






 本文详细介绍了如何使用Sqoop进行数据迁移,包括从MySQL导入数据到HDFS、Hive、Hbase,以及反向将HDFS、Hive、Hbase的数据导回MySQL。在实践中,遇到了权限问题、通信链接失败、jar包缺失等问题,并给出了相应的解决方案。重点讲解了授权设置、错误排查和所需jar包的添加。
本文详细介绍了如何使用Sqoop进行数据迁移,包括从MySQL导入数据到HDFS、Hive、Hbase,以及反向将HDFS、Hive、Hbase的数据导回MySQL。在实践中,遇到了权限问题、通信链接失败、jar包缺失等问题,并给出了相应的解决方案。重点讲解了授权设置、错误排查和所需jar包的添加。
导入:MySQL==> HDFS、Hive、Hbase
导出:HDFS、Hive、Hbase ==> MySQL
一、安装,配置环境
1、下载压缩包
2、配置文件sqoop.env.sh
3、验证:bin/sqoop help
4、拷贝jdbc驱动到sqoop/lib
5、连接MySQL
[root@master sqoop-1.4.7]# ./bin/sqoop list-databases --connect jdbc:mysql://master:3306/ --username root --password 111111
二、实践
1、启动MySQL:
mysql -uroot -p1111112、创建员工表
-- 创建公司company数据库
create database company
-- 在公司company数据库下创建员工表staff
create table company.staff(id int(4) primary key not null auto_increment,
name varchar(255),
sex varchar(255));
-- 在员工表中插入数据
insert into company.staff(name,sex) values('Thomes','Male');
insert into company.staff(name,sex) values('Catalina','Female');全量数据导入:
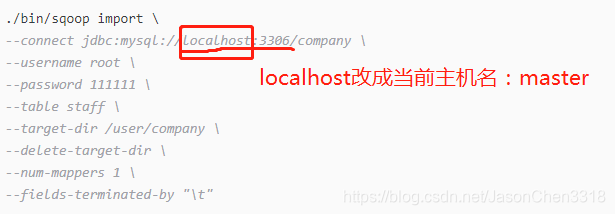
./bin/sqoop import \
--connect jdbc:mysql://localhost:3306/company \
--username root \
--password 111111 \
--table staff \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"错误一:
Error: java.lang.RuntimeException: java.lang.RuntimeException: java.sql.SQLException: null, message from
server: "Host 'slave1' is not allowed to connect to this MariaDB server"
表示该对象不是远程对象,不能通过该对象远程访问数据
方案一:改表:
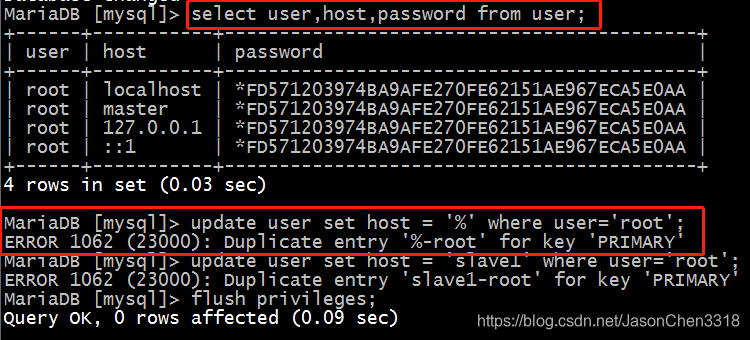
use mysql ;select user,host,password from user;
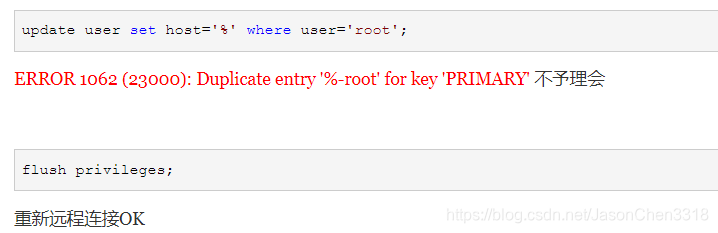
update user set host = '%' where user='root';
执行方法一时:遇到ERROR 1062 (23000): Duplicate entry '%-root' for key 'PRIMARY'
解决方法:不予理会,直接执行 flush privileges;然后重连数据库
方法二没用,暂时不知道是否能解决问题:
方案二:授权法:
例如,你想myuser使用mypassword从任何主机连接到mysql服务器的话。
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
如果你想允许用户myuser从ip为192.168.1.3的主机连接到mysql服务器,并使用mypassword作为密码
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'192.168.1.3' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
错误2:
解决完上述问题之后,再次执行导入命令,得到结果:结果存在HDFS目录上:

