







 本文介绍了PaddleClas图像分类库,包括其在柠檬分类任务中的应用,强调了移动端轻量级模型的选择。内容涵盖PaddleClas的功能、模型库、数据集准备、迁移学习概念以及模型训练与评估。
本文介绍了PaddleClas图像分类库,包括其在柠檬分类任务中的应用,强调了移动端轻量级模型的选择。内容涵盖PaddleClas的功能、模型库、数据集准备、迁移学习概念以及模型训练与评估。
图像识别基础第二课
课程链接:
本次课由李老师进行讲解
本节课课程继续以柠檬分类为例,主要介绍的是peddleclas 图像分类的模型库。
PaddleClas作为飞桨的一个图像分类套件,已经为大家把所有的内容都写好了,只需要大家选择模型、并适配自己的数据集即可
###################################################
PaddleClas 是什么?
PaddleClas是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。PaddleClas提供了基于图像分类的模型训练、评估、预测、部署全流程的服务,方便大家更加高效地学习图像分类。
下面将从PaddleClas模型库概览、特色应用、快速上手、实践应用几个方面介绍PaddleClas实践方法:
PaddleClas模型库概览:概要介绍PaddleClas有哪些分类网络结构和预训练模型。
PaddleClas柠檬竞赛实战:重点介绍数据增广方法。
柠檬数据集的要求是要在轻量级上的移动端来部署
因此需要模型轻量级
可以选用paddleclas模型库中的移动端模型
(模型需要被部署在树莓派上)
https://paddleclas.readthedocs.io/zh_CN/latest/models/Mobile.html
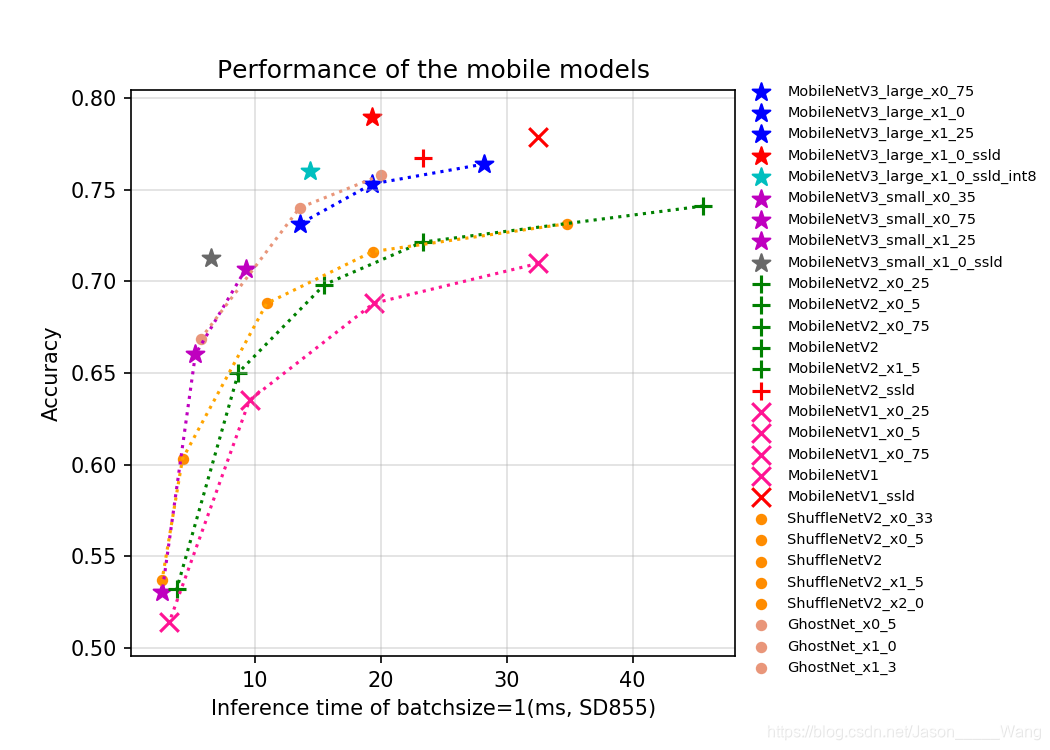
可以看到,基于移动端的网络模型的精准度都不是很高,基本最高性能在80%左右档次的准确率。
安装paddleclas 库
前置条件
- 安装Python3.5或更高版本版本。
- 安装PaddlePaddle 1.7或更高版本,具体安装方法请参见快速安装。由于图像分类模型计算开销大,推荐在GPU版本的PaddlePaddle下使用PaddleClas。
- 下载PaddleClas的代码库。
cd path_to_clone_PaddleClas
以下二者任选其一
git clone https://github.com/PaddlePaddle/PaddleClas.git
git clone https://gitee.com/paddlepaddle/PaddleClas.git
- 安装Python依赖库。
- Python依赖库在requirements.txt中给出。(本地)
pip install --upgrade -r requirements.txt
设置PYTHONPATH环境变量(本地)
export PYTHONPATH=path_to_PaddleClas:$PYTHONPATH
准备数据集
一般图像分类的数据集的目录都是把相同类型的图像放在一个目录下面
比如:前天所使用的蝴蝶数据集
但是网络需要的是图片路径+图像标签的输入形式
而且训练集和预测集也需要作区分
PaddleClas数据准备文档提供了ImageNet1k数据集以及flowers102数据集的准备过程。当然,如果大家希望使用自己的数据集,则需要至少准备以下两份文件。
训练集图像,以图像文件形式保存。
训练集标签文件,以文本形式保存,每一行的文件都包含文件名以及图像标签,以空格隔开。下面给出一个示例。
ILSVRC2012_val_00000001.JPEG 65
...
如果需要在训练的时候进行验证,则也同时需要提供验证集图像以及验证集标签文件。
以训练集配置为例,配置文件中对应如下
TRAIN: # 训练配置
batch_size: 32 # 训练的batch size
num_workers: 4 # 每个trainer(1块GPU上可以视为1个trainer)的进程数量
file_list: "./dataset/flowers102/train_list.txt" # 训练集标签文件,每一行由"image_name label"组成
data_dir: "./dataset/flowers102/" # 训练集的图像数据路径
shuffle_seed: 0 # 数据打散的种子
transforms: # 训练图像的数据预处理
- DecodeImage: # 解码
to_rgb: True
to_np: False
channel_first: False
- RandCropImage: # 随机裁剪
size: 224
- RandFlipImage: # 随机水平翻转
flip_code: 1
- NormalizeImage: # 归一化
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage: # 通道转换
其中file_list即训练数据集的标签文件,data_dir是图像所在的文件夹。
一般来讲没有完美适配模型的数据集,所以基本上或多或少都需要自己对数据集做一些调整和整理。
在paddlepaddle中,也可以用PaddleX API一键切分数据集
(paddle是一个简化上手工具,甚至支持图形化开发)
迁移学习
什么是迁移学习?为什么要用迁移学习
迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
模型训练与评估
在自己的数据集上训练分类模型时,更推荐加载预训练进行微调。
预训练模型使用以下方式进行下载。
python tools/download.py -a MobileNetV3_small_x1_0 -p ./pretrained -d True
更多的预训练模型可以参考这里:https://paddleclas.readthedocs.io/zh_CN/latest/models/models_intro.html
PaddleClas 提供模型训练与评估脚本:tools/train.py和tools/eval.py


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









