 Score-CAM:无梯度视觉解释的创新方法
Score-CAM:无梯度视觉解释的创新方法





【写在前面】
最近,人们越来越关注卷积神经网络的内部机制,以及网络做出特定决策的原因。在本文中,作者基于类激活映射开发了一种新颖的事后视觉解释方法,称为Score-CAM。与以前的基于类激活映射的方法不同,Score-CAM通过在目标类上的前向传递分数获得每个激活图的权重来摆脱对梯度的依赖,最终结果是通过权重和激活图的线性组合获得的。作者证明Score-CAM在解释决策过程中具有更好的视觉性能和公平性。本文的方法在识别和定位任务上都优于以前的方法。
1. 论文和代码地址

Score-CAM: Score-Weighted Visual Explanations for Convolutional Neural Networks
论文地址:https://ieeexplore.ieee.org/document/9150840[1]
代码地址:https://github.com/haofanwang/Score-CAM[2]
2. Motivation
对深度神经网络 (DNN) 的解释通过暴露某些可由人类解释的推理方面来提高透明度。在解释中,可视化一定数量的兴趣 (例如输入特征的重要性或学习的权重) 已成为最直接的方法。由于空间卷积是图像和语言处理的最先进模型的常见组成部分,因此许多方法专注于建立卷积和卷积神经网络 (CNNs) 的更好解释。具体而言: 梯度可视化,扰动,类激活图 (CAM) 是三种广泛采用的方法。
基于梯度的方法将目标类的梯度反向传播到输入,以突出显示影响预测的图像区域。Saliency Map用目标类相对于输入图像的分数作为解释。其他作品基于并操纵该梯度,以在视觉上锐化结果。这些图通常质量低且有噪声。基于扰动的方法扰动原始输入,以观察模型预测的变化。为了找到最小区域,这些方法通常需要额外的正则化,并且计算量大。
基于CAM的解释通过卷积层激活图的线性加权组合,为单个输入提供视觉解释。CAM创建局部视觉解释,但对架构敏感;需要全局池层。Grad CAM及其变体,例如Grad CAM++,将CAM推广到没有全局池层的模型。在这项工作中,作者回顾了梯度信息在梯度CAM中的使用,并讨论了为什么梯度可能不是推广CAM的理想方法。此外,为了解决基于梯度的CAM变化的局限性,作者提出了一种新的事后视觉解释方法,称为ScoreCAM,其中激活图的重要性来自其突出显示的输入特征对模型输出的贡献,而不是局部灵敏度测量,即梯度信息。本文的贡献是:
(1) 作者提出了一种新的无梯度视觉解释方法Score-CAM,它弥合了基于扰动的方法和基于CAM的方法之间的差距,并以直观易懂的方式推导了激活图的权重。
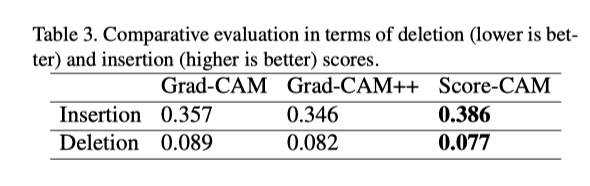
(2) 作者使用平均下降/平均增加和删除曲线/插入曲线指标定量评估了分数CAM在识别任务上生成的显著性图,并表明分数CAM更好地发现了重要特征。
(3) 作者定性地评估了可视化和定位性能,并在这两项任务上取得了更好的结果。最后,描述了Score CAM作为分析模型问题的调试工具的有效性。
3. 方法
3.1. Methodology
与以前的方法不同,前者使用流入最后一个卷积层的梯度信息来表示每个激活图的重要性,作者将重要性纳入置信度的增加。
Increase of Confidence
给定一个取输入向量 并输出标量Y的一般函数 。对于已知基线输入 , 向Y的方向的贡献 是通过将 中的第i项替换为 来改变输出:
其中, 是具有相同形状 的向量。
Channel-wise Increase of Confidence (CIC)
给定一个CNN模型Y=f(X),它接受一个输入X并输出一个标量Y。我们在f中选取一个内部卷积层l,并将相应的激活作为A。用 表示 的第k个通道。对于已知的基线输入 , 对Y的贡献定义为:
Score-CAM
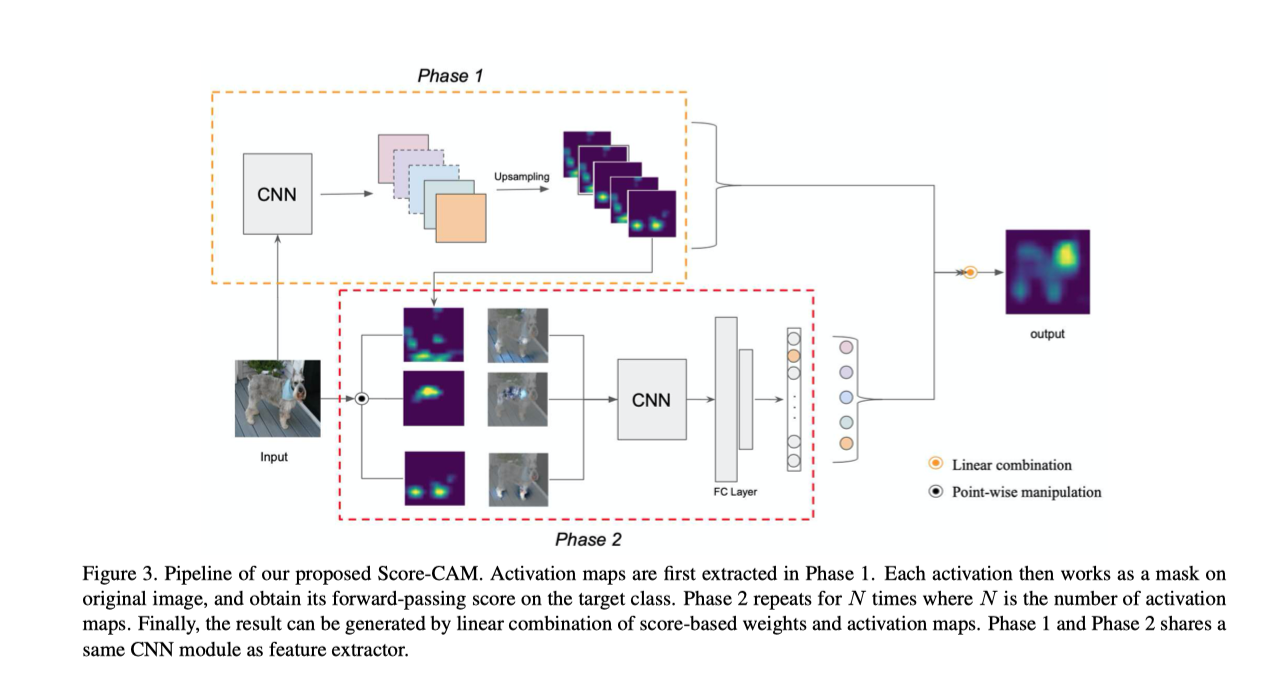
考虑模型f中的卷积层l,给定一类感兴趣的c,Score-CAM 可以定义为:
其中 表示激活图 的CIC分数。
作者还将ReLU应用于map的线性组合,因为只对对感兴趣的类别有积极影响的特征感兴趣。由于权重来自与目标类上的激活映射对应的CIC分数,分数CAM摆脱了对梯度的依赖。虽然最后一个卷积层是更可取的选择,因为它是特征提取的终点,但在本文的框架中可以选择任何中间卷积层。

