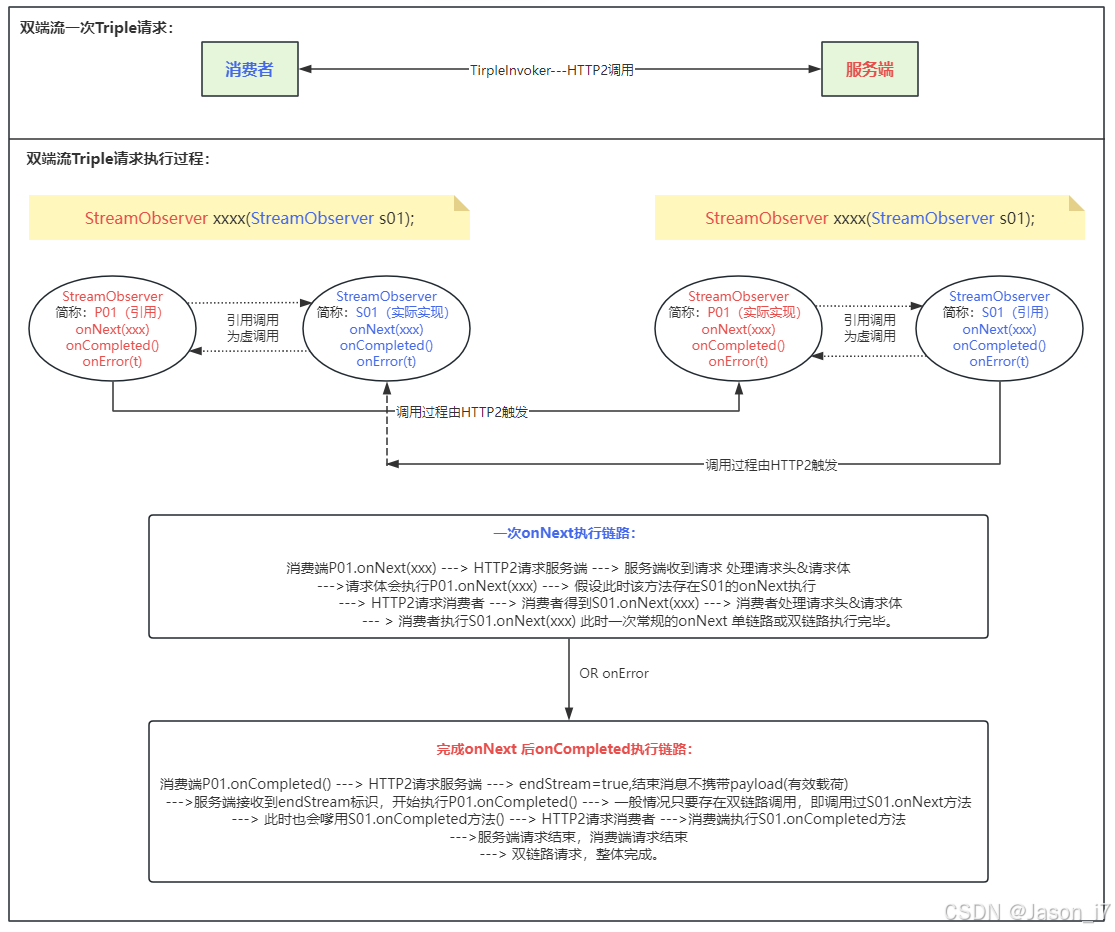
5、Triple请求-响应(双端流)流程图
普通流跟服务端流,主要是invoke执行时机的不同,大致类似。
6、其它事项
6.1、普通流如何实现阻塞调用,其它两者流如何实现异步调用?
UNARY普通流,在TripleInvoker#invokeUnary中只是创建了DeadlineFuture.newFuture放到AsyncRpcResult对象进行中,并没有对前者Future的状态进行改变。所以此时线程还是阻塞的,也应该要是阻塞的,本身就是要获取结果才能继续往下。
那在什么时候被设置完成状态呢?
答案就是,在消费者收到服务端处理完后,发出的消息时,即由TripleHttp2ClientResponseHandler中。
由TriDecoder#deliver—>ClientCall#complete—>listener.onClose—>future.received完成的结果设置,从而恢复线程运行。
而SERVER-STREAM 和 CLIENT-STREAM 都是直接创建了一个已经完成的异步任务返回,因此不会阻塞当前调用线程。
new AsyncRpcResult(CompletableFuture.completedFuture(new AppResponse,xxx));
6.2、为什么说底层都是双端流?
因为普通流的TripleInvoke#invokeUnary和服务端流的TripleInvoke#invokeServerStream方法的底部,也就是执行完call.start得到StreamObserver后,直接调用其onNext发送参数,发完立刻久调用onCompleted完毕了,从而证明也是双端流。
public class TripleInvoker<T> extends AbstractInvoker<T> {
protected Result doInvoke(final Invocation invocation) {
......
