






 本文介绍了如何使用Python爬取2345天气网的气象数据,特别是PM2.5相关数据。通过分析网页的Network和Headers,找到请求的JSON数据链接,从而提取所需信息。提供的代码包含详细注释,可按需调整年份和城市获取不同数据,并展示了保存数据到Excel文件的结果。
本文介绍了如何使用Python爬取2345天气网的气象数据,特别是PM2.5相关数据。通过分析网页的Network和Headers,找到请求的JSON数据链接,从而提取所需信息。提供的代码包含详细注释,可按需调整年份和城市获取不同数据,并展示了保存数据到Excel文件的结果。
** python爬取2345天气网气象数据**
由于科研需要,我需要获取有关PM2.5数据的气象要素,因此准备爬取2345天气网的数据,参考了网上方法,很多都介绍的不都详细,有的都失效了,因此这里简单介绍一下我的方法,供大家参考(方法不唯一)!
话不多说,先上结果:

首先我研究的对象是北京,因此我搜索 北京的天气数据,如图所示:
 然后我打开审查元素,点击Network,发现54511_202003.js这里存在我们所需要的json数据,如下图因此我们只需要能够获取到这里的json数据即可。
然后我打开审查元素,点击Network,发现54511_202003.js这里存在我们所需要的json数据,如下图因此我们只需要能够获取到这里的json数据即可。

点击Headers,如下图

发现Request URL就是我们需要的json数据的链接,可以点击该链接看看,如下:

事实证明我们的猜想是对的,因此,我们只要在这个json数据里提取我们所需要的数据即可。
附上我的全部代码:
import requests
import pandas as pd
import re
months = ["01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12"]
years = [2017, 2018, 2019,2020]
city = [54511] # 北京代码54511,也可以设置其他城市
index_ = ['MaxTemp','MinTemp', 'WindDir', 'Wind', 'Weather'] # 选取的气象要素
data = pd.DataFrame(columns=index_) # 建立一个空dataframe
for y in years:
for m in months:
for c in city:
# 找到json格式数据的url
url = "http://tianqi.2345.com/t/wea_history/js/"+str(y)+str(m)+'/'+str(c)+"_"+str(y)+str(m)+".js"
print(url)
response = requests.get(url=url)
if response.status_code == 200: # 防止url请求无响应
response2 = response.text.replace("'", '"') # 这一步可以忽略
# 利用正则表达式获取5个气象要素(方法不唯一)
date = re.findall("[0-9]{4}-[0-9]{2}-[0-9]{2}", response2)[:-2] # 去除最后两个无关的数据
mintemp = re.findall('yWendu:"(.*?)℃', response2)
maxtemp = re.findall('bWendu:"(.*?)℃', response2)
winddir = re.findall('fengxiang:"([\u4E00-\u9FA5]+)', response2)
wind = re.findall('fengli:"(\d)[\u4E00-\u9FA5]+', response2)
weather = re.findall('tianqi:"([[\u4E00-\u9FA5]+)~?', response2)
data_spider = pd.DataFrame([maxtemp,mintemp, winddir, wind, weather]).T
data_spider.columns = index_ # 修改列名
data_spider.index = date # 修改索引
data = pd.concat((data,data_spider), axis=0) # 数据拼接
print('%s年%s月的数据抓取成功' % (y, m))
else:
print('%s年%s月的数据不存在' % (y, m))
break
data.to_excel('weatherdata.xlsx',)
print('爬取数据展示:\n', data)
代码附有详细注释,应该可以看的懂,如有问题请留言,其中可以通过调节年份,城市等获取你们想要的数据,该程序跑出结果如下图:

