




 本文简要介绍了HashMap,它是一张哈希表,非线程安全,适用于单线程环境。HashMap实现了Serializable接口,容量限制在2的30次方内,并自动调整为2的幂次方。其存储结构包括一个数组,每个数组元素连接一个单链表以处理哈希冲突。在HashMap中,put和get操作通过计算key的哈希值定位元素,get时找到key相等的键值对返回或插入新值;put时新键值对始终插入链表头部。当元素数量达到阈值时,HashMap会进行扩容。
本文简要介绍了HashMap,它是一张哈希表,非线程安全,适用于单线程环境。HashMap实现了Serializable接口,容量限制在2的30次方内,并自动调整为2的幂次方。其存储结构包括一个数组,每个数组元素连接一个单链表以处理哈希冲突。在HashMap中,put和get操作通过计算key的哈希值定位元素,get时找到key相等的键值对返回或插入新值;put时新键值对始终插入链表头部。当元素数量达到阈值时,HashMap会进行扩容。
- HashMap就是一张hash表,键和值都没有排序。
HashMap是非线程安全的,只用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
HashMap 实现了Serializable接口,因此它支持序列化。
HashMap 容量设为不小于指定容量的2的幂次方,且最大值不能超过2的30次方。
HashMap的存储结构
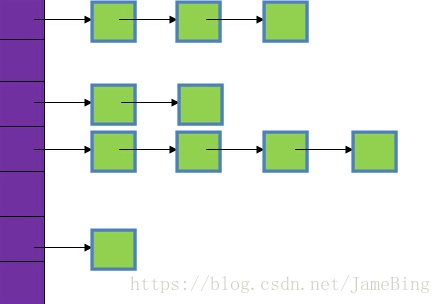
紫色部分即代表哈希表本身(其实是一个数组),数组的每个元素都是一个单链表的头节点,链表是用来解决hash地址冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中保存。
HashMap中put和get的源码:
- get方法源码
// 获取key对应的value
public V get(Object key) {
if (key == null)
return getForNullKey();
// 获取key的hash值
int hash = hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
// 判断key是否相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
// 没找到则返回null
return null;
}
// 获取“key为null”的元素的值,HashMap将“key为null”的元素存储在table[0]位置,但不一定是该链表的第一个位置
private V getForNullKey() {
for (Entry<K, V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
首先,如果key为null,则直接从哈希表的第一个位置table[0]对应的链表上查找。记住,key为null的键值对永远都放在
able[0]为头结点的链表中,当然不一定是存放在头结点table[0]中。如果key不为null,则先求的key的hash值,根据
hash值找到在table中的索引,在该索引对应的单链表中查找是否有键值对的key与目标key相等,有就返回对应的value,
没有则返回null。
- put方法源码
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
// 将key-value添加到table[i]处
addEntry(hash, key, value, i);
return null;
}
put方法源码
如果key为null,则将其添加到table[0]对应的链表中,如果key不为null,则同样先求出key的hash值,
根据hash值得出在table中的索引,而后遍历对应的单链表,如果单链表中存在与目标key相等的键值对,
则将新的value覆盖旧的value,且将旧的value返回,如果找不到与目标key相等的键值对,或者该单链表为空,
则将该键值对插入到单链表的头结点位置(每次新插入的节点都是放在头结点的位置),
该操作是有addEntry方法实现的,它的源码如下:
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K, V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K, V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}
注意这里倒数第三行的构造方法,将key-value键值对赋给table[bucketIndex],并将其next指向元素e,
这便将key-value放到了头结点中,并将之前的头结点接在了它的后面。该方法也说明,每次put键值对的时候
,总是将新的该键值对放在table[bucketIndex]处(即头结点处)。两外注意最后两行代码,每次加入键值对时
,都要判断当前已用的槽的数目是否大于等于阀值(容量*加载因子),如果大于等于,则进行扩容,将容量扩为
原来容量的2倍。

















 4万+
4万+




 到【灌水乐园】发言
到【灌水乐园】发言