二、查询导入
./bin/sqoop import \
--connect jdbc:mysql://master:3306/company \
--username root \
--password 111111 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select name,sex from staff where id <= 1 and $CONDITION'
-- 使用双引号需要使用 \ 在$CONDITION前 进行转义
--query "select name,sex from staff where id <= 1 and \$CONDITION"三、导入指定的列
./bin/sqoop import \
--connect jdbc:mysql://master:3306/company \
--username root \
--password 111111 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns id,sex \
--table staff四、关键字筛选
./bin/sqoop import \
--connect jdbc:mysql://master:3306/company \
--username root \
--password 111111 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--table staff \
--where "id=1"五、关键字和指定关键字同时使用
./bin/sqoop import \
--connect jdbc:mysql://master:3306/company \
--username root \
--password 111111 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--table staff \
--columns id,sex \
--where "id=1"二、MySQL数据导入Hive
数据先上传至HDFS的 /user/root/staff 目录(系统默认路径:/user/系统目录(root)/表名(staff))下,
然后再存入hive表(hive表对应的HDFS仓库位置:/user/hive/warehouse/staff_hive)
./bin/sqoop import \
--connect jdbc:mysql://master:3306/company \
--username root \
--password 111111 \
--table staff \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table staff_hive执行遇到的坑:
坑一:
java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
问题原因:缺少jar包
问题解决:复制hive lib 包下面的hive-common-1.1.0-cdh5.7.0.jar 至sqoop lib 包下
坑二:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hive/shims/ShimLoader
问题原因:缺少jar包
问题解决:拷贝 hive lib 包下 hive-exec-1.1.0-cdh5.7.0.jar 至 sqoop 的lib包下
三、MySQL数据导入Hbase
./bin/sqoop import \
--connect jdbc:mysql://master:3306/company \
--username root \
--password 111111 \
--table staff \
--columns "id,name,sex" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_company" \
--num-mappers 1 \
--split-by id坑一:
Sqoop HBase导入:java.lang.NoSuchMethodError:org.apache.hadoop.hbase.HTableDescriptor.addFamily
问题分析:版本不兼容;sqoop1.4.6 只支持Hbase1.0及其以前的版本
问题解决:手动创建Hbase表,如下:
hbase(main):001:0> create 'hbase_company','info'
然后重新执行sqoop语句:
./bin/sqoop import \
--connect jdbc:mysql://master:3306/company \
--username root \
--password 111111 \
--table staff \
--columns "id,name,sex" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_company" \
--num-mappers 1 \
--split-by id四、Hive或HDFS数据导入MySQL
./bin/sqoop export \
--connect jdbc:mysql://master:3306/company \
--username root \
--password 111111 \
--table staff \
--num-mappers 1 \
--export-dir /user/hive/warehouse/staff_hive \
--input-fields-terminated-by "\t"五、脚本执行
vi jobs/sqp.opt
./bin/sqoop export \
--connect
jdbc:mysql://master:3306/company
--username
root
--password
111111
--table
staff
--num-mappers
1
--export-dir
/user/hive/warehouse/staff_hive
--input-fields-terminated-by
"\t"
--执行:
[root@master sqoop-1.4.6]# ./bin/sqoop --options-file /usr/local/src/test4/sqp_job/sqp.opt坑一:MySQL在centos7中重设密码:
"Host 'xxx' is not allowed to connect to this MySQL server":

















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