3.2. Normalization on Score
每个前向传递神经网络是独立的,每个前向传播的分数幅度是不可预测且不固定的。归一化后的相对输出值(后softmax)比绝对输出值(前softmax)更适合测量相关性。因此,在分数CAM中,作者将权重表示为后softmax值,以便分数可以重新缩放到固定范围。

由于每次预测的范围不同,是否使用softmax会产生差异。上图显示了一个有趣的发现。模型预测输入图像为“狗”,无论采用哪种类型的分数,都可以正确突出显示。但对于目标类“cat”,如果使用pre-softmax logit作为权重,则分数CAM同时突出显示“dog”和“cat”区域。相反,尽管“猫”的预测概率低于“狗”的预测概率,但使用softmax的分数CAM可以很好地区分两个不同的类别。归一化操作使分数CAM具有良好的类判别能力。
4.实验
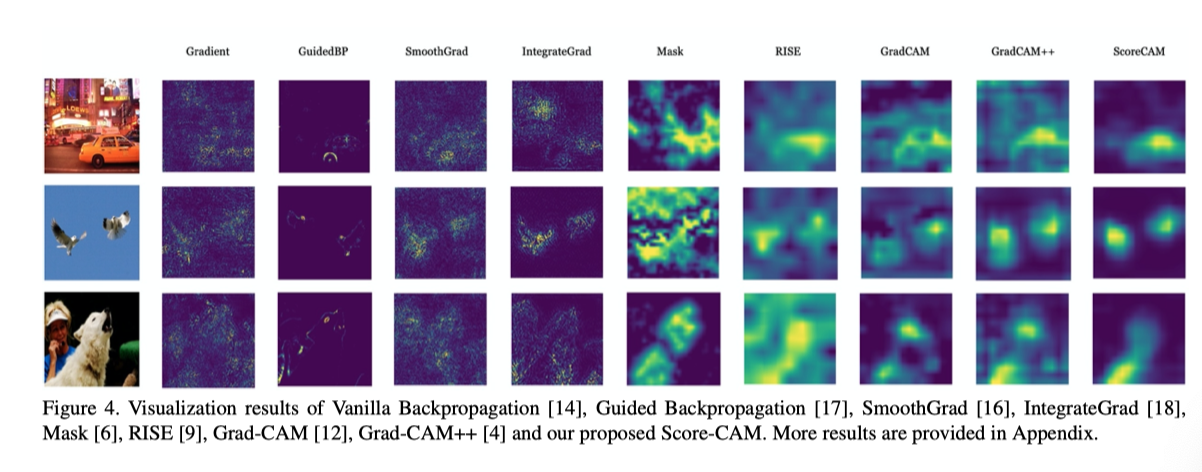
不同可解释方法的可视化结果

