





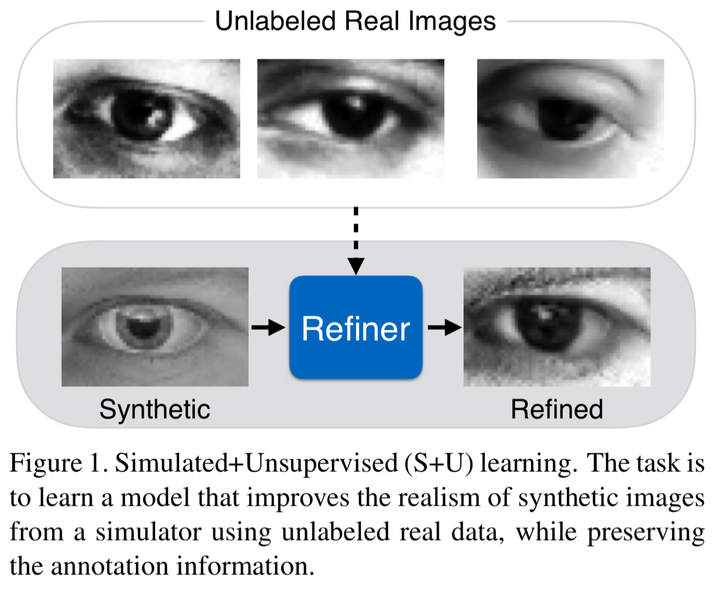
 本文介绍了一种名为S+U Learning的方法,旨在利用未标记的真实图像改进合成数据的质量,使其更接近真实世界图像,同时保持原有的注释信息。通过引入自我正则化、局部对抗损失和历史细化图像更新等创新点,该方法在MPIIGaze数据集上实现了状态级性能。
本文介绍了一种名为S+U Learning的方法,旨在利用未标记的真实图像改进合成数据的质量,使其更接近真实世界图像,同时保持原有的注释信息。通过引入自我正则化、局部对抗损失和历史细化图像更新等创新点,该方法在MPIIGaze数据集上实现了状态级性能。
视频链接:https://www.bilibili.com/video/BV1yz4y1X7Jd/
1、看abstract时候的问题(看其他部分时候的回答)
1.adversarial network和GANs有什么区别?论文所做的工作和GANs的区别在哪里?
原始GANs生成的图片和真实图片差距比较大,因此用于训练的结果会不太好。而本文的方法更像是一个Refiner,根据unllabeled real data,去给synthetic data加细节,是的synthetic data更接近真实图片,并且能够保留synthetic data的annotation信息。
2、创新点
(i) a ‘self-regularization’ term
(ii) a local adversarial loss
(iii) updating the discriminator using a history of refined images.
3、做了什么
目前深度学习很多都是用生成的数据进行训练,而不是真实的数据,但是这么做就可能不能使模型拿到非常好的效果,因为生成数据和真实数据还是有一定差别的。因此,本文所做的就是提出了S+U learning,使用unlabeled real data去生成图片,在MPIIGaze是实现SOTA
4、难点
同创新点
5、怎么做
使用很多unlabeled real images yi ∈ Y去学习一个模型Rθ(x),去生成synthetic images x,其中损失函数。然后学习使loss值最小的θ。(损失函数如下,有两个部分组成,第一部分是加realism到syhthetic image中,第二部分是保留annotation infomation)
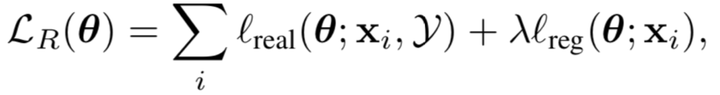
5.1. Adversarial Loss with Self-Regularization
建立一个adversarial discriminator network,使得结果能够不能区分real image和high score refined image。根据GAN的过程,建立2个网络:refiner network, Rθ和 the discriminator network, Dφ。损失函数:
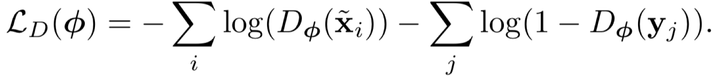
realism loss定义:
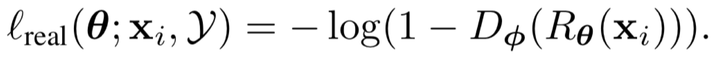
另外,除了加realism信息,还需要加保留synthetic imgae中原来的标注信息
5.2. Local Adversarial Loss
refiner network需要能够通过模型学习到真实图片的特征,但始终用tarin单个strong discriminator network时,模型会过于注重单张图片的特征。因此本文建立一个discriminator network来独立的对每个patch的图片进行分类。
具体实现为,本文建立一个输出为w*h的fully convolutional network,其中w*h时图片中local patches的数量。
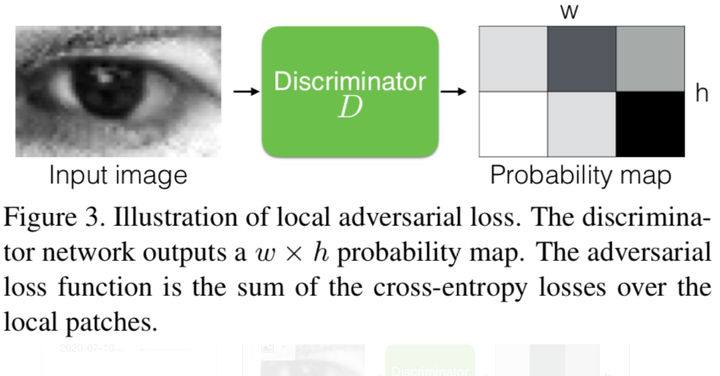
5.3. Updating the Discriminator using a History of Refined Images
discriminator network有一个问题时,它只会关注latest的refined images,这就会导致两个问题:第一是adversarial training时会有分歧;第二是refiner network会重新加入那些已经加入的但是被网络忘记的real image的特征。因此本文在update discriminator的时候使用到了refined images的历史信息。
6、结果怎么样
效果:
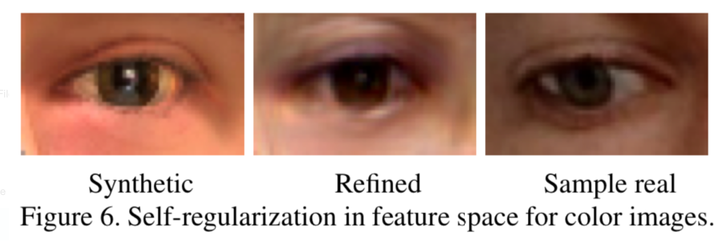

训练结果对比:

7、备注(写自己的问题,感受)
1.The GAN framework learns two networks (a generator and a discriminator) with competing losses. The goal of the generator network is to map a random vector to a realistic image, whereas the goal of the discriminator is to distinguish the generated from the real images.

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