由于现在是2020年3月份,因此后面月份的数据不存在,每个url链接都是所需要的json数据。
我将数据保存到了Excel里,如下
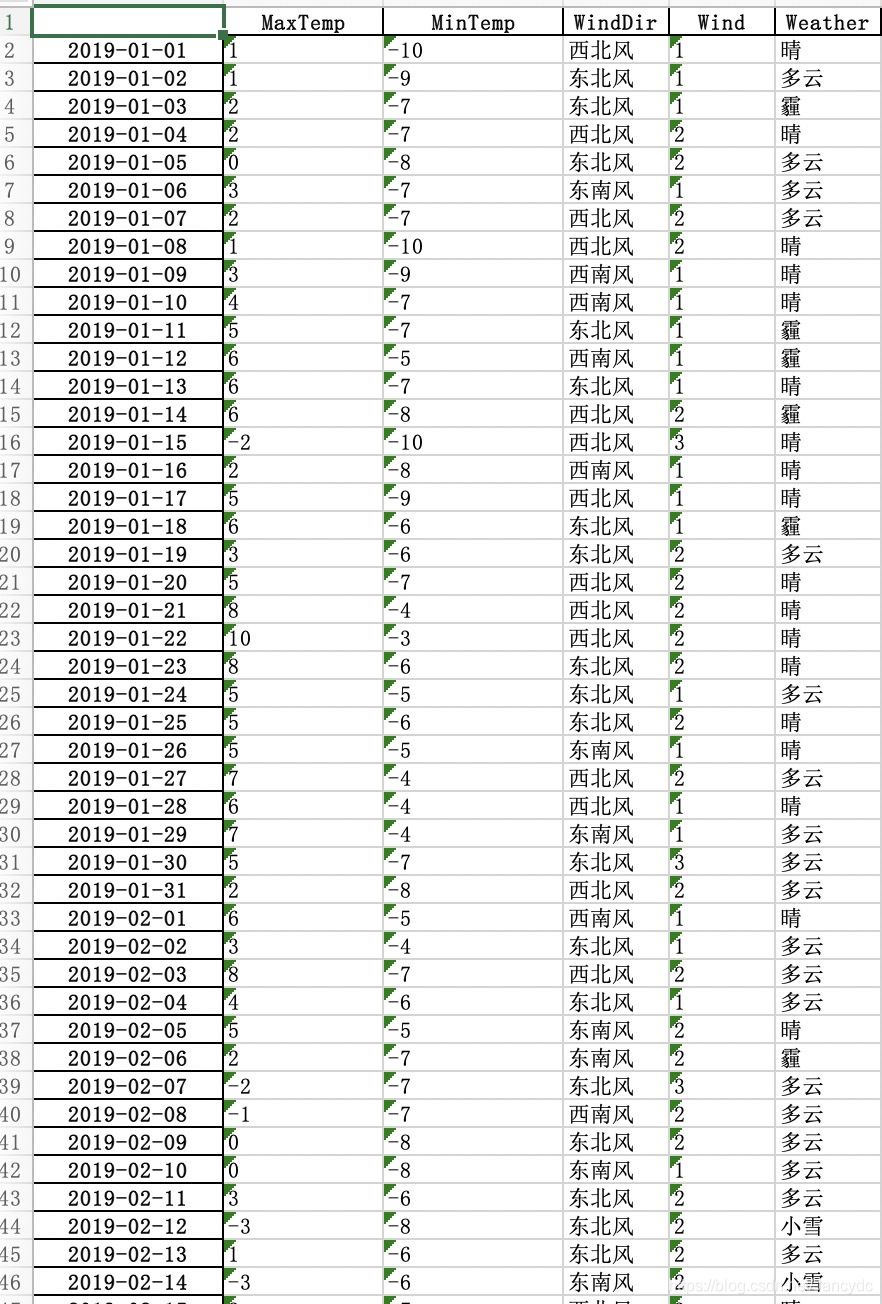
当然也可以将它放到数据库里都可以,具体点这里就不介绍了!觉得该博客有用的还希望点个赞支持一下!



















 713
713








 到【灌水乐园】发言
到【灌水乐园】发言