类判别结果。

识别结果。

多目标结果。

基于能量的定点博弈的比较评价。
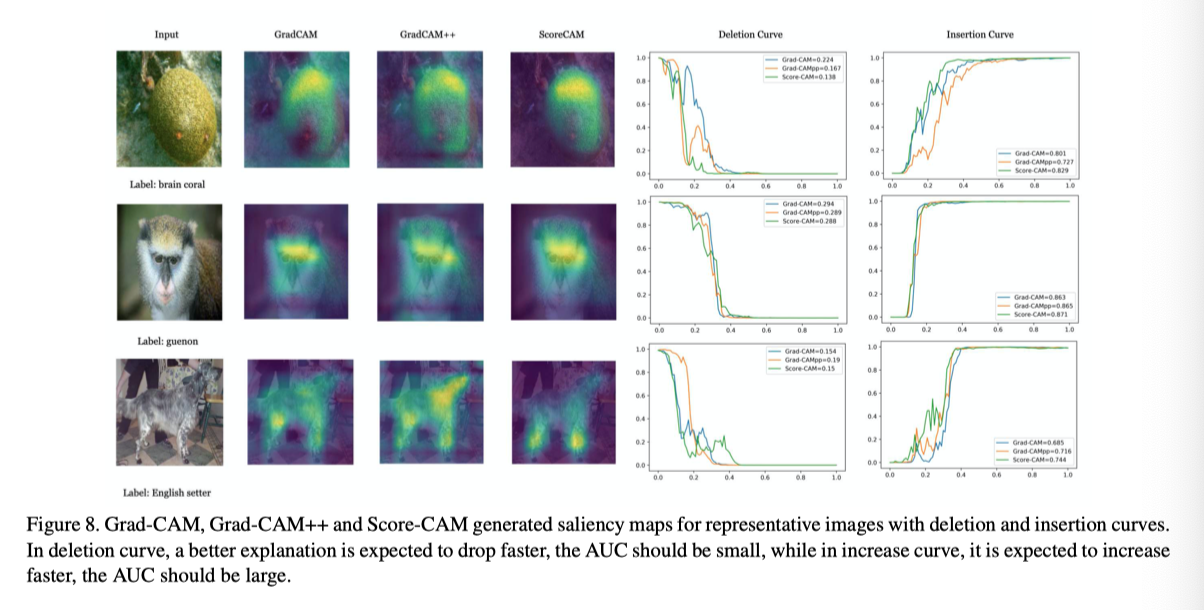
不同方法的显著性map。
检测结果。

随机抽样的检查结果。

左侧由未微调VGG16生成,分类精度为22.0%,右侧由微调VGG16生成,分类精度为90.1%。结果表明,随着分类精度的提高,显著性图变得更加集中。

左栏是输入示例,中间是显著图-预测类(person),右栏是显著图-目标类(bicycle)。
5. 总结
作者提出了一种新的Cam变体Score Cam,用于视觉解释。分数CAM使用每个激活图权重的置信度增加,消除了对梯度的依赖,并具有更合理的权重表示。本文对动机、实施、定性和定量评估进行了深入分析。本文的方法在识别和定位评估指标方面优于所有以前基于CAM的方法和其他最先进的方法。
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
加入交流群,请添加小助手wx:FightngCV666
参考资料
https://ieeexplore.ieee.org/document/9150840: https://ieeexplore.ieee.org/document/9150840
[2]https://github.com/haofanwang/Score-CAM: https://github.com/haofanwang/Score-CAM
本文由 mdnice 多平台发布


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









