 强化学习基础
强化学习基础





 本文介绍了强化学习的基本概念,包括值函数、状态值函数和动作值函数等,并探讨了策略估计、策略改进及迭代的方法。此外还讲解了蒙特卡罗方法、时间差分学习及其在Q-learning和Sarsa算法中的应用。
本文介绍了强化学习的基本概念,包括值函数、状态值函数和动作值函数等,并探讨了策略估计、策略改进及迭代的方法。此外还讲解了蒙特卡罗方法、时间差分学习及其在Q-learning和Sarsa算法中的应用。
值函数(value function)


常用的公式:
- 表示可以对未来的期望打出一定的折扣,着重考虑一些固定的reward。
- 当 γ \gamma γ的值为0时为只考虑立即不考虑长期;当值为1时立即和长期考虑同等重要。
状态值函数(state value function)和动作值函数(action value function Q函数)是不同的

其中的a是给定的,而不是像动作值函数中a是由
π
(
s
)
\pi(s)
π(s)计算得来的
强化学习的目的就是求解马尔可夫决策过程(MDP)的最优策略,使其在任意初始状态下,都能获得最大的
V
π
(
s
)
V^\pi(s)
Vπ(s)值
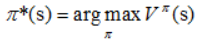 因为V和Q的关系,所以显而易见
因为V和Q的关系,所以显而易见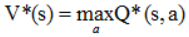 从所有的可选动作选择的Value值中选择最大的一个Value值
从所有的可选动作选择的Value值中选择最大的一个Value值

策略估计(Policy Evaluation)
拓展到一般情况,在某个策略
π
\pi
π下,有可能可采取的动作不止一种。例如在之前的走迷宫例子中,可以在某一格选择走不同方向,利用如下的公式进行更新Value function

总体来说更新的过程是通过对未来的状态下的Value function值进行折扣,从而对现在的value function进行更新
从而更新的方式有两种:
- 先将第k次迭代的V值存储到一个数组中,在第k+1次迭代中使用这一个数组中的数据,将k+1次迭代的内容存到另一个数组中

- 另一种方法是不断更新这个数组,在第k+1次迭代中,将使用最新的数据
 能够及时获取新值,能更快的收敛
能够及时获取新值,能更快的收敛
策略改进(Policy Improvement)
策略改进定理:对于一个
π
∗
\pi^*
π∗,如果其所有的状态s,都有
Q
π
(
s
,
π
∗
(
s
)
)
≥
V
π
(
s
)
Q^\pi(s,\pi^*(s))≥V^\pi(s)
Qπ(s,π∗(s))≥Vπ(s),那么则有策略
π
∗
\pi^*
π∗必然比
π
\pi
π优
使用贪心进行不断迭代,从而得到策略改进
策略迭代(Policy Iteration)

值迭代(Value Iteration)
值迭代是通过直接从可选的动作空间中选择最大的V值,而不需要通过策略
π
\pi
π来得到最大的V值
在获得最大的V值之后,从而利用value function得到最后的最优
π
∗
\pi^*
π∗

蒙特卡罗方法
蒙特卡罗方法就是依靠样本的平均回报来解决增强学习问题的
蒙特卡罗策略估计(Monte Carlo Policy evalution)
有两种方法,first-visit MC methods和every-visit MC methods
- 用来计算平均回报的样本仅为一个回合中第一次访问状态s的样本
- 为一个回合中所有访问状态s的样本
持续探索(Maintaining Exploration)
如果在计算Q值函数的时候,前两个动作已经有了大小区分,那么在结果上将会执行前两个action的动作,而不会更新后面两个动作的Q值函数了,所以需要一个ε-greedy policy,即在所有的状态下,用1-ε的概率来执行当前的最优动作,ε的概率来执行其他动作
最终通过减小ε来收敛
时间差分学习(Temporal-Difference learning, TD learning)

TD Learing思想
本质上是将迭代的函数发生了变化,用实际值和估计值的差来当作学习的内容


Q-learning和Sarsa比较
Sarsa算法更新的时候是通过Q值函数,而不是通过Value function,利用的思想就是TD思想,on-policy表示在决定
Q
(
s
t
+
1
,
a
t
+
1
)
Q(s_{t+1},a_{t+1})
Q(st+1,at+1)时需要根据
π
\pi
π策略决策

Q-learning算法更新的时候是通过直接取所有action中的max来实现off-policy

总结来自------Kintoki

















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