AsyncRpcResult result;
try {
switch (methodDescriptor.getRpcType()) {
case UNARY:
result = invokeUnary(methodDescriptor, invocation, call);
break;
case SERVER_STREAM:
result = invokeServerStream(methodDescriptor, invocation, call);
break;
case CLIENT_STREAM:
case BI_STREAM:
result = invokeBiOrClientStream(methodDescriptor, invocation, call);
break;
default:
throw new IllegalStateException("Can not reach here");
}
return result;
} catch (Throwable t) {
......
CompletableFuture<AppResponse> future = new CompletableFuture<>();
future.completeExceptionally(e);
return new AsyncRpcResult(future, invocation);
}
}
AsyncRpcResult invokeUnary(MethodDescriptor methodDescriptor, Invocation invocation,
ClientCall call) {
......
// 这里创建了DeadlineFuture对象用于执行任务
DeadlineFuture future = DeadlineFuture.newFuture(getUrl().getPath(),
methodDescriptor.getMethodName(), getUrl().getAddress(), timeout, callbackExecutor);
final Object pureArgument;
if (methodDescriptor.getParameterClasses().length == 2
&& methodDescriptor.getParameterClasses()[1].isAssignableFrom(
StreamObserver.class)) {
......
} else {
// 获取请求参数
if (methodDescriptor instanceof StubMethodDescriptor) {
pureArgument = invocation.getArguments()[0];
} else {
pureArgument = invocation.getArguments();
}
// 创建结果对象返回
result = new AsyncRpcResult(future, invocation);
result.setExecutor(callbackExecutor);
FutureContext.getContext().setCompatibleFuture(future);
}
// 剩下就是默认双端流,直接onNext发送参数,onCompleted完毕,为什么说底层都是双端流也就是这个原因。
ClientCall.Listener callListener = new UnaryClientCallListener(future);
RequestMetadata request = createRequest(methodDescriptor, invocation, timeout);
final StreamObserver<Object> requestObserver = call.start(request, callListener);
requestObserver.onNext(pureArgument);
requestObserver.onCompleted();
return result;
}
AsyncRpcResult invokeServerStream(MethodDescriptor methodDescriptor, Invocation invocation,
ClientCall call) {
RequestMetadata request = createRequest(methodDescriptor, invocation, null);
StreamObserver<Object> responseObserver = (StreamObserver<Object>) invocation.getArguments()[1];
// 服务端流也是一样,手动发起双端流
final StreamObserver<Object> requestObserver = streamCall(call, request, responseObserver);
requestObserver.onNext(invocation.getArguments()[0]);
requestObserver.onCompleted();
// 对比普通流,这里直接构建已完成的completedFuture对象返回,使得线程不用阻塞
return new AsyncRpcResult(CompletableFuture.completedFuture(new AppResponse()), invocation);
}
AsyncRpcResult invokeBiOrClientStream(MethodDescriptor methodDescriptor, Invocation invocation,
ClientCall call) {
final AsyncRpcResult result;
RequestMetadata request = createRequest(methodDescriptor, invocation, null);
StreamObserver<Object> responseObserver = (StreamObserver<Object>) invocation.getArguments()[0];
final StreamObserver<Object> requestObserver = streamCall(call, request, responseObserver);
// 对比前两者,这里没有手动调用requestObserver,也是交给业务即消费者触发。
// 异步的原因也是直接构建了completedFuture返回。
result = new AsyncRpcResult(
CompletableFuture.completedFuture(new AppResponse(requestObserver)), invocation);
return result;
}
}
6.3、线程模型导致的onNext BUG
BUG场景:
服务端流或者双端流,在调用消费者的StreamObserver执行onNext时,需要等待整个方法执行结束后,才能执行onNext方法。比如下方的案例中,正常应该是onNext回调消费端后,3秒再发送下一个onNext回调,直到结束。但在3.0.7版本中却是等待所有的sleep(整个invoke方法)结束,也就是9秒后消费端一口气拿到了所有onNext的结果。
@Override
public void sayHelloServerStream(String request, StreamObserver<String> response) {
try {
response.onNext(System.currentTimeMillis() + "服务端serverStream---123");
Thread.sleep(3000L);
response.onNext(System.currentTimeMillis() + request);
Thread.sleep(3000L);
response.onNext(System.currentTimeMillis() + "服务端serverStream---456");
Thread.sleep(3000L);
response.onCompleted();
} catch (Exception e) {}
}
原因分析:
首先是在ServerStream创建的时候,构造方法创建了一个SerializingExecutor(串行)的线程池,赋值给了this.executor对象。
然后整个sayHelloServerStream方法的执行,也就是invoke执行时,会把当前的invoke交给executor对象执行。其次所有回调事件也是依靠executor进行执行。
问题其实到这就出现了,因为都是公用SerializingExecutor对象,所以在invoke执行时,方法内onXXX的调用,后者就只能等到invoke彻底执行完整个逻辑,才有开始执行的机会(execute开头会CAS判断是否有执行资格)。所以会出现上述等待9s之后,统一返回的情景。
public class ServerCallToObserverAdapter<T> extends CancelableStreamObserver<T> implements
ServerStreamObserver<T> {
@Override
public void onNext(Object data) {
if (isTerminated()) {
throw new IllegalStateException(
"Stream observer has been terminated, no more data is allowed");
}
// 具体实现由executor.execute执行
call.writeMessage(data);
}
@Override
public void onError(Throwable throwable) {
final TriRpcStatus status = TriRpcStatus.getStatus(throwable);
// 参考下方
onCompleted(status);
}
public void onCompleted(TriRpcStatus status) {
if (isTerminated()) {
return;
}
// 也是由executor.execute执行
// executor.execute(() -> serverStream.close(status, trailers));
call.close(status, attachments);
setTerminated(true);
}
}
onNext的call.writeMessage执行逻辑:
public abstract class ServerCall {
public void writeMessage(Object message) {
// 个人理解:
// shang
// 引用网上的解释:
// 这也就形成了executor为 SerializingExecutor(SerializingExecutor(ThreadPoolExecutor));
// 内部的SerializingExecutor(ThreadPoolExecutor)就是用来请求数据的
final Runnable writeMessage = () -> doWriteMessage(message);
executor.execute(writeMessage);
}
}
SerializingExecutor线程池执行逻辑:
public final class SerializingExecutor implements Executor, Runnable {
@Override
public void execute(Runnable r) {
// invoke的执行,跟onNext的执行,甚至是所有onXX都是调用的这里,加入队列,等待执行
runQueue.add(r);
schedule(r);
}
private void schedule(Runnable removable) {
// 第一次满足,后面必须等方法执行完,也就是下面的run方法执行成功,才会把标记atomicBoolean改为false
if (atomicBoolean.compareAndSet(false, true)) {
boolean success = false;
try {
// 用内部的单线程,来执行任务
executor.execute(this);
success = true;
} finally {
// It is possible that at this point that there are still tasks in
// the queue, it would be nice to keep trying but the error may not
// be recoverable. So we update our state and propagate so that if
// our caller deems it recoverable we won't be stuck.
if (!success) {
if (removable != null) {
runQueue.remove(removable);
}
atomicBoolean.set(false);
}
}
}
}
@Override
public void run() {
Runnable r;
try {
// 依次拿任务
while ((r = runQueue.poll()) != null) {
try {
// 执行任务
r.run();
} catch (RuntimeException e) {
LOGGER.error("Exception while executing runnable " + r, e);
}
}
} finally {
// 解锁,使得schedule方法内部能重新执行execute
atomicBoolean.set(false);
}
if (!runQueue.isEmpty()) {
// we didn't enqueue anything but someone else did.
schedule(null);
}
}
}
解决方案:
将invoke与onXXX的执行用不同的线程来处理,即打破公用SerializingExecutor对象这一点即可。
更新:Dubbo在3.2.15版本已调整为类似策略,去掉了线程池包裹调度。
public abstract class ServerCall {
public void writeMessage(Object message) {
final Runnable writeMessage = () -> doWriteMessage(message);
executor.execute(writeMessage);
}
// 方法修改为即可。
public void writeMessage(Object message) {
// 直接发送,添加message到队列,本身就是异步的,很快就会返回
doWriteMessage(message);
}
}
7、总结
- 底层网络容器默认为Netty,基于gRPC和HTTP2的协议,加入了Dubbo一些自己的处理特性和优化。
- 基于HTTP2的请求响应方式,设置请求前沿标记,针对请求头帧/数据帧,响应头帧/数据帧进行的一系列处理。
- Triple协议首先根据三种不同的请求方式,创建三种不同的Listener,每个Listener有自己的invoke处理逻辑,回调时机。
- 本质上也都是双端流,只不过普通流跟服务端流的回调逻辑被隐藏在了框架底部。
- 服务端发送实现:ServerCall,流处理ServerStream,内部依托ServerTransportObserver实现主要逻辑处理。
- 消费者发送实现:ClientCall,流处理ClientStream,内部依托ClientTransportListener实现主要逻辑处理。
- 5和6均为第3点中提到的listener,统一继承AbstractH2TransportListener,并实现接口H2TransportListener。
- TripleHttp2FrameServerHandler处理请求,TripleHttp2ClientResponseHandler处理响应。
over。

















 4359
4359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









